DataX二次开发-适配自定义数据源

背景
DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入,这里介绍通用RDBMS数据库如何进行自定义扩展注册进DataX。
- 需求:扩展SAP HANA数据源(其他数据源都可)相关的读写插件能够进行异构数据源的同步工作。
环境准备
从github上拉取最新的DataX源码
git clone https://github.com/alibaba/DataX.git
导入idea后新建模块 hanareader\hanawriter
参考DataX提供的插件开发宝典,可建立以下目录结构
请点击:DataX插件开发宝典
├─hanareader
│ │ pom.xml
│ │
│ ├─doc
│ │ hanareader.md
│ │
│ └─src
│ └─main
│ ├─assembly
│ │ package.xml
│ │
│ ├─java
│ │ └─com
│ │ └─alibaba
│ │ └─datax
│ │ └─plugin
│ │ └─reader
│ │ └─hanareader
│ │ Constant.java
│ │ HanaReader.java
│ │ HanaReaderErrorCode.java
│ │
│ ├─libs
│ │ ngdbc-2.8.12.jar
│ │
│ └─resources
│ plugin.json
│ plugin_job_template.json
│
├─hanawriter
│ │ pom.xml
│ │
│ ├─doc
│ │ hanawriter.md
│ │
│ └─src
│ └─main
│ ├─assembly
│ │ package.xml
│ │
│ ├─java
│ │ └─com
│ │ └─alibaba
│ │ └─datax
│ │ └─plugin
│ │ └─writer
│ │ └─hanawriter
│ │ HanaWriter.java
│ │
│ ├─libs
│ │ ngdbc-2.8.12.jar
│ │
│ └─resources
│ plugin.json
│ plugin_job_template.json
│
配置对应的plugin.json
{
"name": "hanawriter",
"class": "com.alibaba.datax.plugin.writer.hanawriter.HanaWriter",
"description": "useScene: prod. mechanism: Jdbc connection using the database, execute select sql, retrieve data from the ResultSet. warn: The more you know about the database, the less problems you encounter.",
"developer": "xmzpc"
}
{
"name": "hanareader",
"class": "com.alibaba.datax.plugin.reader.hanareader.HanaReader",
"description": "useScene: prod. mechanism: Jdbc connection using the database, execute select sql, retrieve data from the ResultSet. warn: The more you know about the database, the less problems you encounter.",
"developer": "xmzpc"
}
将HANA JDBC的jar包放入hanareader/src/main/libs、hanawriter/src/main/libs目录下
ngdbc-2.8.12.jar
读、写插件编写
根据DataX插件加载原理可知,plugin.json配置的name为插件的名称,必须全局唯一作为jarLoaderCenter的key存储,value为插件对应的ClassLoader。class为插件实现类的全限定类名,用于类加载。
因此,可新建com.alibaba.datax.plugin.reader.hanareader.HanaReader类并继承com.alibaba.datax.common.spi.Reader类,若无特殊需求,按照通用RDBMS的读插件编写即可。
HanaReader.java
package com.alibaba.datax.plugin.reader.hanareader;
import com.alibaba.datax.common.exception.DataXException;
import com.alibaba.datax.common.plugin.RecordSender;
import com.alibaba.datax.common.spi.Reader;
import com.alibaba.datax.common.util.Configuration;
import com.alibaba.datax.plugin.rdbms.reader.CommonRdbmsReader;
import com.alibaba.datax.plugin.rdbms.reader.Key;
import com.alibaba.datax.plugin.rdbms.reader.util.HintUtil;
import com.alibaba.datax.plugin.rdbms.util.DBUtilErrorCode;
import com.alibaba.datax.plugin.rdbms.util.DataBaseType;
import org.apache.commons.lang3.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.List;
public class HanaReader extends Reader {
private static final DataBaseType DATABASE_TYPE = DataBaseType.HANA;
public static class Job extends Reader.Job {
private static final Logger LOG = LoggerFactory.getLogger(Job.class);
private Configuration originalConfig = null;
private CommonRdbmsReader.Job commonRdbmsReaderJob;
@Override
public void init() {
this.originalConfig = super.getPluginJobConf();
Integer fetchSize = this.originalConfig.getInt(com.alibaba.datax.plugin.rdbms.reader.Constant.FETCH_SIZE, Constant.DEFAULT_FETCH_SIZE);
if (fetchSize < 1) {
throw DataXException
.asDataXException(
DBUtilErrorCode.REQUIRED_VALUE,
String.format(
"您配置的fetchSize有误,根据DataX的设计,fetchSize : [%d] 设置值不能小于 1.",
fetchSize));
}
LOG.info("Custom parameter [ fetchSize ] = {}", fetchSize.toString());
this.originalConfig.set(com.alibaba.datax.plugin.rdbms.reader.Constant.FETCH_SIZE, fetchSize);
this.commonRdbmsReaderJob = new CommonRdbmsReader.Job(DATABASE_TYPE);
this.commonRdbmsReaderJob.init(this.originalConfig);
// 注意:要在 this.commonRdbmsReaderJob.init(this.originalConfig); 之后执行,这样可以直接快速判断是否是querySql 模式
dealHint(this.originalConfig);
}
@Override
public void preCheck() {
init();
}
@Override
public void destroy() {
}
@Override
public List<Configuration> split(int adviceNumber) {
return this.commonRdbmsReaderJob.split(this.originalConfig, adviceNumber);
}
private void dealHint(Configuration originalConfig) {
String hint = originalConfig.getString(Key.HINT);
if (StringUtils.isNotBlank(hint)) {
boolean isTableMode = originalConfig.getBool(com.alibaba.datax.plugin.rdbms.reader.Constant.IS_TABLE_MODE);
if(!isTableMode){
throw DataXException.asDataXException(HanaReaderErrorCode.HINT_ERROR, "当且仅当非 querySql 模式读取 oracle 时才能配置 HINT.");
}
HintUtil.initHintConf(DATABASE_TYPE, originalConfig);
}
}
}
public static class Task extends Reader.Task {
private Configuration readerSliceConfig;
private CommonRdbmsReader.Task commonRdbmsReaderTask;
@Override
public void init() {
this.readerSliceConfig = super.getPluginJobConf();
this.commonRdbmsReaderTask = new CommonRdbmsReader.Task(DATABASE_TYPE, super.getTaskGroupId(), super.getTaskId());
this.commonRdbmsReaderTask.init(this.readerSliceConfig);
}
@Override
public void startRead(RecordSender recordSender) {
int fetchSize = this.readerSliceConfig.getInt(com.alibaba.datax.plugin.rdbms.reader.Constant.FETCH_SIZE);
this.commonRdbmsReaderTask.startRead(this.readerSliceConfig, recordSender,
super.getTaskPluginCollector(), fetchSize);
}
@Override
public void post() {
this.commonRdbmsReaderTask.post(this.readerSliceConfig);
}
@Override
public void destroy() {
this.commonRdbmsReaderTask.destroy(this.readerSliceConfig);
}
}
}
写插件也一样,和读插件类似,但是要注意DataX目前只实现了对MySQL的writeMode的配置,后面的博客会对此进行改造。
HanaWriter.java
package com.alibaba.datax.plugin.writer.hanawriter;
import com.alibaba.datax.common.exception.DataXException;
import com.alibaba.datax.common.plugin.RecordReceiver;
import com.alibaba.datax.common.spi.Writer;
import com.alibaba.datax.common.util.Configuration;
import com.alibaba.datax.plugin.rdbms.util.DBUtilErrorCode;
import com.alibaba.datax.plugin.rdbms.util.DataBaseType;
import com.alibaba.datax.plugin.rdbms.writer.CommonRdbmsWriter;
import com.alibaba.datax.plugin.rdbms.writer.Key;
import java.util.List;
public class HanaWriter extends Writer {
private static final DataBaseType DATABASE_TYPE = DataBaseType.HANA;
public static class Job extends Writer.Job {
private Configuration originalConfig = null;
private CommonRdbmsWriter.Job commonRdbmsWriterJob;
@Override
public void preCheck() {
this.init();
this.commonRdbmsWriterJob.writerPreCheck(this.originalConfig, DATABASE_TYPE);
}
@Override
public void init() {
this.originalConfig = super.getPluginJobConf();
// warn:not like mysql, hana only support insert mode, don't use
String writeMode = this.originalConfig.getString(Key.WRITE_MODE);
if (null != writeMode) {
throw DataXException
.asDataXException(
DBUtilErrorCode.CONF_ERROR,
String.format(
"写入模式(writeMode)配置错误. 因为Hana不支持配置项 writeMode: %s, Hana只能使用insert sql 插入数据. 请检查您的配置并作出修改",
writeMode));
}
this.commonRdbmsWriterJob = new CommonRdbmsWriter.Job(DATABASE_TYPE);
this.commonRdbmsWriterJob.init(this.originalConfig);
}
// 一般来说,是需要推迟到 task 中进行pre 的执行(单表情况例外)
@Override
public void prepare() {
this.commonRdbmsWriterJob.prepare(this.originalConfig);
}
@Override
public List<Configuration> split(int mandatoryNumber) {
return this.commonRdbmsWriterJob.split(this.originalConfig, mandatoryNumber);
}
// 一般来说,是需要推迟到 task 中进行post 的执行(单表情况例外)
@Override
public void post() {
this.commonRdbmsWriterJob.post(this.originalConfig);
}
@Override
public void destroy() {
this.commonRdbmsWriterJob.destroy(this.originalConfig);
}
}
public static class Task extends Writer.Task {
private Configuration writerSliceConfig;
private CommonRdbmsWriter.Task commonRdbmsWriterTask;
@Override
public void init() {
this.writerSliceConfig = super.getPluginJobConf();
this.commonRdbmsWriterTask = new CommonRdbmsWriter.Task(DATABASE_TYPE);
this.commonRdbmsWriterTask.init(this.writerSliceConfig);
}
@Override
public void prepare() {
this.commonRdbmsWriterTask.prepare(this.writerSliceConfig);
}
public void startWrite(RecordReceiver recordReceiver) {
this.commonRdbmsWriterTask.startWrite(recordReceiver, this.writerSliceConfig,
super.getTaskPluginCollector());
}
@Override
public void post() {
this.commonRdbmsWriterTask.post(this.writerSliceConfig);
}
@Override
public void destroy() {
this.commonRdbmsWriterTask.destroy(this.writerSliceConfig);
}
@Override
public boolean supportFailOver() {
String writeMode = writerSliceConfig.getString(Key.WRITE_MODE);
return "replace".equalsIgnoreCase(writeMode);
}
}
}
配置文件修改
读插件
- hanareader/src/main/assembly/package.xml
这个文件主要配置打包时文件存放的路径,按照其他插件仿着改就行了
<assembly
xmlns="http://maven.apache.org/plugins/maven-assembly-plugin/assembly/1.1.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/plugins/maven-assembly-plugin/assembly/1.1.0 http://maven.apache.org/xsd/assembly-1.1.0.xsd">
<id></id>
<formats>
<format>dir</format>
</formats>
<includeBaseDirectory>false</includeBaseDirectory>
<fileSets>
<fileSet>
<directory>src/main/resources</directory>
<includes>
<include>plugin.json</include>
<include>plugin_job_template.json</include>
</includes>
<outputDirectory>plugin/reader/hanareader</outputDirectory>
</fileSet>
<fileSet>
<directory>target/</directory>
<includes>
<include>hanareader-0.0.1-SNAPSHOT.jar</include>
</includes>
<outputDirectory>plugin/reader/hanareader</outputDirectory>
</fileSet>
<fileSet>
<directory>src/main/libs</directory>
<includes>
<include>*.*</include>
</includes>
<outputDirectory>plugin/reader/hanareader/libs</outputDirectory>
</fileSet>
</fileSets>
<dependencySets>
<dependencySet>
<useProjectArtifact>false</useProjectArtifact>
<outputDirectory>plugin/reader/hanareader/libs</outputDirectory>
<scope>runtime</scope>
</dependencySet>
</dependencySets>
</assembly>
- hanareader/pom.xml
pom文件主要新增assembly plugin的支持
<build>
<plugins>
<!-- compiler plugin -->
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>${jdk-version}</source>
<target>${jdk-version}</target>
<encoding>${project-sourceEncoding}</encoding>
</configuration>
</plugin>
<!-- assembly plugin -->
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptors>
<descriptor>src/main/assembly/package.xml</descriptor>
</descriptors>
<finalName>datax</finalName>
</configuration>
<executions>
<execution>
<id>dwzip</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
写插件
写插件和读插件类似,都只是修改配置路径,这里不再赘述。
根目录下的package.xml
这里主要配置对hanareader以及hanawriter打包后文件输出路径。
<fileSet>
<directory>hanawriter/target/datax/</directory>
<includes>
<include>**/*.*</include>
</includes>
<outputDirectory>datax</outputDirectory>
</fileSet>
<fileSet>
<directory>hanareader/target/datax/</directory>
<includes>
<include>**/*.*</include>
</includes>
<outputDirectory>datax</outputDirectory>
</fileSet>
打包
打包前,先填坑:
- oscarwriter模块没提供oscarJDBC.jar,以此编译不会通过,在根目录pom文件和package.xml移除oscarwriter的依赖即可。
- 还有一些阿里内部的数据源模块也进行依赖移除
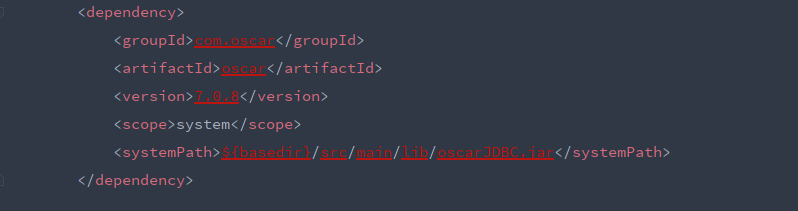
通过maven打包:
$ cd {DataX_source_code_home}
$ mvn -U clean package assembly:assembly -Dmaven.test.skip=true
打包成功,日志显示如下:
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 09:45 min
[INFO] Finished at: 2021-10-20T15:37:01+08:00
[INFO] ------------------------------------------------------------------------
打包成功后目录如下:
$ cd {DataX_source_code_home}
$ ls ./target/datax/datax/
bin conf job lib log log_perf plugin script tmp
并且在plugin/reader下有hanareader、plugin/writer下有hanawriter目录,这样自定义插件就完成了。
源码
github源码:DataX二次开发

 浙公网安备 33010602011771号
浙公网安备 33010602011771号