Redis 核心技术与实战-基础知识
Redis 核心技术与实战基础知识笔记
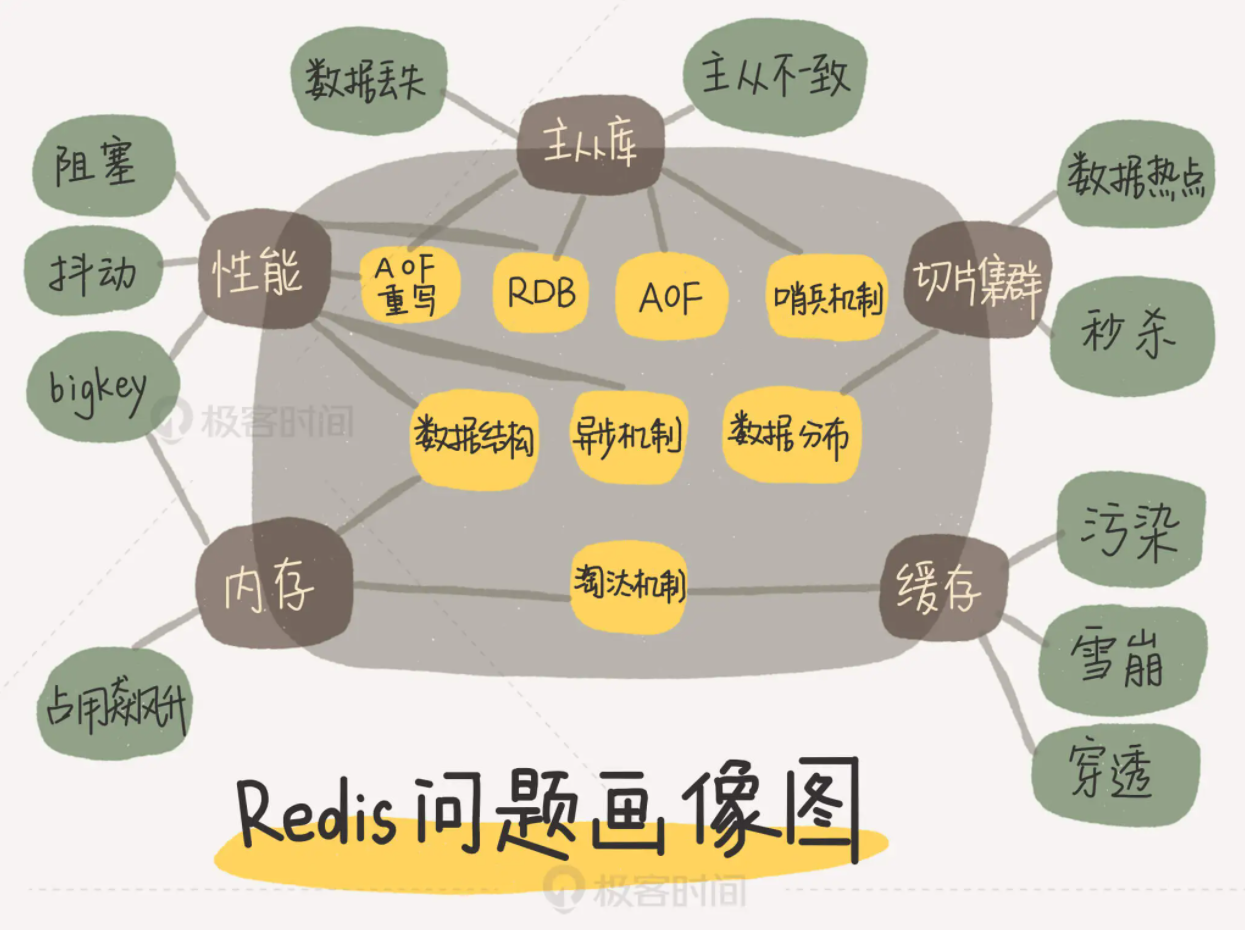
Redis的坑
-
CPU 使用上的“坑”,例如数据结构的复杂度、跨 CPU 核的访问;
-
内存使用上的“坑”,例如主从同步和 AOF 的内存竞争;
-
存储持久化上的“坑”,例如在 SSD 上做快照的性能抖动;
-
网络通信上的“坑”,例如多实例时的异常网络丢包。
Redis知识全景图

“两大维度”就是指系统维度和应用维度,“三大主线”也就是指高性能、高可靠和高可扩展(可以简称为“三高”)。
两大维度、三大主线
-
应用纬度
- 缓存应用
- 集群应用
- 数据结构应用
-
系统纬度
-
处理层
- 线程模型 - (缓存应用,高性能主线)
- 主从复制 - (集群应用,高可靠主线)
- 数据分片 - (数据应用,高可扩展主线)
-
内存层
- 数据结构 - (缓存应用,高性能主线)
- 哨兵机制 - (集群应用,高可靠主线)
-
存储层
- AOF - (缓存应用,高性能主线)
- RDB - (集群应用,高可靠主线)
- 负载均衡 - (数据结构应用,高可扩展主线)
-
网络层
- epoll- (缓存应用,高性能主线)
-
-
三大主线
- 高性能
- 高可用
- 高可扩展
Redis问题画像图
问题-主线-技术点
一个键值数据库包含什么
-
访问模块 -> IO模型设计:网络连接处理、网络请求的解析、数据存储的处理
-
操作接口 -> 根据业务需求扩展:范围查询、exist接口等
-
索引模块 -> 哈希表、B+树、字典树的价高,不同的索引结构在性能、空间消耗、并发控制等方面都具有不同的特性
-
数据模型 -> 不同的数据结构在性能、空间效率方面存在差异,不同的value操作空间存在差异
-
存储模块 -> 根据不同的业务场景设计存储,并引出持久化
-
内存安全性 -> 数据淘汰机制
-
内存利用率 -> 对数据结构优化提高内存利用率,例如使用压缩性的数据结构
-
高可用模块 -> 集群、哨兵、主从复制
-
高可扩展模块 -> 集群分片
SimpleKV 演进到 Redis

Redis底层数据结构
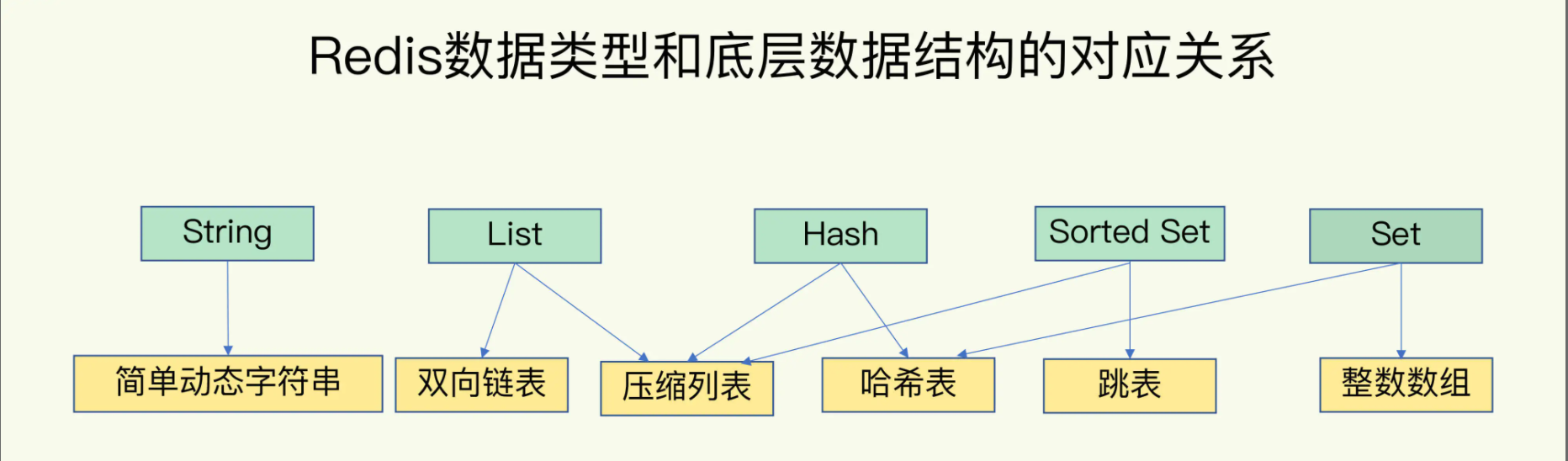
键和值数据结构
-
string:简单动态字符串
-
list:双向链表,压缩列表
-
hash:压缩列表,哈希表
-
Sorted Set:压缩列表,跳表
-
set:哈希表,整数数组
键和值存储结构
Redis使用了一个哈希表保存所有的键值对
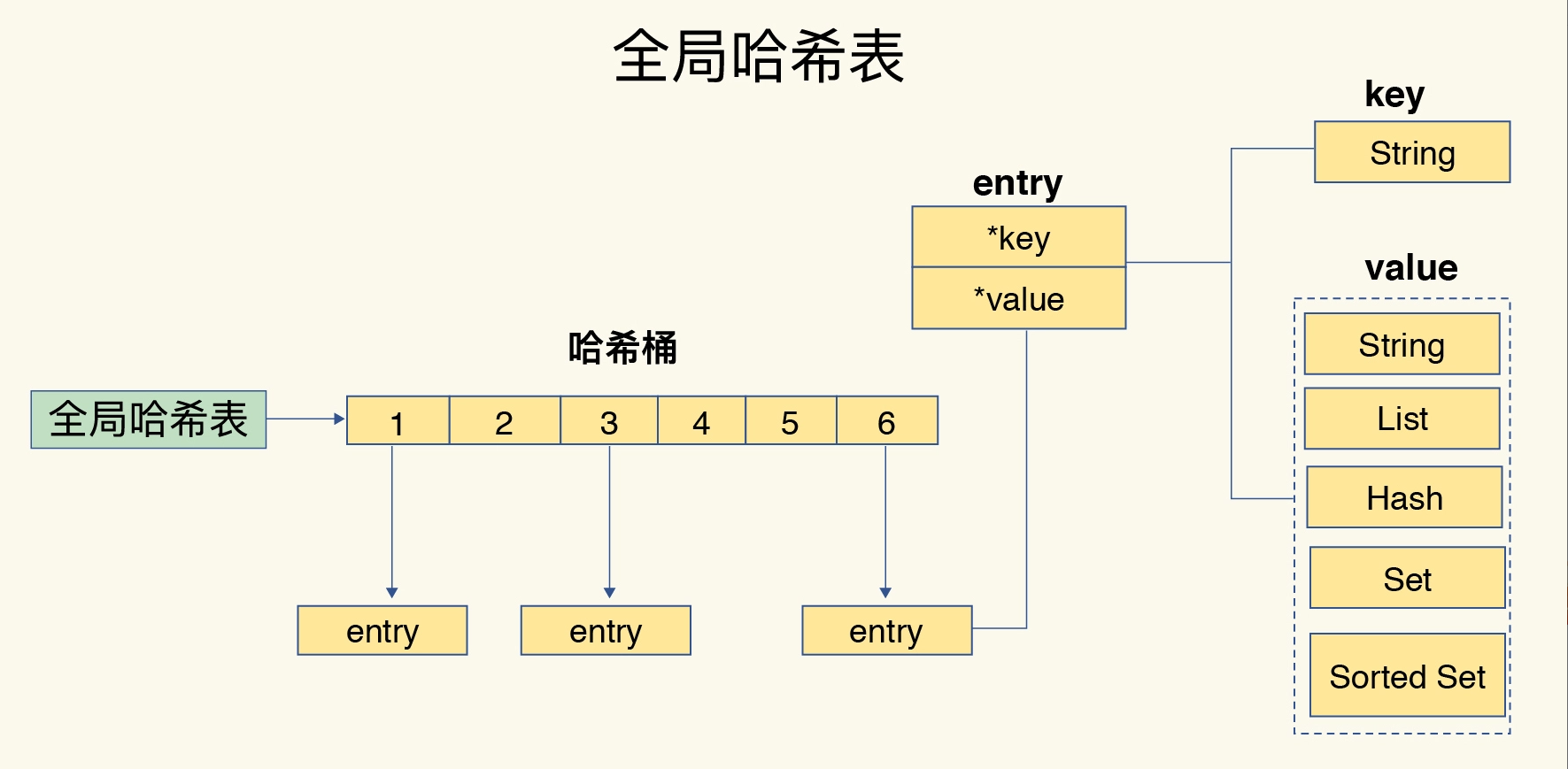
哈希表的最大好处很明显,就是让我们可以用 O(1) 的时间复杂度来快速查找到键值对——我们只需要计算键的哈希值,就可以知道它所对应的哈希桶位置,然后就可以访问相应的 entry 元素。
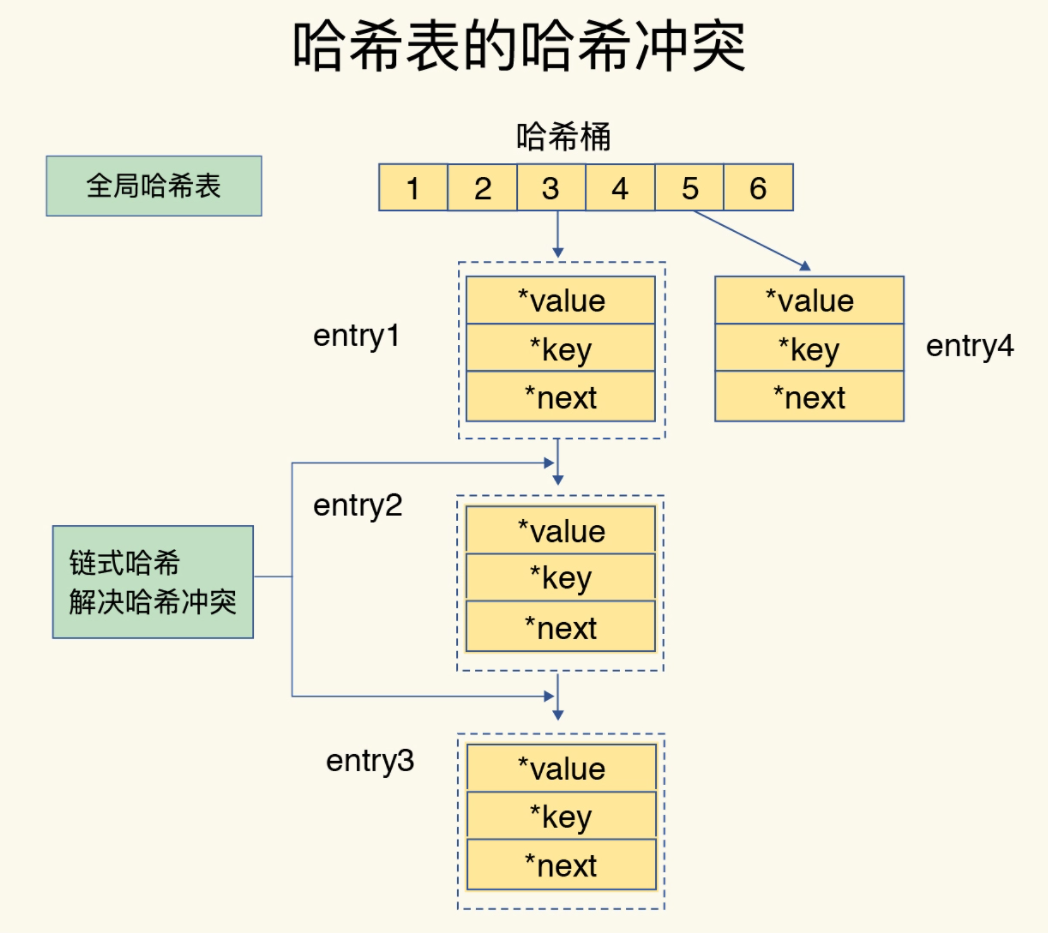
Redis解决哈希冲突的方式,就是链式哈希。链式哈希也很容易理解,就是指同一个哈希桶中的多个元素用一个链表来保存,它们之间依次用指针连接。
渐进式rehash
扩展或收缩哈希表需要将 ht[0] 里面的所有键值对 rehash 到 ht[1] 里面, 但是, 这个 rehash 动作并不是一次性、集中式地完成的, 而是分多次、渐进式地完成的。
这样做的原因在于, 如果 ht[0] 里只保存着四个键值对, 那么服务器可以在瞬间就将这些键值对全部 rehash 到 ht[1] ; 但是, 如果哈希表里保存的键值对数量不是四个, 而是四百万、四千万甚至四亿个键值对, 那么要一次性将这些键值对全部 rehash 到 ht[1] 的话, 庞大的计算量可能会导致服务器在一段时间内停止服务。
因此, 为了避免 rehash 对服务器性能造成影响, 服务器不是一次性将 ht[0] 里面的所有键值对全部 rehash 到 ht[1] , 而是分多次、渐进式地将 ht[0] 里面的键值对慢慢地 rehash 到 ht[1] 。
以下是哈希表渐进式 rehash 的详细步骤:
-
为 ht[1] 分配空间, 让字典同时持有 ht[0] 和 ht[1] 两个哈希表。
-
在字典中维持一个索引计数器变量 rehashidx , 并将它的值设置为 0 , 表示 rehash 工作正式开始。
-
在 rehash 进行期间, 每次对字典执行添加、删除、查找或者更新操作时, 程序除了执行指定的操作以外, 还会顺带将 ht[0] 哈希表在 rehashidx 索引上的所有键值对 rehash 到 ht[1] , 当 rehash 工作完成之后, 程序将 rehashidx 属性的值增一。
-
随着字典操作的不断执行, 最终在某个时间点上, ht[0] 的所有键值对都会被 rehash 至 ht[1] , 这时程序将 rehashidx 属性的值设为 -1 , 表示 rehash 操作已完成。
渐进式 rehash 的好处在于它采取分而治之的方式, 将 rehash 键值对所需的计算工作均滩到对字典的每个添加、删除、查找和更新操作上, 从而避免了集中式 rehash 而带来的庞大计算量。

因为在进行渐进式 rehash 的过程中, 字典会同时使用 ht[0] 和 ht[1] 两个哈希表, 所以在渐进式 rehash 进行期间, 字典的删除(delete)、查找(find)、更新(update)等操作会在两个哈希表上进行: 比如说, 要在字典里面查找一个键的话, 程序会先在 ht[0] 里面进行查找, 如果没找到的话, 就会继续到 ht[1] 里面进行查找, 诸如此类。
另外, 在渐进式 rehash 执行期间, 新添加到字典的键值对一律会被保存到 ht[1] 里面, 而 ht[0] 则不再进行任何添加操作: 这一措施保证了 ht[0] 包含的键值对数量会只减不增, 并随着 rehash 操作的执行而最终变成空表。
底层数据结构
压缩列表
压缩列表实际上类似于一个数组,数组中的每一个元素都对应保存一个数据。和数组不同的是,压缩列表在表头有三个字段 zlbytes、zltail 和 zllen,分别表示列表长度、列表尾的偏移量和列表中的 entry 个数;压缩列表在表尾还有一个 zlend,表示列表结束。
压缩列表的设计不是为了查询的,而是为了减少内存的使用和内存的碎片化。比如一个列表中的只保存int,结构上还需要两个额外的指针prev和next,每添加一个结点都这样。而压缩列表是将这些数据集合起来只需要一个prev和next。

在压缩列表中,如果我们要查找定位第一个元素和最后一个元素,可以通过表头三个字段的长度直接定位,复杂度是 O(1)。而查找其他元素时,就没有这么高效了,只能逐个查找,此时的复杂度就是 O(N) 了。
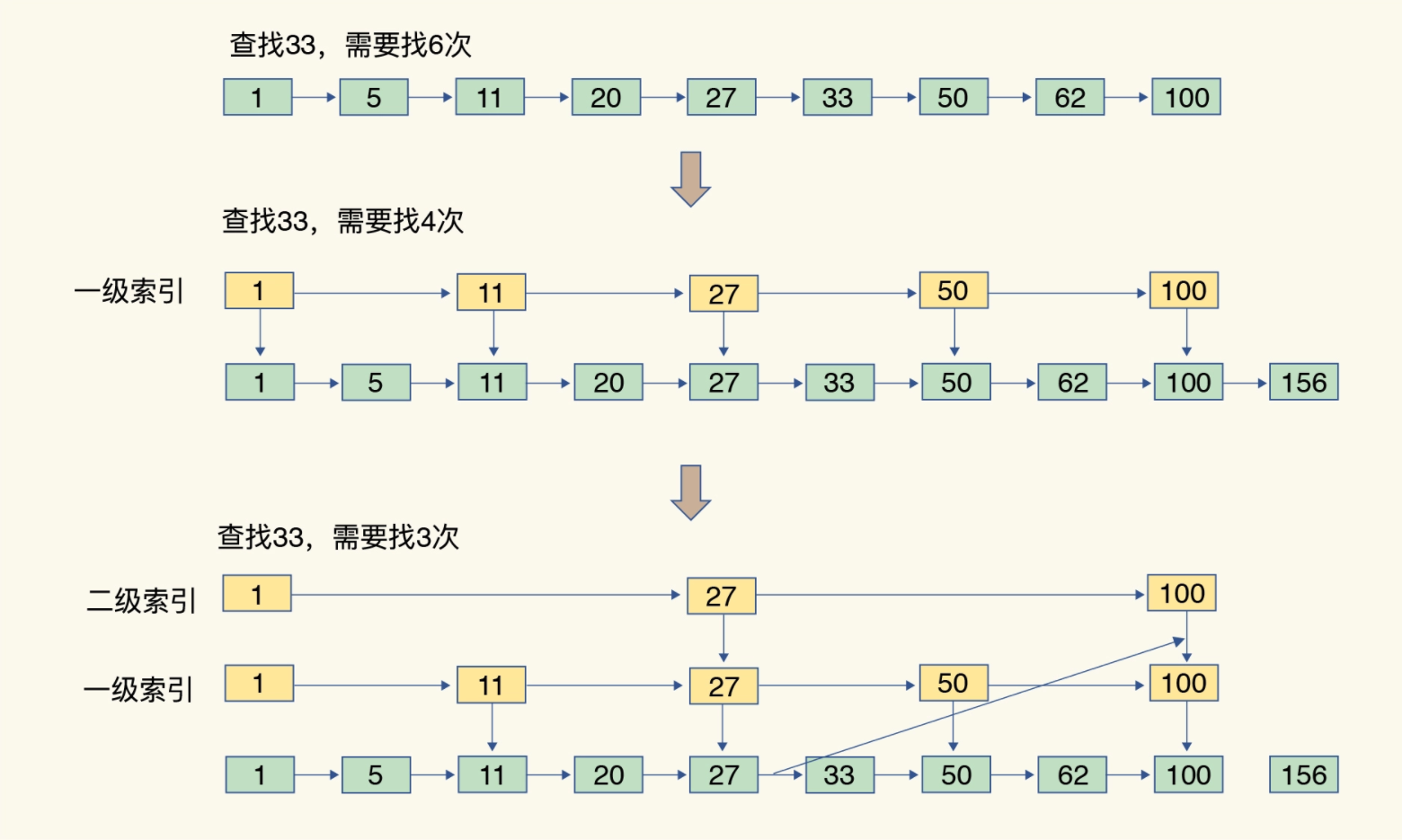
跳表
有序链表只能逐一查找元素,导致操作起来非常缓慢,于是就出现了跳表。具体来说,跳表在链表的基础上,增加了多级索引,通过索引位置的几个跳转,实现数据的快速定位。跳表的查找复杂度就是 O(logN)。
总结
-
单元素操作是基础;
-
范围操作非常耗时;
-
统计操作通常高效;
-
例外情况只有几个。
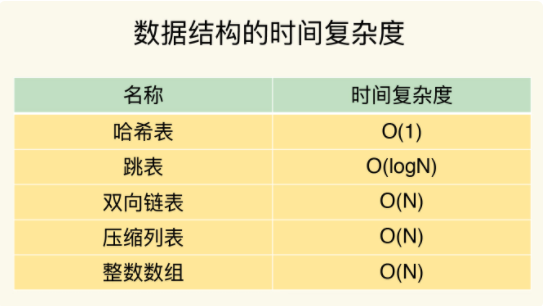
第一,单元素操作,是指每一种集合类型对单个数据实现的增删改查操作。例如,Hash 类型的 HGET、HSET 和 HDEL,Set 类型的 SADD、SREM、SRANDMEMBER 等。这些操作的复杂度由集合采用的数据结构决定,例如,HGET、HSET 和 HDEL 是对哈希表做操作,所以它们的复杂度都是 O(1);Set 类型用哈希表作为底层数据结构时,它的 SADD、SREM、SRANDMEMBER 复杂度也是 O(1)。
第二,范围操作,是指集合类型中的遍历操作,可以返回集合中的所有数据,比如 Hash 类型的 HGETALL 和 Set 类型的 SMEMBERS,或者返回一个范围内的部分数据,比如 List 类型的 LRANGE 和 ZSet 类型的 ZRANGE。这类操作的复杂度一般是 O(N),比较耗时,我们应该尽量避免。
第三,统计操作,是指集合类型对集合中所有元素个数的记录,例如 LLEN 和 SCARD。这类操作复杂度只有 O(1),这是因为当集合类型采用压缩列表、双向链表、整数数组这些数据结构时,这些结构中专门记录了元素的个数统计,因此可以高效地完成相关操作。
第四,例外情况,是指某些数据结构的特殊记录,例如压缩列表和双向链表都会记录表头和表尾的偏移量。这样一来,对于 List 类型的 LPOP、RPOP、LPUSH、RPUSH 这四个操作来说,它们是在列表的头尾增删元素,这就可以通过偏移量直接定位,所以它们的复杂度也只有 O(1),可以实现快速操作。
整数数组和压缩列表在查找时间复杂度方面并没有很大的优势,那为什么 Redis 还会把它们作为底层数据结构呢?
两方面原因:
1、内存利用率,数组和压缩列表都是非常紧凑的数据结构,它比链表占用的内存要更少。Redis是内存数据库,大量数据存到内存中,此时需要做尽可能的优化,提高内存的利用率。
2、数组对CPU高速缓存支持更友好,所以Redis在设计时,集合数据元素较少情况下,默认采用内存紧凑排列的方式存储,同时利用CPU高速缓存不会降低访问速度。当数据元素超过设定阈值后,避免查询时间复杂度太高,转为哈希和跳表数据结构存储,保证查询效率。
为什么单线程Redis能那么快?
Redis 是单线程,主要是指 Redis 的网络 IO 和键值对读写是由一个线程来完成的,这也是 Redis 对外提供键值存储服务的主要流程。但 Redis 的其他功能,比如持久化、异步删除、集群数据同步等,其实是由额外的线程执行的。
Redis 为什么用单线程?
通常情况下,在我们采用多线程后,如果没有良好的系统设计,实际得到的结果,其实是右图所展示的那样。我们刚开始增加线程数时,系统吞吐率会增加,但是,再进一步增加线程时,系统吞吐率就增长迟缓了,有时甚至还会出现下降的情况。
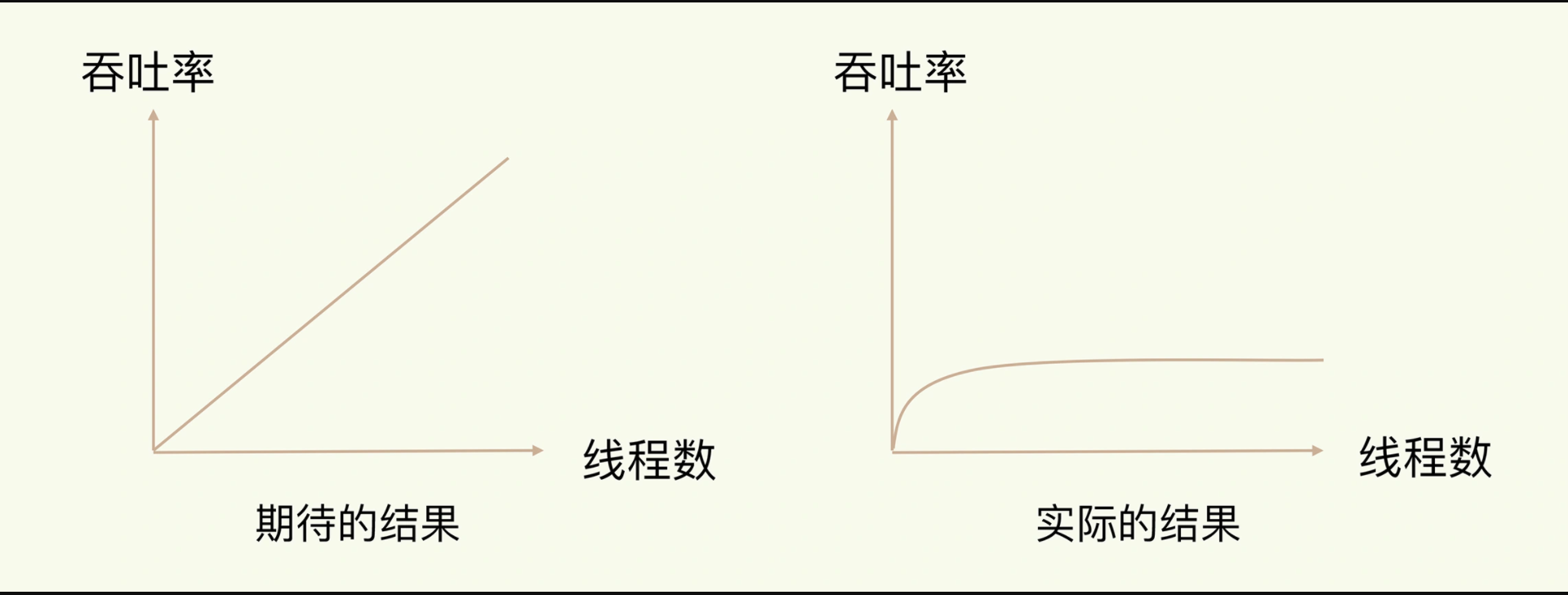
一个关键的瓶颈在于,系统中通常会存在被多线程同时访问的共享资源,比如一个共享的数据结构。当有多个线程要修改这个共享资源时,为了保证共享资源的正确性,就需要有额外的机制进行保证,而这个额外的机制,就会带来额外的开销。这就是多线程编程模式面临的共享资源的并发访问控制问题。
单线程 Redis 为什么那么快?
一方面,Redis 的大部分操作在内存上完成,再加上它采用了高效的数据结构,例如哈希表和跳表,这是它实现高性能的一个重要原因。另一方面,就是 Redis 采用了多路复用机制,使其在网络 IO 操作中能并发处理大量的客户端请求,实现高吞吐率。接下来,我们就重点学习下多路复用机制。
基于多路复用的高性能 I/O 模型
Linux 中的 IO 多路复用机制是指一个线程处理多个 IO 流,就是我们经常听到的 select/epoll 机制。简单来说,在 Redis 只运行单线程的情况下,该机制允许内核中,同时存在多个监听套接字和已连接套接字。内核会一直监听这些套接字上的连接请求或数据请求。一旦有请求到达,就会交给 Redis 线程处理,这就实现了一个 Redis 线程处理多个 IO 流的效果。
下图就是基于多路复用的 Redis IO 模型。图中的多个 FD 就是刚才所说的多个套接字。Redis 网络框架调用 epoll 机制,让内核监听这些套接字。此时,Redis 线程不会阻塞在某一个特定的监听或已连接套接字上,也就是说,不会阻塞在某一个特定的客户端请求处理上。正因为此,Redis 可以同时和多个客户端连接并处理请求,从而提升并发性。

为了在请求到达时能通知到 Redis 线程,select/epoll 提供了基于事件的回调机制,即针对不同事件的发生,调用相应的处理函数。
那么,回调机制是怎么工作的呢?其实,select/epoll 一旦监测到 FD 上有请求到达时,就会触发相应的事件。
这些事件会被放进一个事件队列,Redis 单线程对该事件队列不断进行处理。这样一来,Redis 无需一直轮询是否有请求实际发生,这就可以避免造成 CPU 资源浪费。同时,Redis 在对事件队列中的事件进行处理时,会调用相应的处理函数,这就实现了基于事件的回调。因为 Redis 一直在对事件队列进行处理,所以能及时响应客户端请求,提升 Redis 的响应性能。
为了方便你理解,我再以连接请求和读数据请求为例,具体解释一下。这两个请求分别对应 Accept 事件和 Read 事件,Redis 分别对这两个事件注册 accept 和 get 回调函数。当 Linux 内核监听到有连接请求或读数据请求时,就会触发 Accept 事件和 Read 事件,此时,内核就会回调 Redis 相应的 accept 和 get 函数进行处理。
这就像病人去医院瞧病。在医生实际诊断前,每个病人(等同于请求)都需要先分诊、测体温、登记等。如果这些工作都由医生来完成,医生的工作效率就会很低。所以,医院都设置了分诊台,分诊台会一直处理这些诊断前的工作(类似于 Linux 内核监听请求),然后再转交给医生做实际诊断。这样即使一个医生(相当于 Redis 单线程),效率也能提升。
不过,需要注意的是,即使你的应用场景中部署了不同的操作系统,多路复用机制也是适用的。因为这个机制的实现有很多种,既有基于 Linux 系统下的 select 和 epoll 实现,也有基于 FreeBSD 的 kqueue 实现,以及基于 Solaris 的 evport 实现,这样,你可以根据 Redis 实际运行的操作系统,选择相应的多路复用实现。
总结
Redis单线程处理IO请求性能瓶颈主要包括2个方面:
1、任意一个请求在server中一旦发生耗时,都会影响整个server的性能,也就是说后面的请求都要等前面这个耗时请求处理完成,自己才能被处理到。耗时的操作包括以下几种:
a、操作bigkey:写入一个bigkey在分配内存时需要消耗更多的时间,同样,删除bigkey释放内存同样会产生耗时;
b、使用复杂度过高的命令:例如SORT/SUNION/ZUNIONSTORE,或者O(N)命令,但是N很大,例如lrange key 0 -1一次查询全量数据;
c、大量key集中过期:Redis的过期机制也是在主线程中执行的,大量key集中过期会导致处理一个请求时,耗时都在删除过期key,耗时变长;
d、淘汰策略:淘汰策略也是在主线程执行的,当内存超过Redis内存上限后,每次写入都需要淘汰一些key,也会造成耗时变长;
e、AOF刷盘开启always机制:每次写入都需要把这个操作刷到磁盘,写磁盘的速度远比写内存慢,会拖慢Redis的性能;
f、主从全量同步生成RDB:虽然采用fork子进程生成数据快照,但fork这一瞬间也是会阻塞整个线程的,实例越大,阻塞时间越久;
2、并发量非常大时,单线程读写客户端IO数据存在性能瓶颈,虽然采用IO多路复用机制,但是读写客户端数据依旧是同步IO,只能单线程依次读取客户端的数据,无法利用到CPU多核。
针对问题1,一方面需要业务人员去规避,一方面Redis在4.0推出了lazy-free机制,把bigkey释放内存的耗时操作放在了异步线程中执行,降低对主线程的影响。
针对问题2,Redis在6.0推出了多线程,可以在高并发场景下利用CPU多核多线程读写客户端数据,进一步提升server性能,当然,只是针对客户端的读写是并行的,每个命令的真正操作依旧是单线程的。

