
Java线程池详解
线程池:
线程池,顾名思义存放线程的池子,因为频繁的创建和销毁线程池是一件非常损耗性能的事情,所以如果先定义一个池子里面放上一定量的线程,有需要的时候就去里面取,用完了再放里面,这样不仅能缩短创建销毁线程的时间,也能减轻服务器的压力。在jdk1.5中Doug Lea引入了Executor框架,把任务的提交和执行解耦,在代码层面,我们只需要提交任务, 不再需要再关心线程是如何执行。
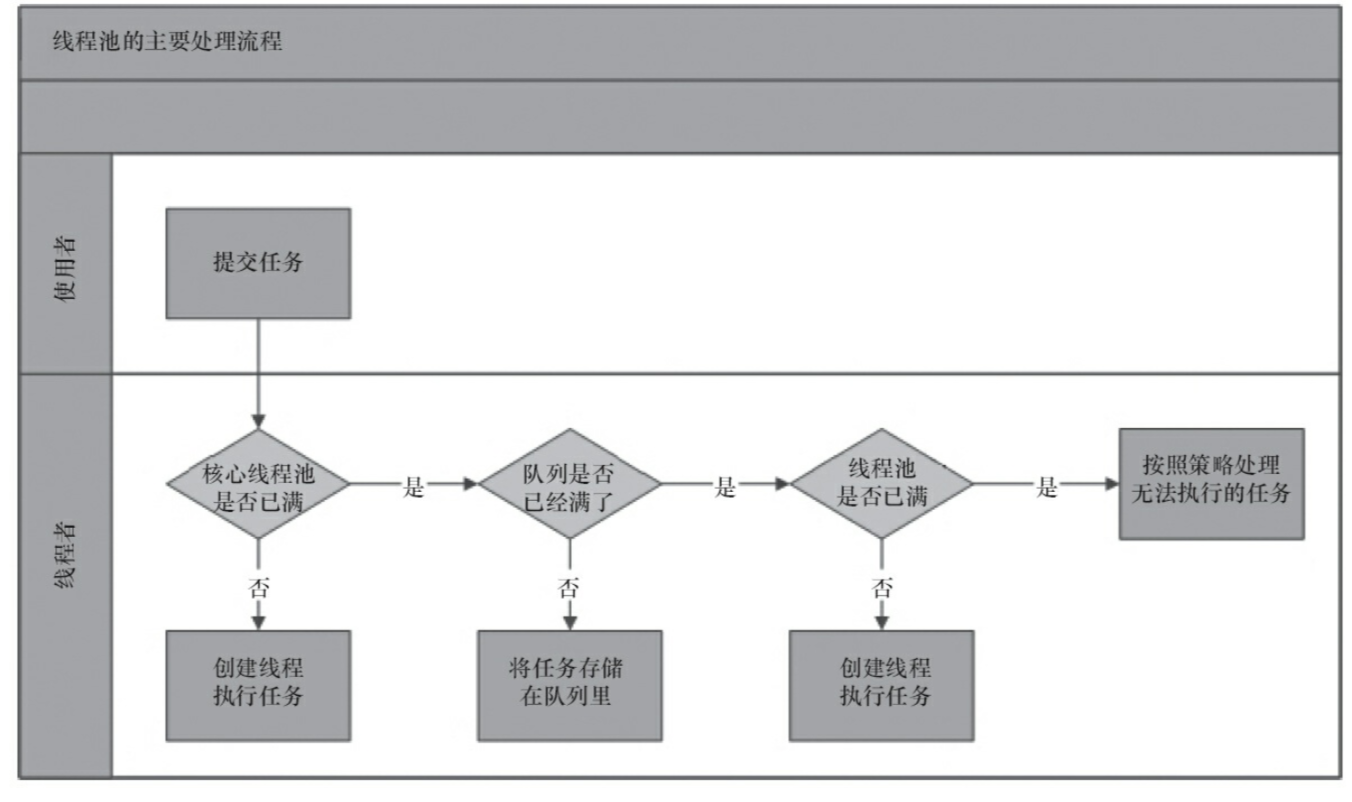
Executors:
1.创建线程池
Executors是java线程池的工厂类,他可以帮助我们快速创建一个线程池,如Executors.newFixedThreadPool方法可以生成一个拥有固定线程数的线程池。

初始化线程池的时候有5个参数,分别是 corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,还有两个默认参数 threadFactory, handler
corePoolSize:线程池初始核心线程数。初始化线程池的时候,池内是没有线程,只有在执行任务的时会创建线程。
maximumPoolSize:线程池允许存在的最大线程数。
keepAliveTime: 当线程数大于corePoolSize,线程空闲时的存活时间,即当线程没有任务执行时,继续存活的时间;默认情况下,该参数只在线程数大于corePoolSize时才有用
unit:keepAliveTime 的时间单位
workQueue:缓存任务的的队列,一般采用LinkedBlockingQueue。

threadFactory:执行程序创建新线程时使用的工厂,一般采用默认值。
handler:超出线程范围和队列容量而使执行被阻塞时所使用的处理程序,一般采用默认值 AbortPolicy。

2.线程池种类
1.SingleThreadExecutor:corePoolSize和maximumPoolSize都是1,所以keepAliveTime失效,创建的是只有一个线程,如果线程异常结束,会立即创建一个新的线程,这会保证提交的任务会顺序执行
2.FixedThreadPool:固定大小的线程池corePoolSize=maximumPoolSize ,keepAliveTime=0,当线程池没有可执行任务时,不会释放线程。
由于FixedThreadPool的LinkedBlockQueue是无界的,所以maximumPoolSize参数是无效的,当线程数大于corePoolSize时,多余的线程都会进入LinkedBlockQueue等待
当线程完成任务后,会不断的从LinkedBlockQueue取任务来执行。
3.CachedThreadPool:maximumPoolSize=Integer.MAX_VALUE,这是一个很危险的参数,当线程池没有可执行的任务的时,会释放线程,当提交新任务时,如果没有空闲线程,则创建新线程执行任务,会导致一定的系统开销;所以使用这个线程池时,我们一定要注意系统的并发量,否则一不小心成千上万的线程创建出来,会非常的危险。
CachedThreadPool用的是SynchronousQueue,这是一个没有容量的队列。
由于corePoolSize=0,所以每次有任务都会进入到SynchronousQueue,但是SynchronousQueue的offer和take必须成对出现,所以大部分情况下,CachedThreadPool接受到任务会直接新建一个线程,由于maximumPoolSize=Integer.MAX_VALUE,所以基本等于无限制
4.ScheduledThreadPool:初始化的线程池可以在指定的时间内周期性的执行所提交的任务,在实际的业务场景中可以使用该线程池定期的同步数据
ThreadPoolExecutor:
1.状态常量定义
上述我们讲了四种线程池,除了ScheduledThreadPool,其余都是基于ThreadPoolExecutor实现的,现在来了解下ThreadPoolExecutor的内部实现
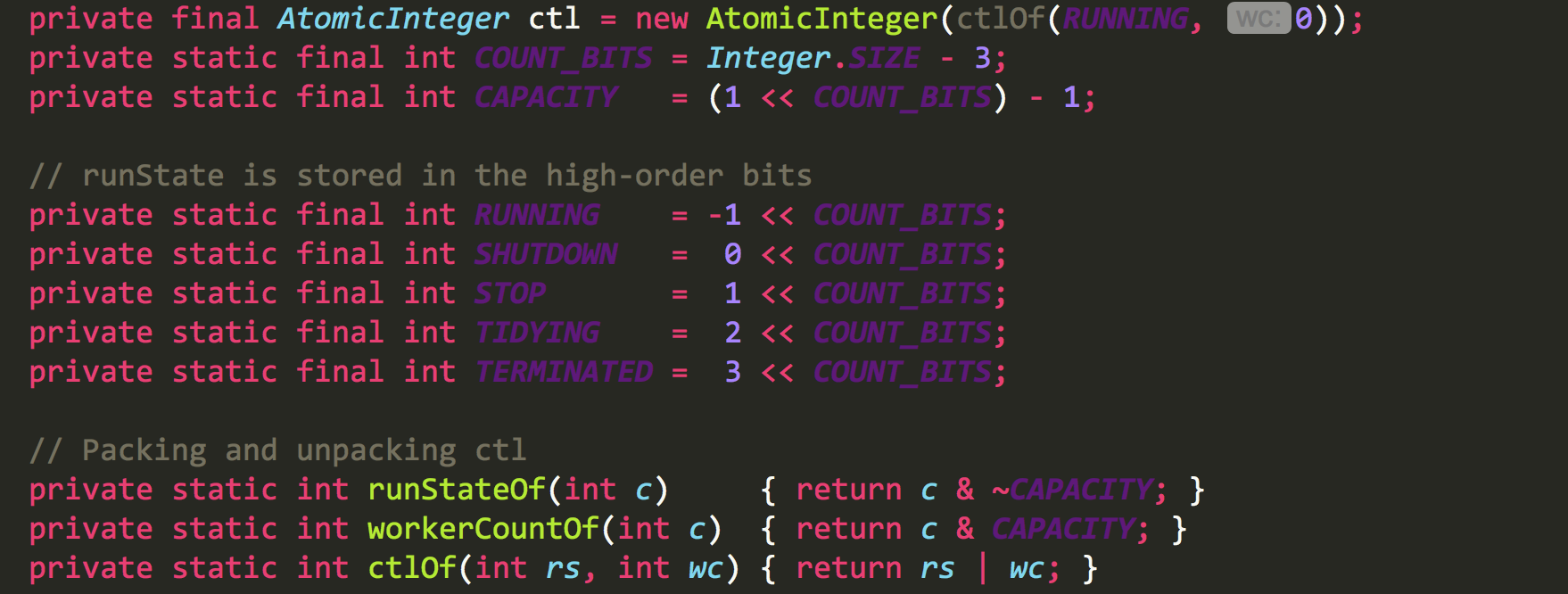
1.ctl是个非常灵活的变量,他的高三位表示线程的运行状态,低29位表示线程池中的线程数
2.RUNING 高三位是111,该状态的线程池会接收新任务,并处理阻塞队列中的任务;
3.SHUTDOWN 高三位000,该状态的线程池不会接收新任务,但会处理阻塞队列中的任务;
4.STOP 高三位是001,该状态的线程不会接收新任务,也不会处理阻塞队列中的任务,而且会中断正在运行的任务
5.TIDYING 即高3位为010;
6.TERMINATED 即高3位为011;
2.任务执行
当向线程池提交任务,线程池执行execute方法
1 public void execute(Runnable command) { 2 //判断空 3 if (command == null) 4 throw new NullPointerException(); 5 int c = ctl.get(); 6 //判断当前线程数和corePoolSize,如果小于corePoolSize 执行addWorker方法创建新的线程执行任务 7 if (workerCountOf(c) < corePoolSize) { 8 if (addWorker(command, true)) 9 return; 10 c = ctl.get(); 11 } 12 //如果线程池处于RUNNING状态,且成功的把提交的任务放入阻塞队列中 13 if (isRunning(c) && workQueue.offer(command)) { 14 int recheck = ctl.get(); 15 //再次检查状态,如果不是运行中,且成功从阻塞队列中把任务删除, 16 //执行reject方法,否则的话执行addWorker创建新线程 17 if (! isRunning(recheck) && remove(command)) 18 reject(command); 19 else if (workerCountOf(recheck) == 0) 20 addWorker(null, false); 21 } 22 //如果addWoker执行失败,则执行reject方法处理任务; 23 else if (!addWorker(command, false)) 24 reject(command); 25 }
我们可以看到execute方法中,通过addWorker创建新的线程,我们再看看addWorker里面发生了什么
1 private boolean addWorker(Runnable firstTask, boolean core) { 2 retry: 3 for (;;) { 4 int c = ctl.get(); 5 int rs = runStateOf(c); 6 7 // Check if queue empty only if necessary. 8 //判断线程池状态,如果线程池的状态值大于或等于SHUTDOWN,直接返回false 9 if (rs >= SHUTDOWN && 10 ! (rs == SHUTDOWN && 11 firstTask == null && 12 ! workQueue.isEmpty())) 13 return false; 14 15 for (;;) { 16 //获取当前线程池中的线程数 17 int wc = workerCountOf(c); 18 //如果线程数大于池的容量,直接返回false 19 if (wc >= CAPACITY || 20 wc >= (core ? corePoolSize : maximumPoolSize)) 21 return false; 22 //增加线程池中的线程计数,成功则跳出循环 23 if (compareAndIncrementWorkerCount(c)) 24 break retry; 25 c = ctl.get(); // Re-read ctl 26 if (runStateOf(c) != rs) 27 continue retry; 28 // else CAS failed due to workerCount change; retry inner loop 29 } 30 } 31 32 boolean workerStarted = false; 33 boolean workerAdded = false; 34 Worker w = null; 35 try { 36 //线程池的工作线程是通过Worker实现 37 w = new Worker(firstTask); 38 final Thread t = w.thread; 39 if (t != null) { 40 //加锁 41 final ReentrantLock mainLock = this.mainLock; 42 mainLock.lock(); 43 try { 44 int rs = runStateOf(ctl.get()); 45 //判断当前线程状态 46 if (rs < SHUTDOWN || 47 (rs == SHUTDOWN && firstTask == null)) { 48 //??? 49 if (t.isAlive()) // precheck that t is startable 50 throw new IllegalThreadStateException(); 51 //添加到集合里去 52 workers.add(w); 53 int s = workers.size(); 54 if (s > largestPoolSize) 55 largestPoolSize = s; 56 workerAdded = true; 57 } 58 } finally { 59 mainLock.unlock(); 60 } 61 //启动线程,这里调用的是runWorker方法 62 if (workerAdded) { 63 t.start(); 64 workerStarted = true; 65 } 66 } 67 } finally { 68 if (! workerStarted) 69 addWorkerFailed(w); 70 } 71 return workerStarted; 72 }
Work实现线程池中的线程

addworker方法中启动线程时,其实是执行了runWoeker方法,我们看下内部执行
![]()
1 final void runWorker(Worker w) { 2 Thread wt = Thread.currentThread(); 3 Runnable task = w.firstTask; 4 w.firstTask = null; 5 w.unlock(); // allow interrupts 6 boolean completedAbruptly = true; 7 try { 8 //从getTask获取要执行的任务,直到返回null。这里达到了线程复用的效果,让线程处理多个任务。 9 while (task != null || (task = getTask()) != null) { 10 w.lock(); 11 // If pool is stopping, ensure thread is interrupted; 12 // if not, ensure thread is not interrupted. This 13 // requires a recheck in second case to deal with 14 // shutdownNow race while clearing interrupt 15 //保证了线程池在STOP状态下线程是中断的,非STOP状态下线程没有被中断 16 if ((runStateAtLeast(ctl.get(), STOP) || 17 (Thread.interrupted() && 18 runStateAtLeast(ctl.get(), STOP))) && 19 !wt.isInterrupted()) 20 wt.interrupt(); 21 try { 22 beforeExecute(wt, task); 23 Throwable thrown = null; 24 try { 25 //执行线程 26 task.run(); 27 } catch (RuntimeException x) { 28 thrown = x; throw x; 29 } catch (Error x) { 30 thrown = x; throw x; 31 } catch (Throwable x) { 32 thrown = x; throw new Error(x); 33 } finally { 34 afterExecute(task, thrown); 35 } 36 } finally { 37 task = null; 38 w.completedTasks++; 39 w.unlock(); 40 } 41 } 42 completedAbruptly = false; 43 } finally { 44 processWorkerExit(w, completedAbruptly); 45 } 46 }
这里面最关键的就是第9行的getTask方法,
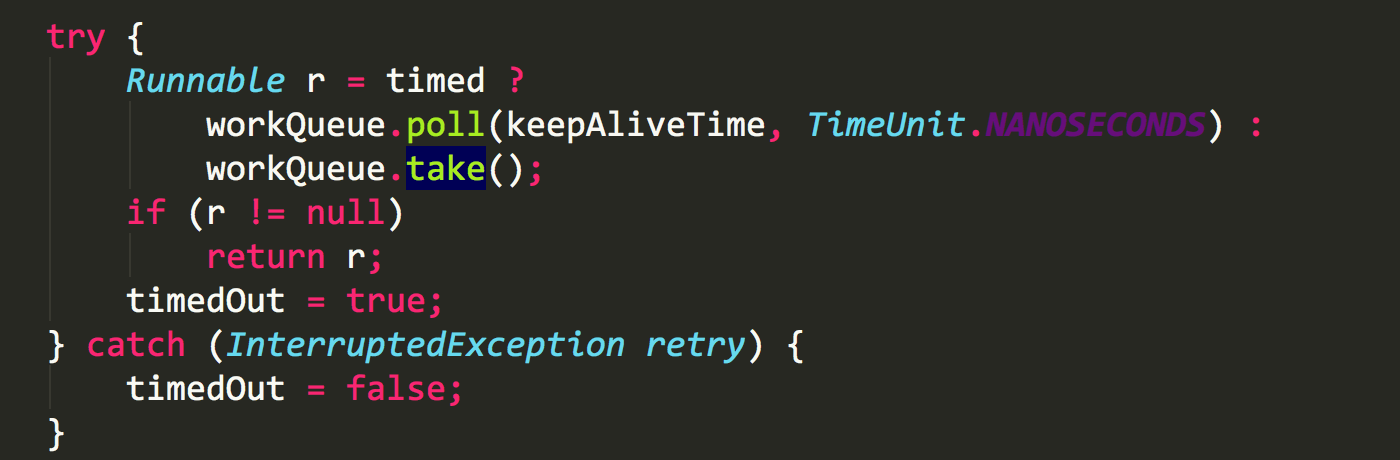
这里截取了getTask的关键代码,
2、workQueue.poll:如果在keepAliveTime时间内,阻塞队列还是没有任务,则返回null;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号