
相信很多金融类的从业者和学者都比较偏好于爬取金融类数据,比如博主我✧(≖ ◡ ≖✿)
在完成了简单的环境配置后,博主我安耐不住鸡冻的心情,打算先爬个基金数据以解手痒,顺便通过这个案例简单了解一下其中涉及到的一些爬虫原理
环境
tools
1、Chrome及其developer tools
2、python3.7
3、PyCharm
python3.7中使用的库
1、requests
2、re——正则表达式
3、json
4、pandas
5、math
6、sqlalchemy——博主选择用万能的SQLAlchemy完成数据库的存储,小规模爬虫的盆友可以直接保存到本地的csv文件
系统
Mac OS 10.13.2
爬虫
在此,博主选择的是爬虫对象是一个叫天天基金的boy,爬虫的目标是获得基金的净值数据。
在正式爬取每个基金的数据之前,我们应先获取一个基金列表,再根据列表里面所列出来的基金逐一进行爬取。由此,我们的爬虫步骤将分为以下两步:
1、获取基金代码列表
2、爬取基金净值的数据
获取基金代码列表
用Chrome浏览器登录天天基金的网页,找到基金代码列表的对应网址,用浏览器强大的developer tool来观察网页的内容,检查js文件后,发现了一个可疑的对象——fundcode_search.js:

双击点开这个js文件,我们惊奇的发现——OMG! 基金代码居然都在里面!!!
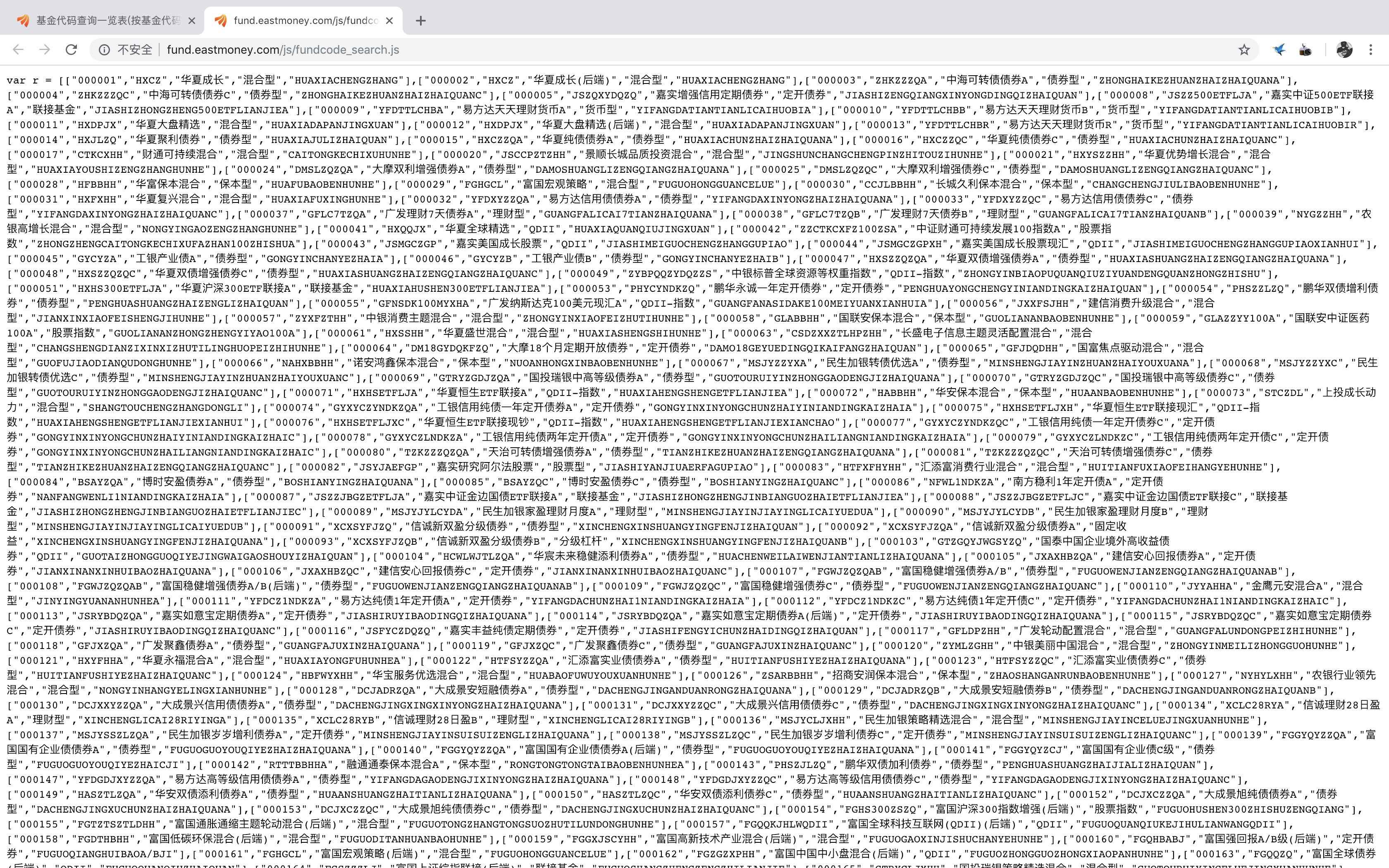
我们尝试用requests.get直接获取网页内容试试
1 import requests 2 r = requests.get('http://fund.eastmoney.com/js/fundcode_search.js') 3 r.text
我们获取的内容为
![]()
很显然,我们需要获取的基金代码是以list的形式存储的,为了获取这段字符串中的list,我们可以直接通过正则表达式提取list。
但是,直接通过正则表达式获取的list是以字符串形式呈现的,为了将其转为list格式,这里我们则需要用到json.loads()函数
1 cont = re.findall('var r = (.*])', r.text)[0] # 提取list 2 ls = json.loads(cont) # 将字符串个事的list转化为list格式 3 all_fundCode = pd.DataFrame(ls, columns=['基金代码', '基金名称缩写', '基金名称', '基金类型', '基金名称拼音']) # list转为DataFrame
这样,通过一段简单的代码,我们便获取到了所有的基金代码。
那么,我们获取了所有基金代码的列表后,这些数据对我们接下来爬取基金净值又有什么用呢?我们来随机选取一个基金(以000001华夏成长为例),点击进入网页进行观察
爬取基金净值数据
寻找动态网页中的数据存储文件
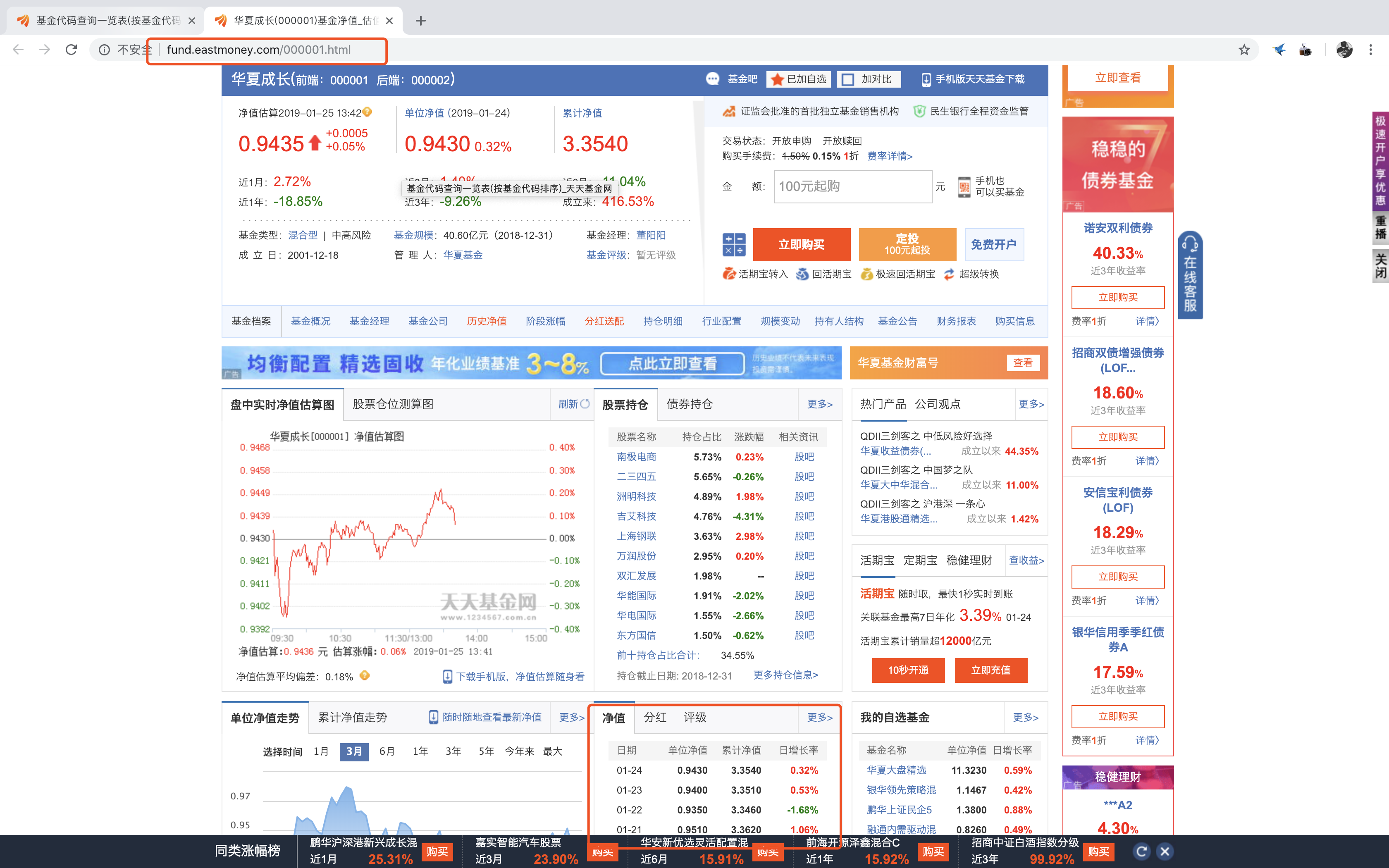
观察其url:http://fund.eastmoney.com/000001.html,不难发现这个网页是由“固定组成+基金代码”的形式构成的,我们再进入净值入口观察其url构成
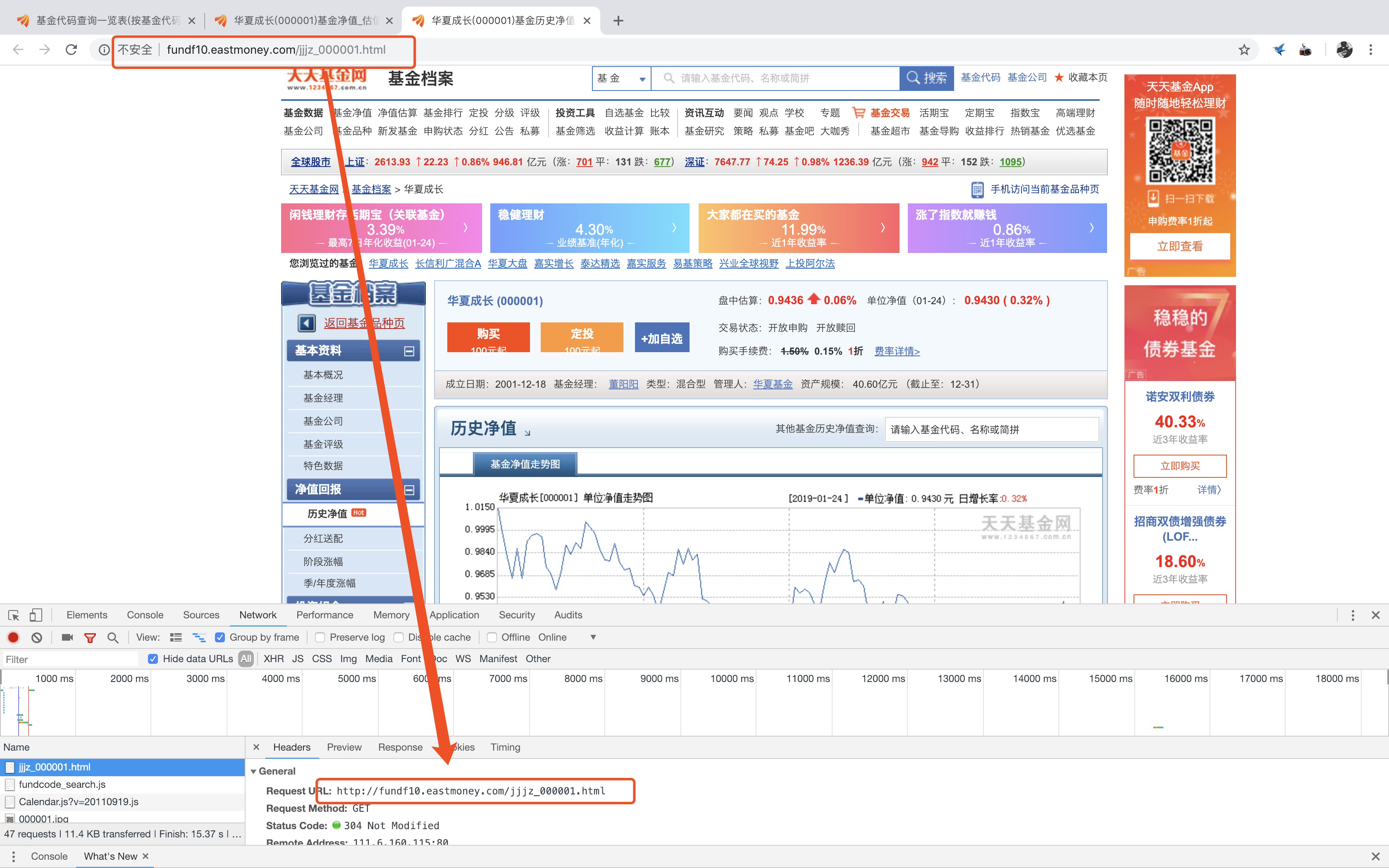
显然,这也是一段规律性极强的url,我们可以大胆的猜测,所有基金净值的url形式均是形如“http://fundf10.eastmoney.com/jjjz_基金代码.html”。
由此,我们之前获取基金代码的作用就显而易见了。
下面,我们还需要寻找基金历史净值的网页信息,看到Network里面密密麻麻一大堆网页文件,真的让人很晕+_+,难道我们只能把这些文件一个个点开来么?

倔强的我当然是不会屈服的【其实是懒】。
既然懒得找,不如直接搜一搜试试?于是根据之前基金网页的url构成经验,我大胆的猜测净值数据的文件名,于是乎……还真被我找到了!!○( ^皿^)っHiahia…
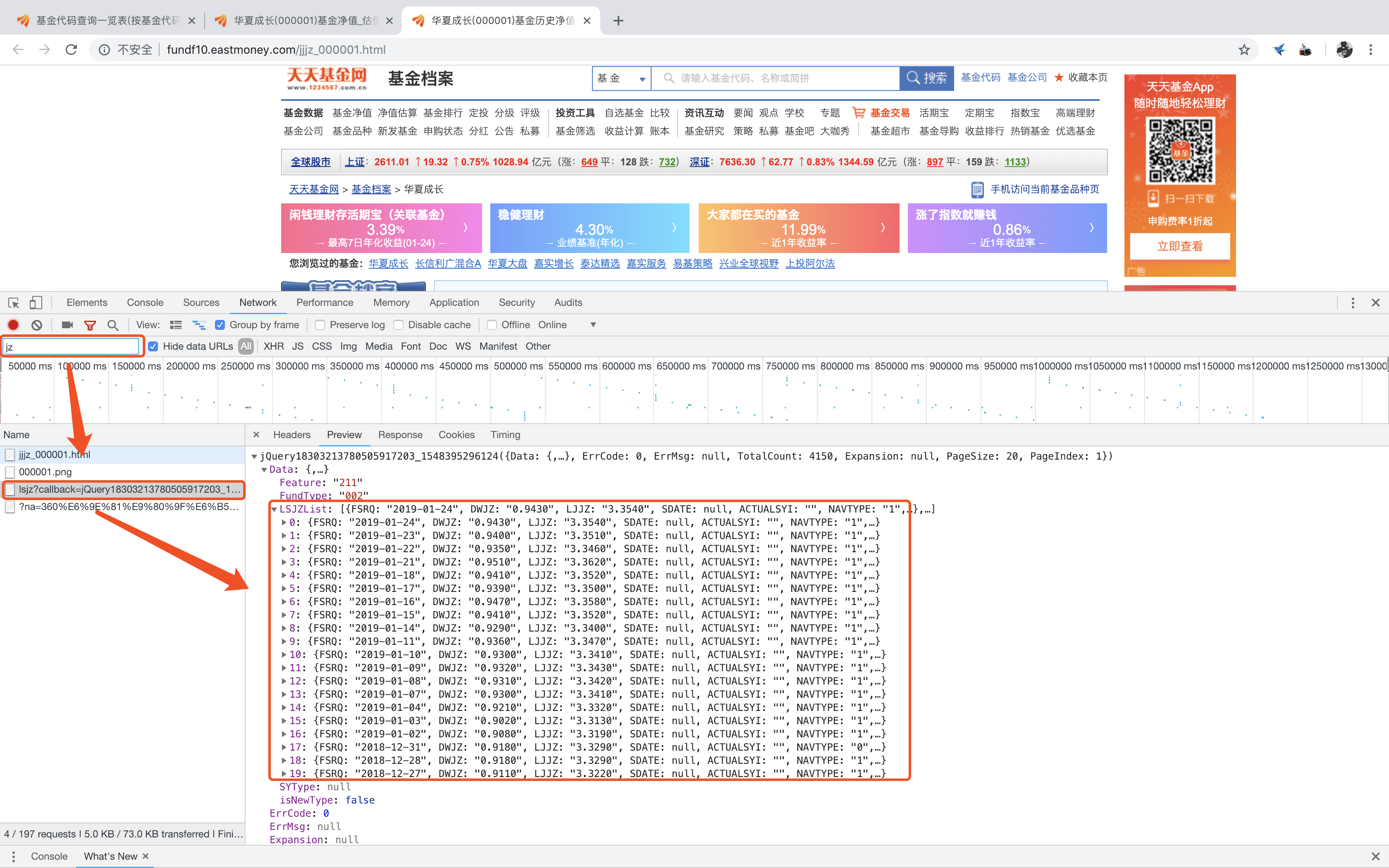
继续用Chrome的开发者工具观察该网页文件的Headers信息,我们可以得到“请求头文件(Request Headers)”和“URL访问的构成参数(Query String Parameters)”的信息
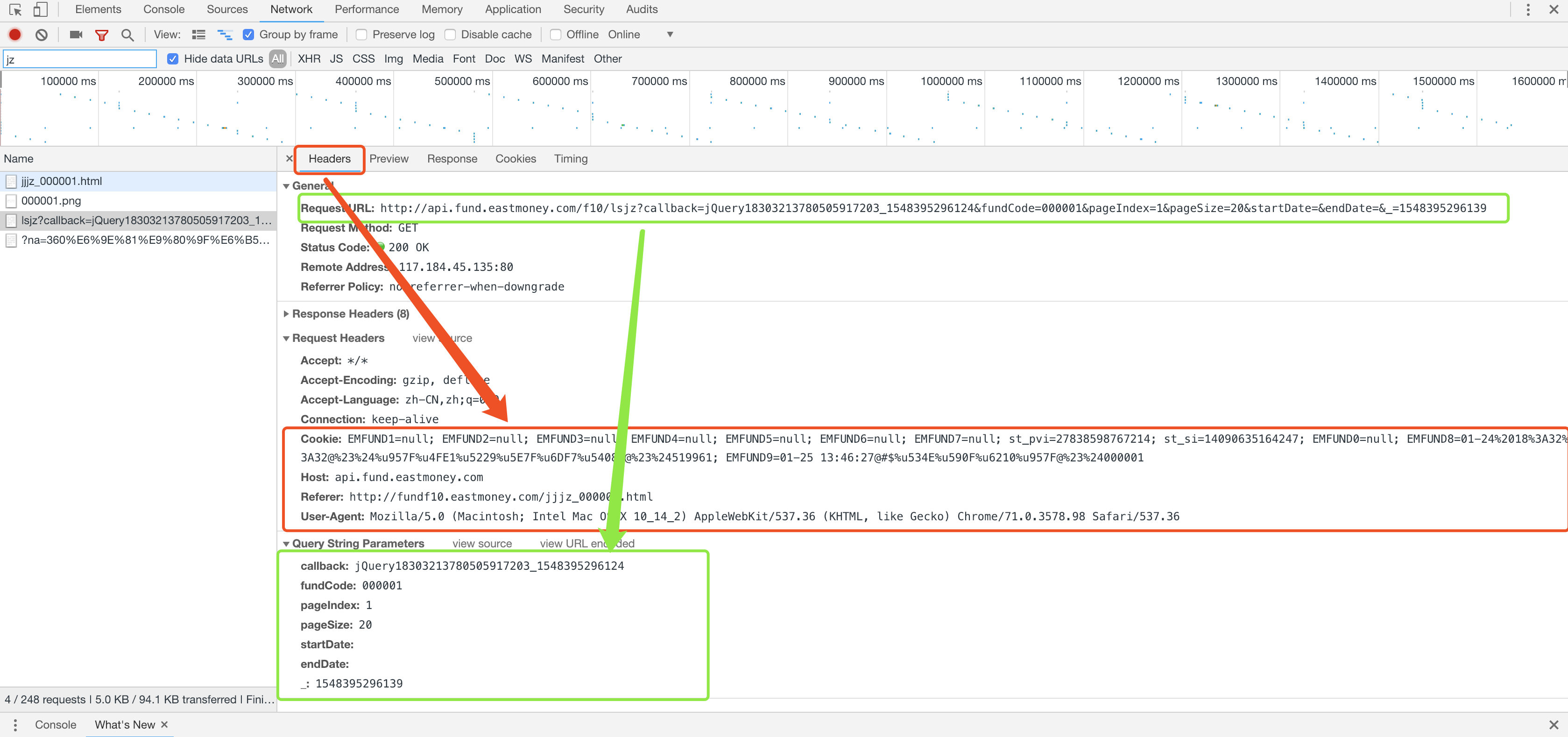
其中,观察Query String Parameters的信息,对比发出请求的URL,不难发现URL的构成中各个参数的意义:
- callback:调回函数,是JavaScript中的一种高级函数,一种被作为参数传递给另一个函数的高级函数,申请调用的函数就是jQuery函数
- fundCode:基金代码
- pageIndex:对应基金历史净值明细的页数
- pageSize:每页返回的数据个数
- startDate/endDate:历史净值明细中起始和截止日期的筛选
- _:访问的时间戳
爬取网页文件内容
那么,如果我们和之前一样,直接双击这个js文件会怎么样呢?

我们可以看到,之前在developer tool里看见的数据都消失了,这是为什么呢?
先别着急,我们先用requests.get()试一下,看看得到的内容是否也是这样。
url = 'http://api.fund.eastmoney.com/f10/lsjz?callback=jQuery18303213780505917203_1548395296124&fundCode=000001&pageIndex=1&pageSize=20&startDate=&endDate=&_=1548395296139' r = requests.get(url=url) r.text >>> 'jQuery18303213780505917203_1548395296124({"Data":"","ErrCode":-999,"ErrMsg":"","TotalCount":0,"Expansion":null,"PageSize":0,"PageIndex":0})'
果然,直接对该url进行访问的结果和之前在浏览器内直接打开该链接所得到的结果是一样的,为了找到其原因,我们继续利用开发者工具观察该网页的信息
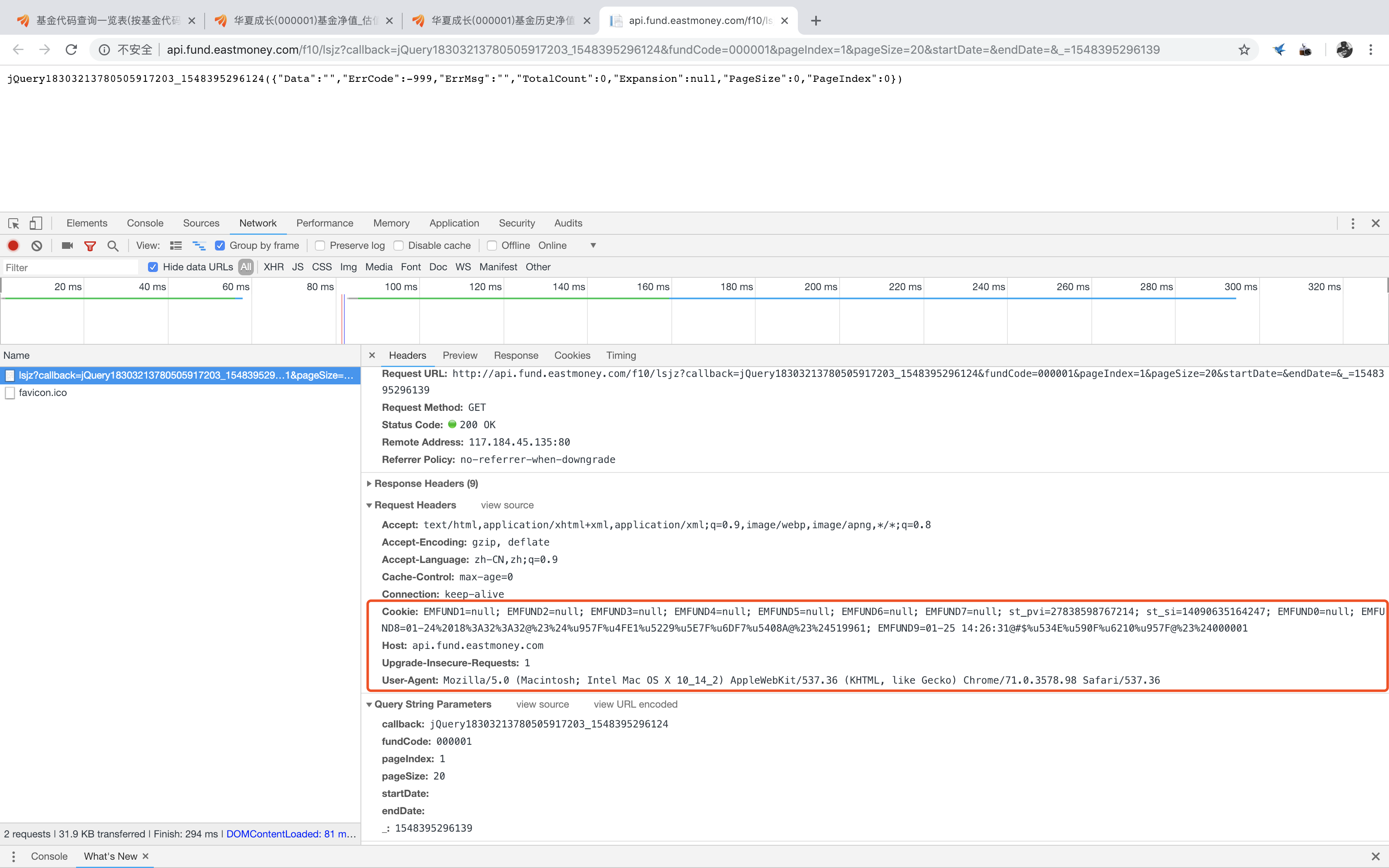
对比后不难发现,它的Request Headers内少了Refer,再回头看看Refer的内容——“http://fundf10.eastmoney.com/jjjz_000001.html”,正是我们访问基金净值的源网页。
由此,我们可以大胆的推理,存储基金净值数据的js文件是在客户端发出访问请求时,是会通过识别Refer这一信息来判断是否返回数据的。因此,我们在发出请求时,必须要把Refer这一信息带上才行。
根据这一结论,我们来更新一下自己的代码
1 fundCode = '000001' 2 pageIndex = 1 3 url = 'http://api.fund.eastmoney.com/f10/lsjz' 4 5 # 参数化访问链接,以dict方式存储 6 params = { 7 'callback': 'jQuery18307633215694564663_1548321266367', 8 'fundCode': fundCode, 9 'pageIndex': pageIndex, 10 'pageSize': 20, 11 } 12 # 存储cookie内容 13 cookie = 'EMFUND1=null; EMFUND2=null; EMFUND3=null; EMFUND4=null; EMFUND5=null; EMFUND6=null; EMFUND7=null; EMFUND8=null; EMFUND0=null; EMFUND9=01-24 17:11:50@#$%u957F%u4FE1%u5229%u5E7F%u6DF7%u5408A@%23%24519961; st_pvi=27838598767214; st_si=11887649835514' 14 # 装饰头文件 15 headers = { 16 'Cookie': cookie, 17 'Host': 'api.fund.eastmoney.com', 18 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36', 19 'Referer': 'http://fundf10.eastmoney.com/jjjz_%s.html' % fundCode, 20 } 21 r = requests.get(url=url, headers=headers, params=params) # 发送请求 22 23 r.text
运行代码后成功获取了历史净值是数据,其内容是嵌套在jQuery内的一个dict,我们可以和之前一样,用正则表达的方法提取出dict,并用json.loads()函数将这段string格式的dict转为dict格式,以获取目标数据
1 text = re.findall('\((.*?)\)', r.text)[0] # 提取dict 2 LSJZList = json.loads(text)['Data']['LSJZList'] # 获取历史净值数据 3 TotalCount = json.loads(text)['TotalCount'] # 转化为dict 4 LSJZ = pd.DataFrame(LSJZList) # 转化为DataFrame格式 5 LSJZ['fundCode'] = fundCode # 新增一列fundCode
上述代码获得的结果如下:
爬取所有历史净值数据
在成功爬取了一页的历史净值后,下一个我们需要解决的问题是——爬多少页?
此时,之前获取的网页内容中,有一个叫TotalCount的数据引起了我的注意
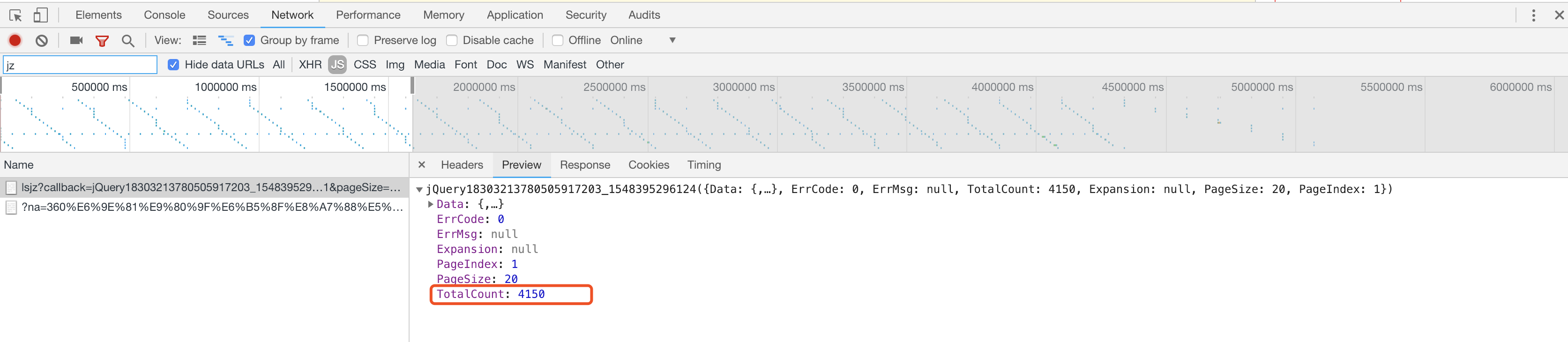
在这个数据的帮助下,如果我们想要确定爬取的页数,只要将TotalCount➗PageSize,然后取整数,就可以搞定了~
1 total_page = math.ceil(total_count / 20)
在确定了需要爬取的页数后,只要写一个简单的循环,便可以遍历所有的数据了~
小结
以上,我们完成了一个简单的基金历史净值爬取的目标,和核心代码的部分展示,但在过程中,其实还有很多细节上的疑问和问题没有得到解决,比如:
- 在讲到参数化访问链接时,我们会想知道url究竟是什么?它的构成有什么规律可循?
- 进行requests.get()访问时,其中的headers和params参数又是什么?还有什么别的参数设置么?
- 是否只有get一种访问形式?
- Request Headers中列出的内容又分别代表什么?
- 当我们尝试直接用循环去爬取所有内容的时候,真的安全么?是否会遭遇反爬?又该如何解决反爬?
- 在具体项目实施中,我们还需要考虑到数据的如何更新?
这些问题有些涉及到爬虫原理,有些涉及到项目实操,针对这些问题的解答和完整代码的演示,则由下篇来解答~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号