
python学习_列表
一、为什么需要列表
- 变量可以存储一个元素,而列表是一个"大容器",可以存储N多个元素,且元素可以是不同的类型,程序可以很方便的对这些数据进行整体操作
- 列表相当于其他语言中的数组
- 列表索引示意图:

二、列表的创建
- 列表使用中括号即可创建,列表中的不同元素之间使用英文的逗号进行分隔
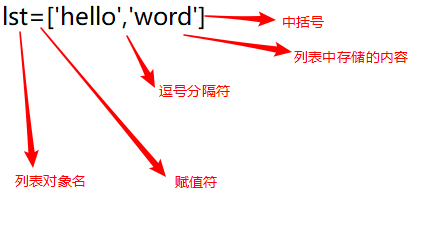
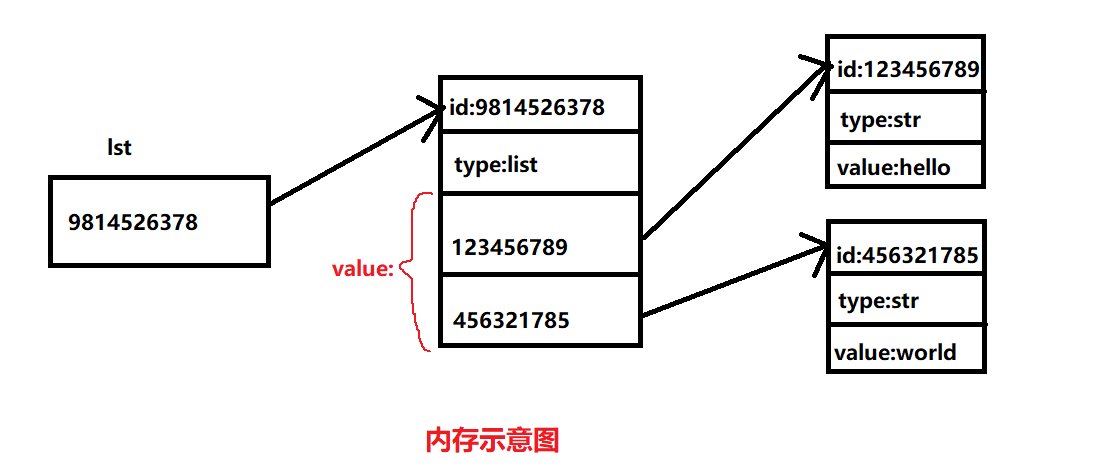
上面列表的内存示意图如下(列表中存储的是对象的引用):
- 列表的创建方式有两种:
1.使用中括号创建
l=[1,2,3,'hello']
2.使用内置函数list()创建
l=list([1,2,3,'hello']) #注意list()里面只能放一个参数,所以需要用中括号将所有元素括起来
三、列表的特点
- 列表元素是按顺序有序排序的
- 索引映射列表的唯一一个数据
- 列表可以存储重复数据
- 列表可以任意类型的数据混存
- 列表是根据需要动态分配和回收内存
四、列表的操作
- 切片
切片切出来的列表是一个不同于原列表的新列表
语法格式:
列表名[start:stop:step]
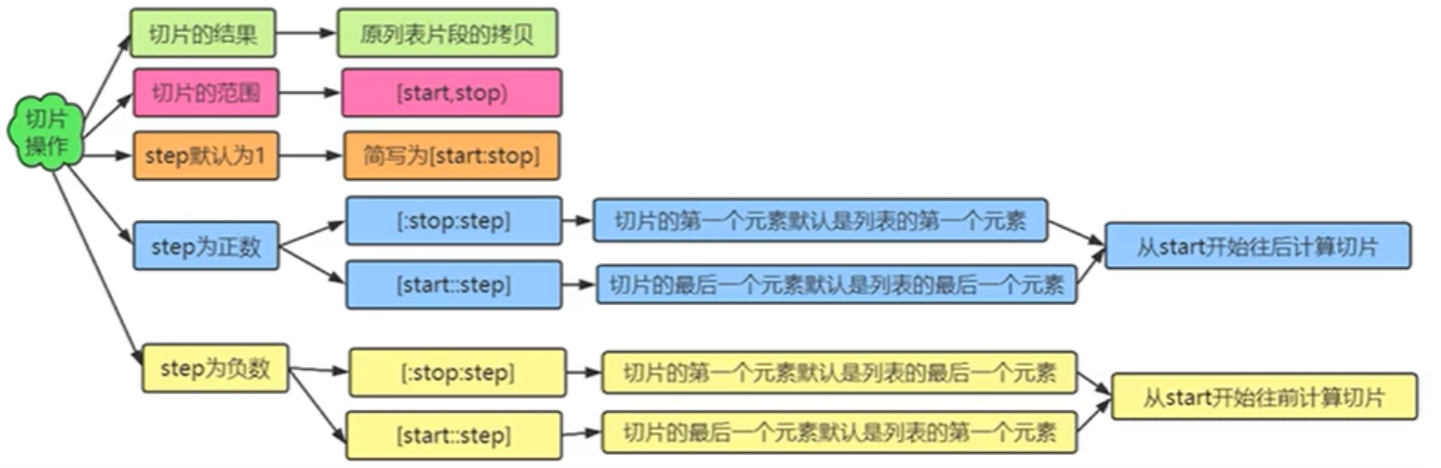
lst=[10,20,30,40,50,60,70,80] #start=1,stop=6,step=1 #print(lst[1:6:1]) print("原列表:",id(lst),type(lst)) lst2=lst[1:6:1] print("切片的片段",id(lst2),type(lst2)) #start=1,stop=6,step采用默认进行切片,注意:切面结果包括start,但不包括stop print(lst[1:6:]) #默认步长为1 print(lst[1:6]) #默认步长为1 #start=1,stop=6,step=2进行切片 print(lst[1:6:2]) #stop=6.step=2,start采用默认进行切面 print(lst[:6:2]) #start默认为0 #start=1.step=2,stop采用默认进行切面 print(lst[1::2]) #stop默认为最后 print("----------------步长step为负数的情况-------------") print(lst[::-1]) #start=7,stop省略,step=-1 print(lst[7::-1]) #start=6,stop=0,step=-1 print(lst[6:0:-2]) lst2=[1,25,3,'hello','world','python'] print(lst2[1:4]) #[25, 3, 'hello'],切片范围[1,4),包括1但是不包括4 print(lst2[:]) #[1, 25, 3, 'hello', 'world', 'python'] #step为正数 print(lst2[::2]) #[1, 3, 'world'] print(lst2[:4:2]) #[1, 3] print(lst2[1::2]) #[25, 'hello', 'python'] print(lst2[1:5:2]) #[25, 'hello'] #step为负数 print(lst2[::-1]) #['python', 'world', 'hello', 3, 25, 1] print(lst2[5:3:-1]) #['python', 'world'] print(lst2[:1:-2]) #['python', 'hello'] print(lst2[5::-2]) #['python', 'hello', 25]
- 查

lst=["hello","world",98,"hello",'花木兰'] #获取列表中的单个元素 print('''------------正向索引获取列表单个元素--------------''') print(lst[0]) #hello 获取列表第一个元素 print(lst[len(lst)-1]) #花木兰 获取列表最后一个索引 print('''------------逆向索引获取列表单个元素--------------''') print(lst[-1]) #花木兰 获取列表最后一个元素 print(lst[-len(lst)]) #hello,获取列表第一个元素 #print(lst[len(lst)]) #索引不存在报错,IndexError: list index out of range #切片:获取列表中多个元素 print(lst[0:3]) #['hello', 'world', 98],获取索引从0到2的列表元素,不包括索引为3的元素 print(lst[1:3]) #['world', 98],获取索引从1到2的列表元素 print(lst[:]) #['hello', 'world', 98, 'hello', '花木兰'] 获取整个列表 print(lst[:4]) #['hello', 'world', 98, 'hello'],获取索引从0到3的列表元素,不包括索引为4的元素 print(lst[1:]) #['world', 98, 'hello', '花木兰'],获取索引从1开始到最后的列表元素 print(lst[::2]) #['hello', 98, '花木兰'],从索引为0开始到最后一个元素,索引步长为2取值,也就是获取索引为0,2,4的元素 print(lst[1::2]) #['world', 'hello'],获取索引为1,3的元素 print(lst[::-2]) #['花木兰', 98, 'hello'],当step为负数时,切片的第一个元素默认是列表的最后一个元素 ,最后一个元素是列表的第一个元素 print(lst[3:0:-2]) #["hello","world"],获取索引为3,1的元素 print(lst[4::-1]) #['花木兰', 'hello', 98, 'world', 'hello'] print(lst[:1:-1]) #['花木兰', 'hello', 98],获取索引为4,3,2的元素 #统计列表中指定元素出现次数 print(lst.count("hello")) #2 #获取列表中指定元素的索引 print(lst.index('花木兰')) #4 print(lst.index("hello")) #0 如果列表中有相同元素,只返回相同元素中第一个元素的索引 print(lst.index("hello",1,4)) #3 在指定的索引范围[start,stop)内查找'hello',包括start不包括stop
- 增

lst=[10,20,30] #列表末尾添加一个元素 lst.append(40) print(lst) #[10, 20, 30, 40] lst.append('hahah') print(lst) #[10, 20, 30, 40, 'hahah'] lst2=['hello','world'] lst.append(lst2) print(lst) #[10, 20, 30, 40, 'hahah', ['hello', 'world']],将列表lst2作为一个元素添加到lst列表末尾 lst=[10,20,30] lst1=['hello','china'] #列表末尾添加至少一个元素 lst.extend(lst1) print(lst) #[10, 20, 30, 'hello', 'china'],向列表lst末尾一次性添加多个元素 lst=[10,20,30] #在任意位置添加一个元素 lst.insert(1,90) #向列表lst索引为1的位置添加元素90 print(lst) #[10,90,20,30] #在列表任意位置添加多个元素 lst=[10,20,30] lst3=[True,False] lst[len(lst):]=[40,50] #列表末尾添加多个元素 print(lst) #[10,20,30,40,50] lst[1::]=lst3 #相当于切片出来的片段用新的列表代替 print(lst) #[10,True,False]
- 删:

#原列表 lst=[10,20,30,40,50,60,30] print(lst) #[10,20,30,40,50,60,30] #remove():从列表中删除一个元素:如果有重复元素只删除第一个 lst.remove(30) #从列表中移除一个元素,如果有重复元素只移除第一个30 print(lst) #[10, 20, 40, 50, 60, 30] #pop()根据索引删除列表中的一个元素并返回删除的元素 del_value=lst.pop(1) #移除列表lst中索引为1的元素并将他返回 print(del_value) #20 print(lst) #[10, 40, 50, 60, 30] lst.pop() #pop()如果没有指定索引,删除列表lst中最后一个元素 print(lst) #[10, 40, 50, 60] #切片:删除至少一个元素,将产生一个新的列表对象 new_lst=lst[1:3] print("原列表:",lst) #[10, 40, 50, 60] print("切片后的列表",new_lst) #[40, 50],这样就相当于删除了列表中的元素10和60 #切片:删除至少一个元素,不产生新的列表对象 lst[1:3]=[] #将需要删除的部分用空列表替换 print(lst) #[10,60],相当于删除了列表元素40和50 #clear:清除列表中的所有元素 lst.clear() print(lst) #[] lst=[1,2,3,4] del lst[:] #del lst[:]相当于lst.clear() print(lst) #[] #delete:删除列表对象 del lst #print(lst) #NameError: name 'lst' is not defined,列表对象都被删除了,对象不存在。所以报错
- 改:

lst=[10,20,30,40] #一次修改一个元素 lst[2]='hello' print(lst) #[10,20,'hello',40] #切片:修改多个元素 lst[1:3]=[100,300,500,600] print(lst) #[10,100,300,500,600,40]
- 列表元素排序:

lst=[20,40,10,98,54] #使用sort()函数对列表元素进行排序 lst.sort() #将列表lst从小到大排序 print(lst) #[10, 20, 40, 54, 98] lst.sort(reverse=True) #将列表lst从大到小排序 print(lst) #[98, 54, 40, 20, 10] #使用内置函数sorted()对列表进行排序,将产生一个新的排好序的列表对象 lst=[20,40,10,98,54] new_lst=sorted(lst) #将lst列表元素从小到大排序 print(lst,id(lst)) #[20, 40, 10, 98, 54] 1314504576456 print(new_lst,id(new_lst)) #[10, 20, 40, 54, 98] 1314504073864 #reverse()对列表元素进行原地反转 heros=['花木兰','穆桂英','梁红玉','佘赛花','樊梨花'] heros.reverse() #将列表元素反转 print(heros) #['樊梨花', '佘赛花', '梁红玉', '穆桂英', '花木兰'] lst=[20,40,10,98,54] lst.reverse() print(lst) #[54, 98, 10, 40, 20]
- 列表的拷贝
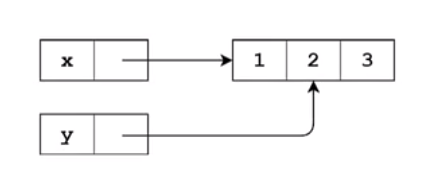
方法1:通过变量的赋值操作来复制列表,这种方式拷贝的只是变量的引用,实际还是指向的同一个列表对象
x=[1,2,3] #方法1:使用变量赋值操作来赋值列表,这种方法拷贝的只是对象的引用 y=x #这种方法lst1和lst都指向同一个列表对象 print(y) #[1, 2, 3] print(id(x)) #2116597342856 print(id(y)) #2116597342856 x[1]=1 print(x) #[1, 1, 3] print(y) #[1, 1, 3],改变x列表的值,y列表也对应改变,因为他们引用的是一个列表对象
内存示意图如下:
方法2:使用列表的拷贝方法copy()进行拷贝,这种方法拷贝的是整个列表对象,而不仅仅是变量的引用
#列表的copy()方法拷贝列表,拷贝的是整个列表对象 x=[1,2,3] y=x.copy() print(x,id(x)) #[1, 2, 3] 1899622720136 print(y,id(y)) #[1, 2, 3] 1899622720200 x[1]=1 print(x) #[1, 1, 3] print(y) #[1, 2, 3],x列表元素的修改不会影响y列表
#copy模块的copy()函数进行拷贝,拷贝的是整个列表对象
import copy
x=[1,2,3]
y=copy.copy(x)
print(x,id(x)) #[1, 2, 3] 2290567413320
print(y,id(y)) #[1, 2, 3] 2290565210760
x[1]=1
print(x) #[1, 1, 3]
print(y) #[1, 2, 3]
内存示意图如下:

方法3:使用列表的切片进行拷贝,这种方法拷贝的是整个列表对象,而不是变量的引用
#方法3:切片方法拷贝列表 lst=[1,2,3] lst2=lst[:] print(lst,id(lst)) #[1, 2, 3] 1899623942280 print(lst2,id(lst2)) #[1, 2, 3] 1899622720136 lst[1]=1 print(lst) #[1, 1, 3] print(lst2) #[1, 2, 3],源列表的拷贝不会影响拷贝列表
注意:一层列表的拷贝可以用列表的copy()方法、切片方法以及copy模块的copy()函数,这三个都是浅拷贝
但如果涉及到嵌套列表,要达到原列表与拷贝列表相互独立这方法就不行了,如下案例
x=[[1,2,3],[4,5,6],[7,8,9]] #嵌套列表copy()方法拷贝后拷贝的是对列表的引用 y=x.copy() x[1][1]=0 print(x) #[[1, 2, 3], [4, 0, 6], [7, 8, 9]] print(y) #[[1, 2, 3], [4, 0, 6], [7, 8, 9]],修改x列表,y列表也改变了,因为他们的嵌套列表对象拷贝的只是对象的引用
因为浅拷贝只是拷贝外层对象,对于嵌套对象的话浅拷贝只是拷贝对嵌套对象的引用,内存图如下:
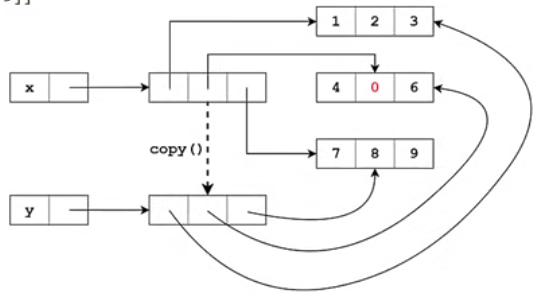
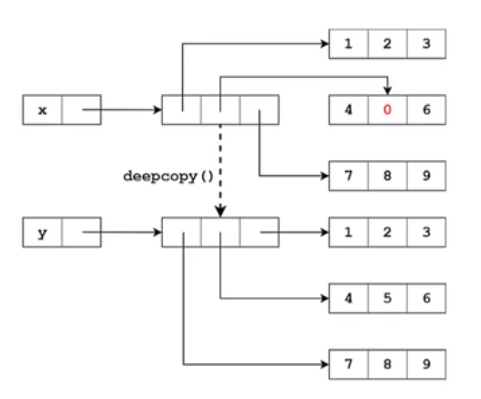
要实现嵌套对象也拷贝需要用到深拷贝,深拷贝用的是copy模块的deepcopy()方法,deepcopy()函数在将原对象拷贝的同时也将对象中所有引用的子对象一并进行拷贝,如果是多层嵌套,深拷贝也会全部拷贝每一层嵌套里面的数据
import copy x=[[1,2,3],[4,5,6],[7,8,9]] y=copy.deepcopy(lst) x[1][1]=0 print(x) #[[1, 2, 3], [4, 0, 6], [7, 8, 9]] print(y) #[[1, 2, 3], [4, 5, 6], [7, 8, 9]],x与y列表相互独立,修改x列表不影响y
内存示意图:
- 列表的计算
#列表的数学运算 l=[1,2,3,4] s=['hello','python','world'] #列表的+运算:就是将两个列表的元素放在一个列表中 print(l+s) #[1, 2, 3, 4, 'hello', 'python', 'world'] #列表的*运算:就是将列表中的元素复制多少次 print(l*3) #[1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4] print(s*2) #['hello', 'python', 'world', 'hello', 'python', 'world']
- 判断指定元素在列表中是否存在:

#判断指定元素在列表中是否存在 heros=['花木兰','穆桂英','梁红玉','佘赛花','樊梨花'] print('花木兰' in heros) #True print('张三' not in heros) #True
- 列表元素的遍历

for item in heros: print(item) #花木兰 #穆桂英 #梁红玉 #佘赛花 #樊梨花
五、嵌套列表:
嵌套列表就是在列表中嵌入一个新的列表,也叫二维列表
- 创建二维列表:
#方法1:通过每个元素的值创建二维列表 lst=[[1,2,3], [4,5,6], [7,8,9]] print(lst) #[[1, 2, 3], [4, 5, 6], [7, 8, 9]] #方法2:通过循环创建并初始化二维列表 A=[0]*3 #print(A) #[0, 0, 0] for i in range(3): A[i]=[0]*4 print(A) ##[[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]] A[1][1]=2 print(A) #[[0, 0, 0, 0], [0, 2, 0, 0], [0, 0, 0, 0]]
- 嵌套列表的访问:
1)迭代嵌套列表:迭代列表的时候我们使用一层循环就可以,迭代嵌套列表的话就需要使用嵌套循环(也就是双层循环)
lst=[[1,2,3], [4,5,6], [7,8,9]] print(lst) #[[1, 2, 3], [4, 5, 6], [7, 8, 9]] for i in lst: for each in i: print(each,end=' ') print() ''' 输出结果为: 1 2 3 4 5 6 7 8 9 '''
2)通过索引下标访问嵌套列表:
matrix=[[1,2,3], [4,5,6], [7,8,9]] print(matrix[0]) #[1, 2, 3] print(matrix[0][0]) #1 print(matrix[0][1]) #2 print(matrix[1][1]) #5 print(matrix[2][2]) #9
六、列表推导式(列表生成式):
列表推导式其实就是生成列表的公式
语法格式:
[生成列表元素的表达式 for 自定义变量 in 可迭代对象] #生成一个0~9的整数列表 x=[i for i in range(10)] print(x) #[0, 1, 2, 3, 4, 5, 6, 7, 8, 9] #生成一个偶数列表 x1=[ i*2 for i in range(10)] print(x1) #[0, 2, 4, 6, 8, 10, 12, 14, 16, 18] #将字符串中每一个字符都成重复一边保存为列表 y=[i*2 for i in 'hello'] print(y) #['hh', 'ee', 'll', 'll', 'oo'] #将字符串每一个字符转换成unicode编码保存为列表 y1=[ord(i) for i in 'hello'] print(y1) #[104, 101, 108, 108, 111] matrix=[[1,2,3], [4,5,6], [7,8,9]] #通过列表推导式获取矩阵第二列的元素 col2= [row[1] for row in matrix] print(col2) #[2, 5, 8] #通过列表推导式获取矩阵对角线上的元素 diag1=[matrix[i][i] for i in range(len(matrix))] print(diag1) #[1, 5, 9] diag2=[matrix[i][len(matrix)-i-1] for i in range(len(matrix))] print(diag2) #[3, 5, 7] #列表推导式生成嵌套列表 S=[[0]*3 for i in range(3)] #注意[0]*3的结果为[0,0,0] print(S) #[[0, 0, 0], [0, 0, 0], [0, 0, 0]] S[1][1]=1 print(S) #[[0, 0, 0], [0, 1, 0], [0, 0, 0]]
列表推导式的高阶语法
[生成列表元素的表达式 for 自定义变量 in 可迭代对象 if 条件表达式] #执行顺序:先执行for语句,然后if条件表达式,最后执行生成列表元素的表达式 words=['Great','Fish','Good','Brilliant','Fantistic','Excellent'] #列表推导式筛选出以F开头的字符串 result=[i for i in words if i[0]=='F'] print(result) #['Fish', 'Fantistic']
列表推导式的嵌套
语法格式
[生成列表元素的表达式 for 自定义变量1 in 可迭代对象1 for 自定义变量2 in 可迭代对象2 .... for 自定义变量n in 可迭代对象N] #列表推导式:将二维列表降级为一维列表 matrix=[[1,2,3],[4,5,6],[7,8,9]] flatten=[col for row in matrix for col in row] print(flatten) #[1, 2, 3, 4, 5, 6, 7, 8, 9] ''' #将二维列表降级为一维列表循环写法 flatten=[] matrix=[[1,2,3],[4,5,6],[7,8,9]] for row in matrix: for col in row: flatten.append(col) print(flatten) #[1, 2, 3, 4, 5, 6, 7, 8, 9] ''' r=[x+y for x in 'fishc' for y in 'FISHC'] print(r) #['fF', 'fI', 'fS', 'fH', 'fC', 'iF', 'iI', 'iS', 'iH', 'iC', 'sF', 'sI', 'sS', 'sH', 'sC', 'hF', 'hI', 'hS', 'hH', 'hC', 'cF', 'cI', 'cS', 'cH', 'cC']
列表推导式的终极语法:
[生成列表元素的表达式 for 自定义变量1 in 可迭代对象1 if 条件1 for 自定义变量2 in 可迭代对象2 if 条件2 ... for 自定义变量n in 可迭代对象n if 条件n] #列表推导式 r=[[x,y] for x in range(10) if x%2==0 for y in range(10) if y%3==0] print(r) #[[0, 0], [0, 3], [0, 6], [0, 9], [2, 0], [2, 3], [2, 6], [2, 9], [4, 0], [4, 3], [4, 6], [4, 9], [6, 0], [6, 3], [6, 6], [6, 9], [8, 0], [8, 3], [8, 6], [8, 9]] #转换成for循环的写法 lst=[] for x in range(10): if x%2==0: for y in range(10): if y%3==0: lst.append([x,y]) print(lst) #[[0, 0], [0, 3], [0, 6], [0, 9], [2, 0], [2, 3], [2, 6], [2, 9], [4, 0], [4, 3], [4, 6], [4, 9], [6, 0], [6, 3], [6, 6], [6, 9], [8, 0], [8, 3], [8, 6], [8, 9]]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号