
线程和进程
一、概念
线程:线程就是一个指令集合,是操作系统能够进行运算调度的最小单位,他被包含在进程之中,是进程中的实际运作单位,线程之间资源可以共享
进程:进程就是对一些资源的整合,一个进程可以有多个线程,进程之间资源不可以共享,进程之间是独立
GIL:全局解释器锁,就是在python中同一时刻,只能有一个线程被解释器CPython执行
线程与进程的区别:
1.python中可以有多线程,也可以有多进程,在多进程中,子进程是完全复制的主进程的,所以多进程的资源消耗比多线程要大很多
2.线程资源、数据都是共享的,进程之间资源、数据都是独立的
3.主线程可以影响子线程,但是主进程不会影响子进程
注:线程和进程一样块(线程在执行时,等于进程,同一个体系)
二、python多线程运行过程:
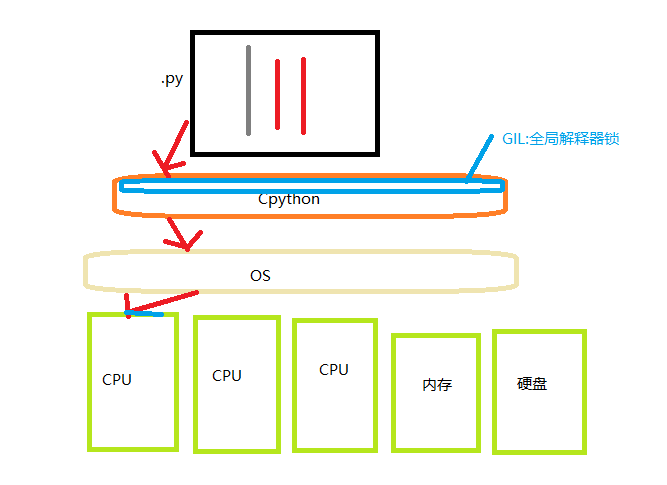
python多线程过程:多个任务同时交给cpu进行处理,cpu会先执行一个任务一小段时间,之后转到另一个任务在执行一小段时间(很短很短的时间),这个很短的时候看不出来差异,所以表面上看起来像是一起执行,实际其实就是一个多个线程(并发)在竞争资源的过程,这种其实就叫多线程的并发运行,所以Python中的多线程并不是并行执行,而是并发运行,也就是“交替执行”
交替切换线程有两种方式:
1)规定的一个很短的执行时间来切换线程
2)遇到I/O阻塞,如sleep(),他的效果就是类型I/O阻塞,当cpu执行某个线程,时间还没到规定的那个很短时间,但是碰到了sleep语句,cpu就会切换到另一个线程
python要真正的多线程并行运行是没办法的
而且通过这个图发现,python由于在cpython解释器上有一个GIL,在同一时刻,只能有一个线程进入Cpython解释器执行,所以即使计算机存在多核,python的多线程也没办法像真正的并行运行一样,使用多核来进行并行,这个是cpython解释器的一个历史问题
如果要使用到多核,可以考虑用多进程的方法或者使用其他语言,其他语言如C就没有GIL这个问题
三、多线程处理任务:
1、任务类型:
1)IO密集型任务函数:是指磁盘IO、网络IO占主要的任务,计算量很小, 就是函数里面有IO阻塞,比如请求网页、读写文件等。阻塞时CPU处于空闲状态,此时其他线程可使用cpu, Python中可以利用sleep达到IO密集型任务的目的
2)计算密集型任务函数:指CPU计算占主要的任务,CPU一直处于满负荷状态。如复杂的加减乘除等
2.示例
下面我们看下使用多线程处理IO密集型任务和计算密集型任务情况:
1)多线程下处理IO密集型任务
普通串行:
def foo(n):
print("foo %s" % n)
time.sleep(2)
print("end foo")
def bar(b):
print("bar %s" % b)
time.sleep(1)
print("end bar")
foo(2)
bar(1)
多线程处理IO密集任务:
import threading
import time
start=time.time()
def foo(n):
print("foo %s" % n)
time.sleep(2)
print("end foo")
def bar(b):
print("bar %s" % b)
time.sleep(1)
print("end bar")
t1=threading.Thread(target=foo,args=(2,))
t2=threading.Thread(target=bar,args=(1,))
t1.start() #执行子线程t1
t2.start() #执行子线程t2
print("this is main")
t1.join() #t1进程执行完成后才往下走,未执行完不往下走
t2.join() #t2进程执行完成后才往下走,未执行完不往下走
end=time.time()
print("spend time %s" %(end-start))
2)多线程处理计算密集型任务
普通串行:
begin=time.time()
def adds(n):
suma=0
for i in range(n):
suma+=i
print(suma)
adds(100000000)
adds(100000000)
endtime=time.time()
print(endtime-begin)
线程并发运行:
import threading
import time
begin=time.time()
def adds(n):
suma=0
for i in range(n):
suma+=i
print(suma)
t1=threading.Thread(target=adds,args=(100000000,))
t2=threading.Thread(target=adds,args=(100000000,))
t1.start()
t2.start()
t1.join()
t2.join()
endtime=time.time()
print(endtime-begin)
从两段脚本可以看出,在python2.7里面,处理IO密集任务时,多线程耗时比普通串行要少,而处理计算密集型任务时,多线程并发运行花费的时间比普通的串行运行还要久,这主要的原因还是在adds这个函数,这个函数他没有任何IO阻塞,所以两个线程的运行只能通过固定的一小段时间进行切换进行,实际和两个adds串行是一样的,同时切换线程还要消耗时间,所以线程并发运行实际耗费的时间比普通的串行运行还要久。
所以,在python里面,处理IO密集型任务时可以用多线程,如果处理的是计算密集型任务则使用多进程或者用其他语言的多线程(如C语言的多线程)
为什么呢?
这是因为python有GIL(全局解释锁)的原因,导致同一时刻只能有一个线程在使用cpu,所以即使计算机有多个CPU,在处理计算密集型任务时多线程并不能真的提高速度,反而会变慢,但是其他语言就没有这个GIL的问题,所以可以用多个CPU进行真的并行
四、一个简单的多线程处理IO密集型任务示例:
import threading
import time
def music(name):
for i in range(2):
print("start listen music %s,time: %s" % (name,time.ctime()))
time.sleep(1)
print("end listen music,time:%s"%time.ctime())
def movie(name):
for i in range(2):
print("start watch movie %s,time: %s" % (name,time.ctime()))
time.sleep(5)
print("end watch movie,time:%s"%time.ctime())
threads=[]
t1=threading.Thread(target=music,args=("七里香",))
threads.append(t1)
t2=threading.Thread(target=movie,args=("白夜追凶",))
threads.append(t2)
if __name__=="__main__":
# music("七里香")
# movie("白夜追凶")
for t in threads:
t.start()
print("all over %s"%time.ctime())
五、主要参数
1、join():线程同步,即主线程执行完成后进入阻塞状态,一直等待其他的子线程(谁调用的就等谁)执行结束之后,主线程在终止,在子线程运行完成之前,这个子线程的父线程一直被阻塞
import threading
import time
def music(name):
for i in range(2):
print("start listen music %s,time: %s" % (name,time.ctime()))
time.sleep(1)
print("end listen music,time:%s"%time.ctime())
def movie(name):
for i in range(2):
print("start watch movie %s,time: %s" % (name,time.ctime()))
time.sleep(5)
print("end watch movie,time:%s"%time.ctime())
threads=[]
t1=threading.Thread(target=music,args=("七里香",))
threads.append(t1)
t2=threading.Thread(target=movie,args=("白夜追凶",))
threads.append(t2)
if __name__=="__main__":
# music("七里香")
# movie("白夜追凶")
for t in threads:
t.start()
t.join() #此时t=t2
print("all over %s"%time.ctime())
2.setDaemon(True):守护线程,一般多线程运行时主线程运行完成后还会等子线程,之后程序才会结束,如果设置了线程守护,则表示哪个线程调用了setDaemon(True),这个程序除调用的线程外的其他线程运行结束后程序就结束,不会等待这个线程的运行结果
import threading
import time
def music(name):
for i in range(2):
print("start listen music %s,time: %s" % (name,time.ctime()))
time.sleep(1)
print("end listen music,time:%s"%time.ctime())
def movie(name):
for i in range(2):
print("start watch movie %s,time: %s" % (name,time.ctime()))
time.sleep(5)
print("end watch movie,time:%s"%time.ctime())
threads=[]
t1=threading.Thread(target=music,args=("七里香",))
threads.append(t1)
t2=threading.Thread(target=movie,args=("白夜追凶",))
threads.append(t2)
if __name__=="__main__":
# music("七里香")
# movie("白夜追凶")
for t in threads:
t.setDaemon(True) #设置了线程守护,所以只要主线程运行完后程序就会结束
t.start()
print("all over %s"%time.ctime())
3.threading.current_thread():获取到当前执行的线程信息
4.threading.active_count():获取当前仍激活线程数量
import threading
import time
def music(name):
for i in range(2):
print("start listen music %s,time: %s" % (name,time.ctime()))
time.sleep(1)#sleep状态不占cpu,也就是cpu不工作
print("end listen music,time:%s"%time.ctime())
def movie(name):
for i in range(2):
print("start watch movie %s,time: %s" % (name,time.ctime()))
time.sleep(5)#sleep状态不占cpu,也就是cpu不工作
print("end watch movie,time:%s"%time.ctime())
threads=[]
t1=threading.Thread(target=music,args=("七里香",))
threads.append(t1)
t2=threading.Thread(target=movie,args=("白夜追凶",))
threads.append(t2)
if __name__=="__main__":
# music("七里香")
# movie("白夜追凶")
for t in threads:
t.setDaemon(True)
t.start()
t.join() #此时t=t2
print(threading.active_count()) #此时结果为1,因为这个时候子线程都已经结束了,如果没有t.join(),则结果为3,,因为三个线程都还在
print("all over %s"%time.ctime())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号