python数据库连接池设计
- 一.背景:
传统访问资源,一般分为一下几个步骤:
1.实例数据驱动对象与链接资源。2.实例操作资源游标。3.获取资源。4.关闭链接资源。
根据以上步骤,我们可以很简单使用这个原始方法来访问资源为我们业务逻辑所用。但是对于批量操作与频繁访问资源时,那么效率问题与系统压力将会严重影响我们的业务。可能没有什么概念,举个例子:你的业务需要访问数据库,当1个人操作时没有问题,5个人、10个人可能也没有问题,当是几百、上千去访问时,系统开销会什么样子呢?再如:访问数据库有几百个sql,上千个sql,每次都要重复1、2、4操作,系统开销是什么样子、产品效率问题什么情况?可想而知了【注:1、2两个步骤每次操作耗时在1s左右】
因此,有了 [缓冲池] 优化方案的提出。缓冲池个人理解是:能够动态管理数据库链接实例创建、使用与释放,让池内所有资源链接得到最大化使用。对于它的原理可以去深入了解。
- 二.使用python实现数据库缓冲池
数据库缓冲池,有这样一个图感觉很形象: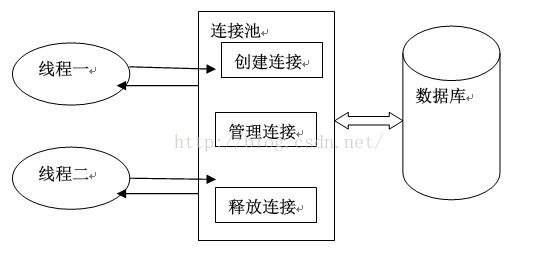
我们将比较耗时、系统开销大的步骤放在缓冲池。数据库链通过线程池来实现,也就是说在底层通过多线程创建了一个线程池,然后每个线程实现了一套数据库链接访问渠道。举个例子:数据库假如是一杯水,数据库缓冲池设置了10个线程链接实例比成10个吸管,那么想喝水你就要实例化这个线程池,然后可以选择任何一个或者多个吸管来喝水。而且这10个吸管是相互独立的。当然了你不用去关心这些共享吸管的安全性问题,很多第三方控件都已经多了很好的处理,如下:poolDB框架原理

下面介绍一个python版本的实例:
使用第三方模块DBUtils.PoolDB,url:https://pypi.python.org/pypi/DBUtils
原理、使用方法与api等链接页面介绍的很清楚,其中这里说明几个参数:

代码实例如下:https://github.com/xnchall/dbPool/blob/master/dbPool.py
重要提示:由于数据库连接池除了一些特殊业务以外使用私有链接,其余大多都是共享链接。因此在使用时要根据自己的业务规模与使用频率设置连接池的参数。测试发现,设置
mincached=X,maxcached=X,maxshared=X,maxconnections=X这些连接池属性参数时耗费的时间与X大小存在线性关系的,共享连接数在百级的创建连接池耗时在2.5s左右。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号