python学习_二进制与字符编码
一、计算机如何能认识输入的内容?
计算机是由逻辑电路所组成的,逻辑电路就只有两种状态,开和关,这两种状态正好可以用0和1来表示,如下图
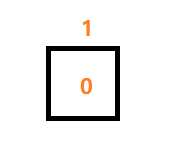
一个位置有0和1两种状态,如果想要表示更多的状态,则需要增加位数(bit),那需要增加多少位数呢?最初计算机是美国人约翰·冯·诺依曼发明的,因为他们常用字符128个,一个位置表示2种状态,2个位置表示4种状态,7个位置,表示128状态,8个位置表示256中状态,256中状态就可以对应256个符号,所以就将位数设置在8位,也叫8 bit,前面(0-127)128个表示他们常用符号,后面128预留给其他国家用
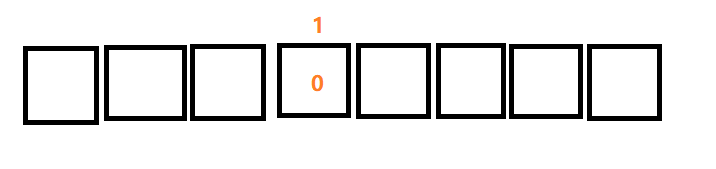
这个比特(bit)是计算机中最小的存储单元,他与其他单位换算关系如下:
8 bit(比特)=1 bytes(字节)
1024 bytes=1 KB(千字节)
1024 KB=1 MB(兆字节)
1024 MB=1 GB(吉字节)
1024 GB=1 TB(太字节)
二、字符编码
为了让计算机能认识常用的符号,有人就将这些符号和计算机认识的二进制数字以及10进制数字对应起来,做成了一张表,叫ASCII码表,在ASCII码表中一个符号用8位(也就是一个字节)来表示,如下图
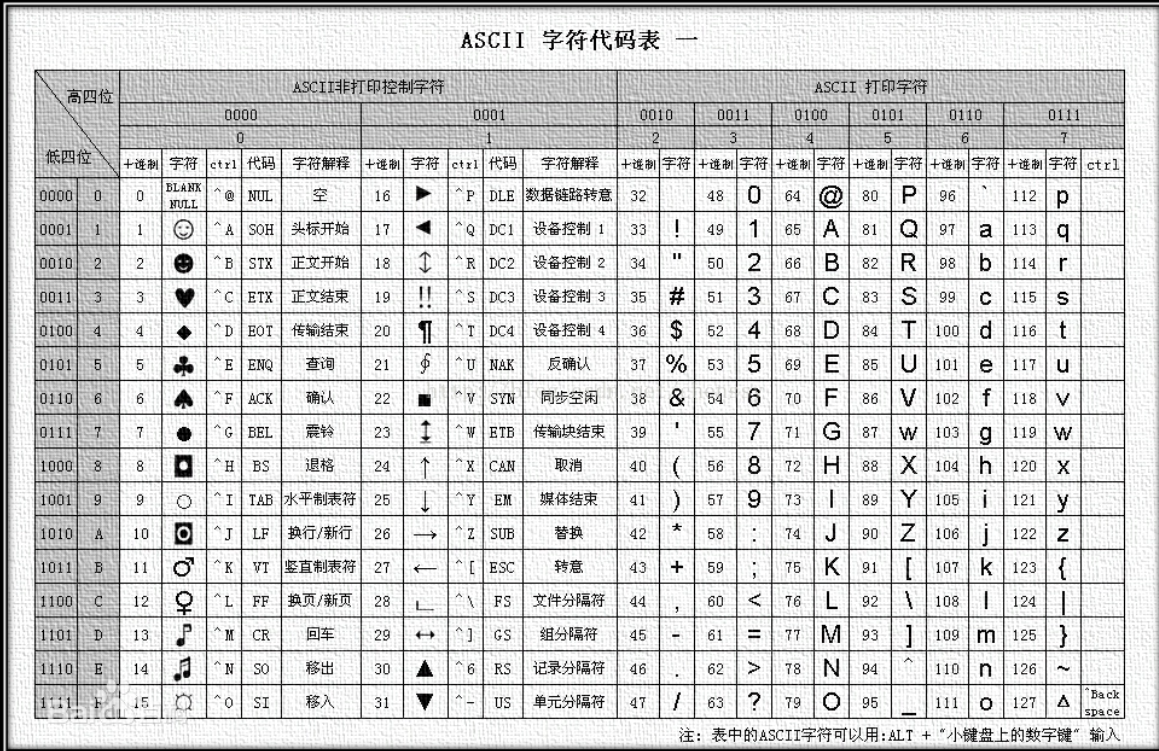
如上图,可以看到大写的字母A,它对应的十进制数为65,二进制为01000001
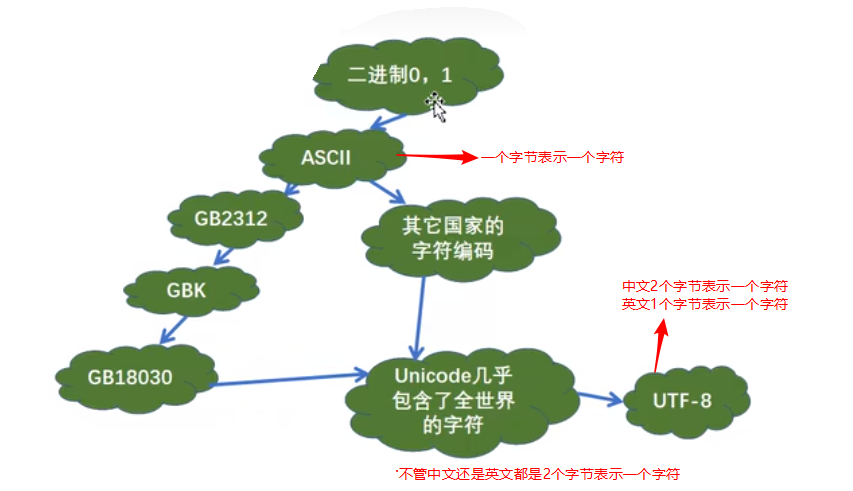
ASCII码表中剩下的128个字符要给其他国家用,明显是不够的,就只给中国用都是不够的,于是1980,我们中国又推出了一个GB2312的编码,这个编码主要是我们的简体中文字符集,可以表示7445个简体中文字符,在1995年又推出了GBK编码,用来表示简体中文和繁体中文字符,2000年又推出了GB18030编码,可以表示27484个字符,包括简体中文、繁体中文和少数名族字符,同时这个编码里面每个字符可以由1个、2个或者4个字节组成,这样每个国家都有每个国家的编码,这样就会导致同样一个符号中文编码表中表示的数字与外国编码表的数字不一样,造成计算机识别混乱,怎么办呢?这个时候就需要统一一个编码,于是出现了Unicode编码(万国码),Unicode里面规定每个字符都使用2个字节表示,但是后面又发现英文字符使用2个字节太占空间,于是又出现了UTF-8编码(可变长的编码),这个编码中规定英文用1个字节表示,中文用3个字节表示,一个中文或者一个英文都叫一个字符。
字符编码发展历程:
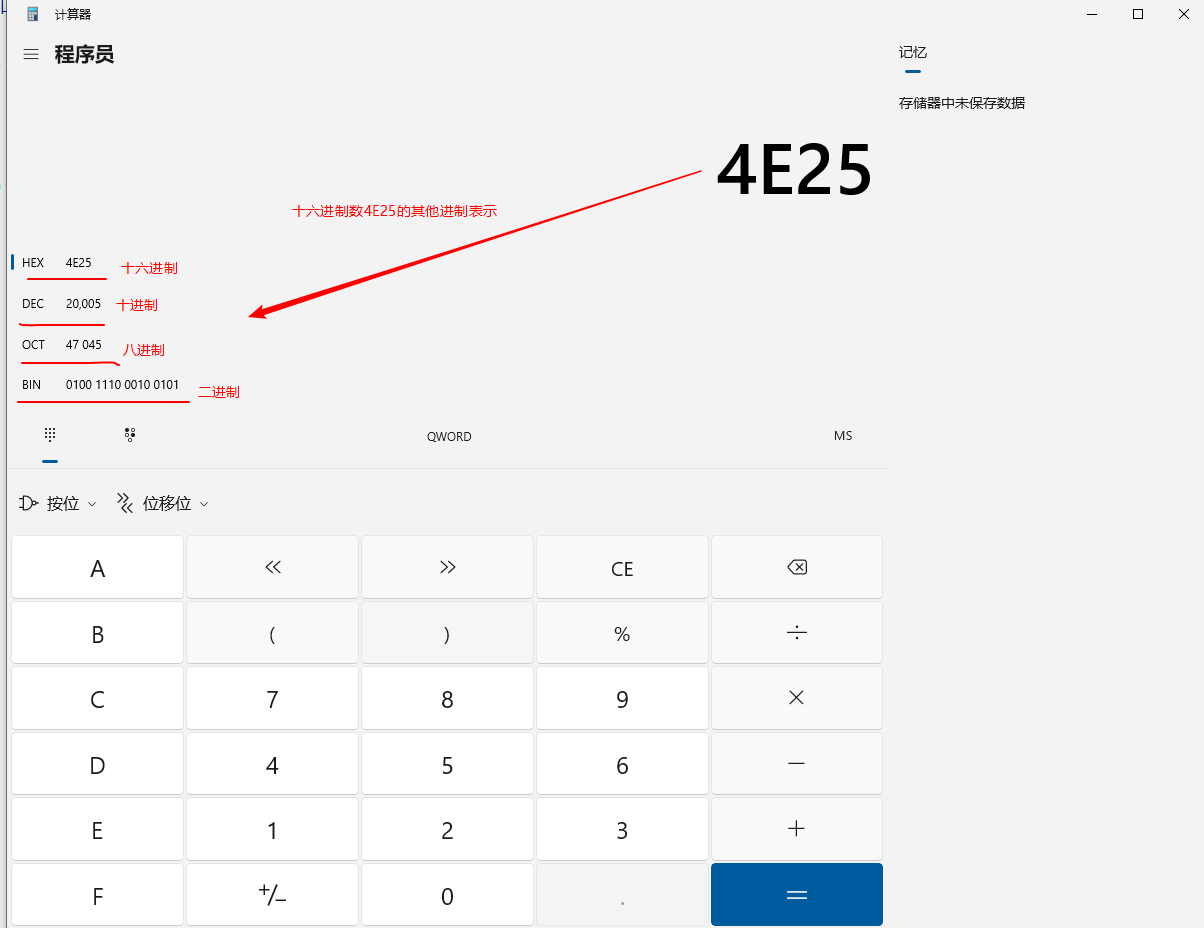
根据对应编码就可以找到对应字符,通过查unicode汉字编码表知道中文'严'的十六进制编码为4E25,他对应的其他编码分别为:
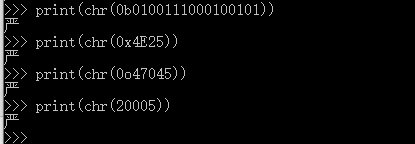
我们可以通过chr()函数输出编码对应的字符
print(chr(0b0100111000100101)) #0b表示二进制 print(chr(0x4E25)) #0x表示十六进制 print(chr(0o47045)) #0o表示八进制 print(chr(20005))
chr(i)函数:返回i对应的字符,其中i可以是十进制,也可以是八进制、二进制或者十六进制,计算机最终都会转化为二进制
ord(str):返回字符串对应的十进制数
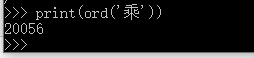
我们也可以通过ord()函数查看某个字符的对应十进制编码
print(ord('乘'))
通过进制转换我们可以看到'乘'对应的十六进制为4E58
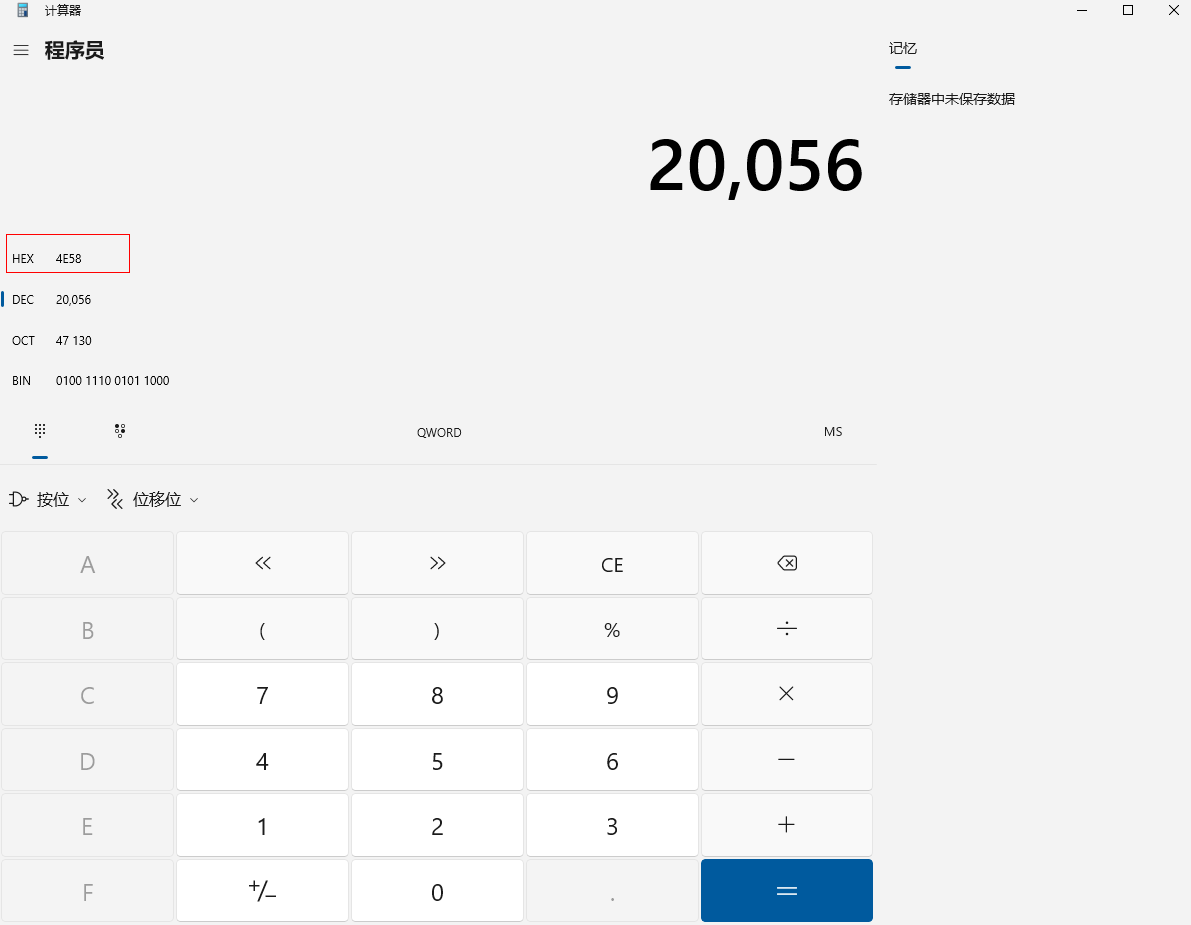
我们再来看unicode编码中'乘'的十六进制编码是不是这个


 浙公网安备 33010602011771号
浙公网安备 33010602011771号