实验八 文件
安徽工程大学
Python程序设计实验报告
班级 物流192 姓名 徐敏 学号 3190505232 成绩 _____
日期 2020.6.3 指导老师 修宇
实验八 文件
【实验目的】
掌握读写文本文件或 CSV 文件,进而对数据进行处理的方法。
【实验条件】
PC机或者远程编程环境
【实验内容】
完成二个编程题。
1)水浒传词频统计
水浒传-词频统计
描述
使用词频统计的方法,生成《水浒传》出场次数最多的10个人物的姓名。
水浒传文本下载:
读取《水浒传》文本文件的代码如下:
txt = open("AllManAreBrothers.txt", "r", encoding="utf-8").read()

代码模板:
# ThreeKingdomsV2
import jieba
# 读取txt文件,获取需要统计词汇的文本
txt = open("AllManAreBrothers.txt", "r", encoding="utf-8").read()
# 设置需要输出最多的前n位人物的数量
n = 10
# 请在下列exludes集合中,自行补充其他需要排除的词汇
excludes = {
"两个", "一个", "只见", "如何", "那里", "哥哥",
}
words = jieba.lcut(txt)
counts = {}
# 请扩展下列分支结构,转换更多替代词
for word in words:
if len(word) == 1:
continue
elif word == "宋江道":
rword = "宋江"
else:
rword = word
counts[rword] = counts.get(rword, 0) + 1
# 实现删除干扰词汇功能(此处约2行代码)
# 使用列表和lambda功能实现 词汇的排序 (此处约2行代码)
# 依次输出统计次数最多的前n位(此处约3行代码)
2)血压心率分析
描述
BP.txt”是以逗号分隔的日期、血压、心率记录数据文本文件( open('BP.txt',encoding="gbk"))
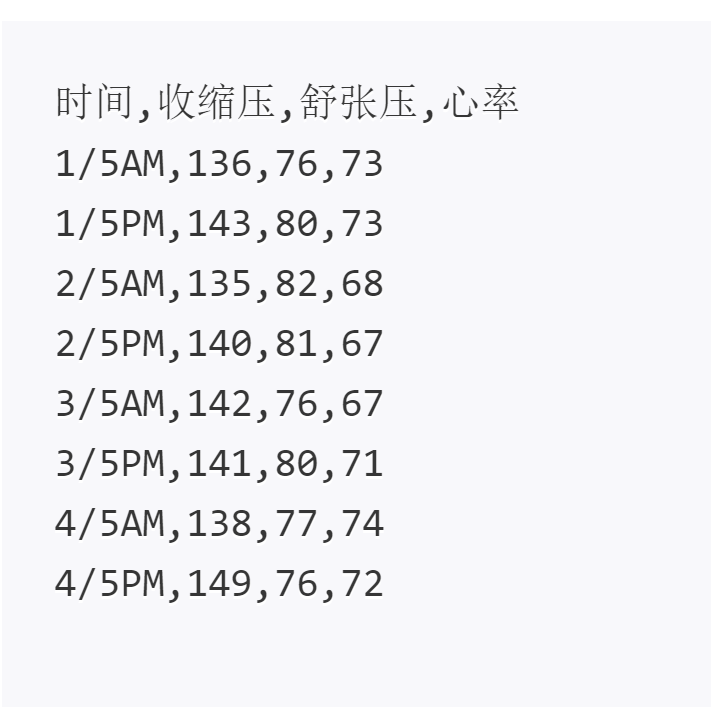
统计收缩压、舒张压、心率的总平均值(保留3位小数)。

【实验记录与分析】(请在此填写实验记录与分析结果)
1)水浒传词频统计
读完题后,根据老师给的模板,结合实例在IDLE尝试了第一次编写。
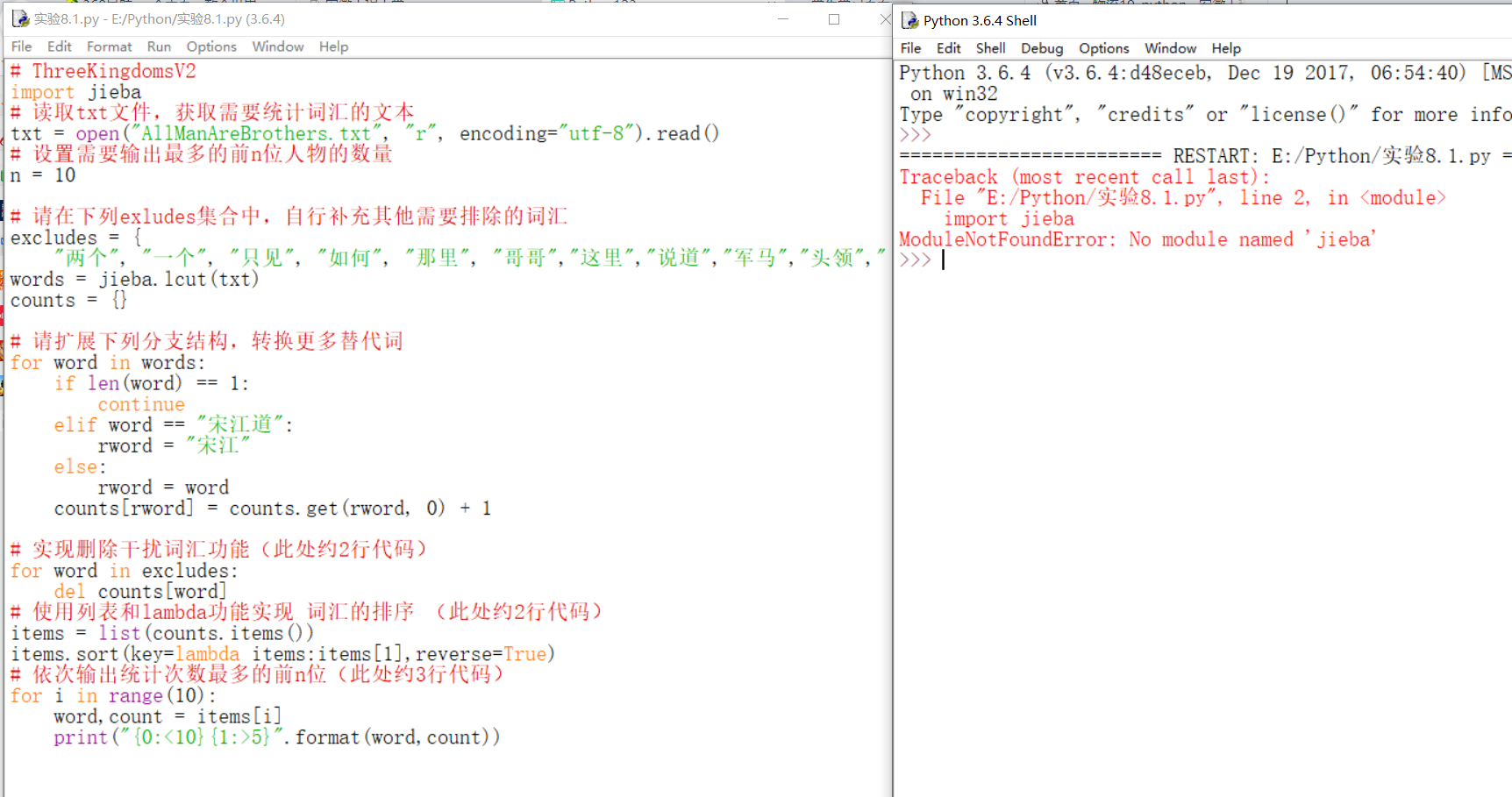
程序出现问题:MoudleNotFoundError:No module named 'jieba'
百度查找后,发现原来是电脑没有安装“jieba”。
所以就直接在Python123中进行实验。待实验完成后,再安装“jieba”。
将IDLE上的程序直接复制到Python123中,得到以下结果。
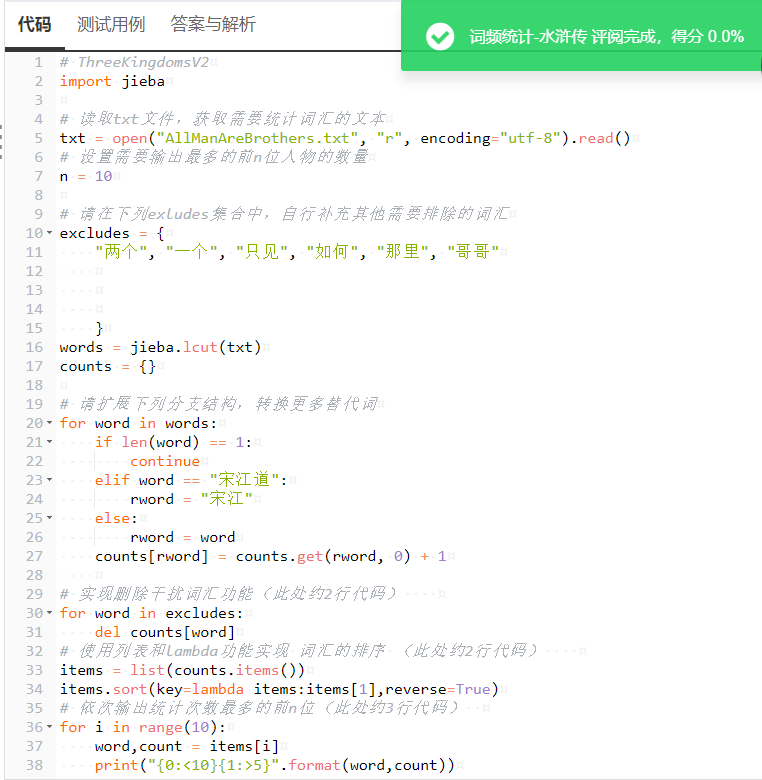

经过多次尝试,终于补全了需要排除的词汇,代码如下。
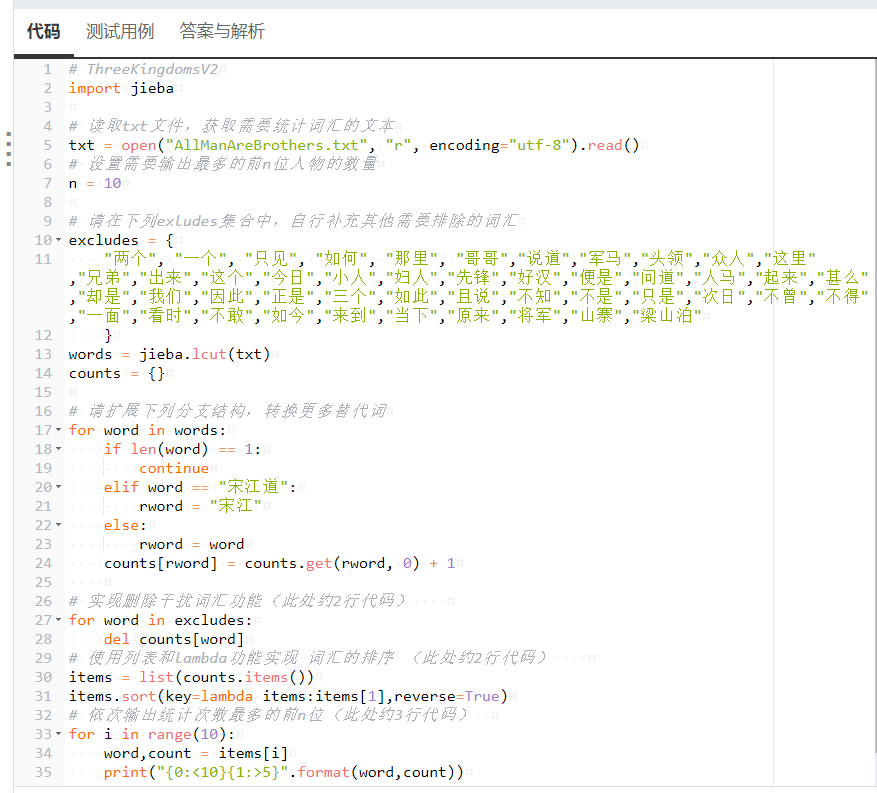
运行结果:
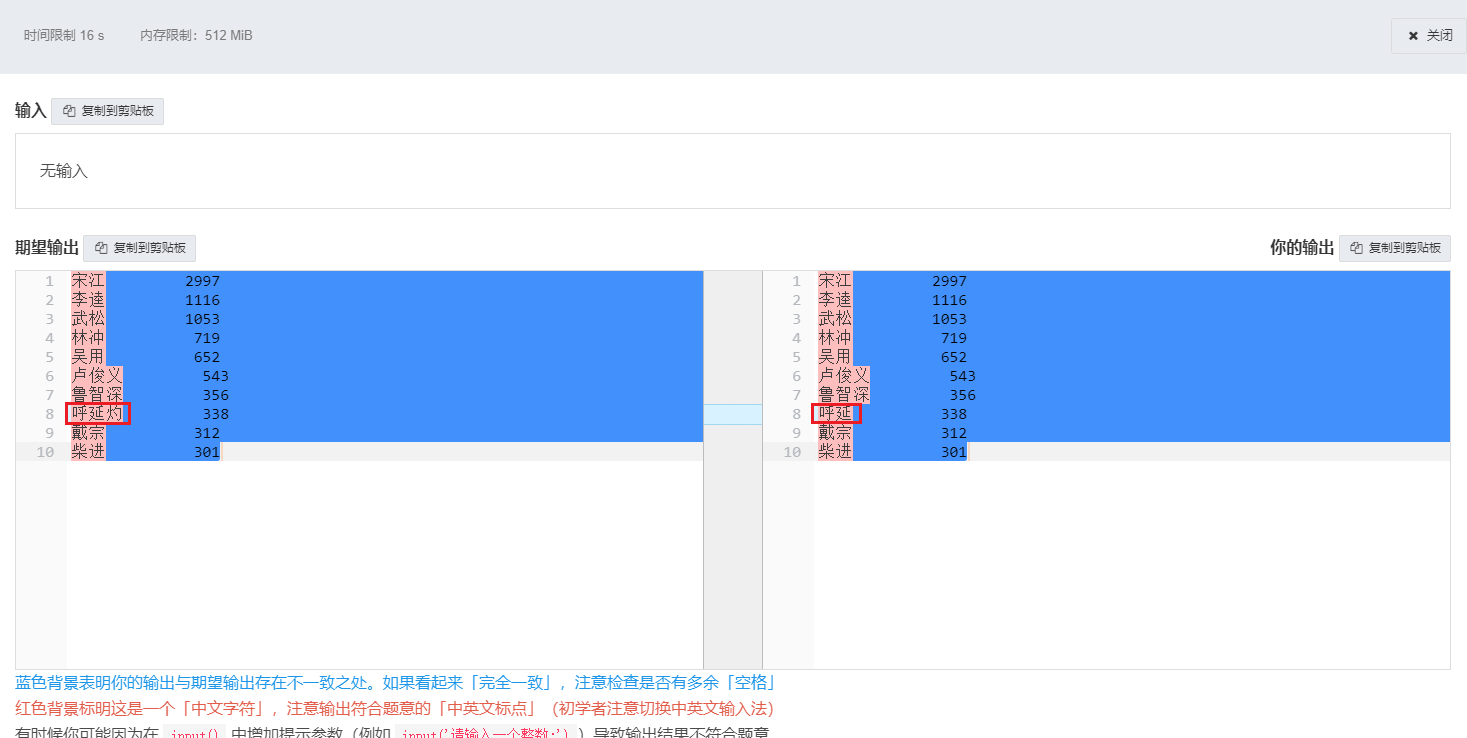
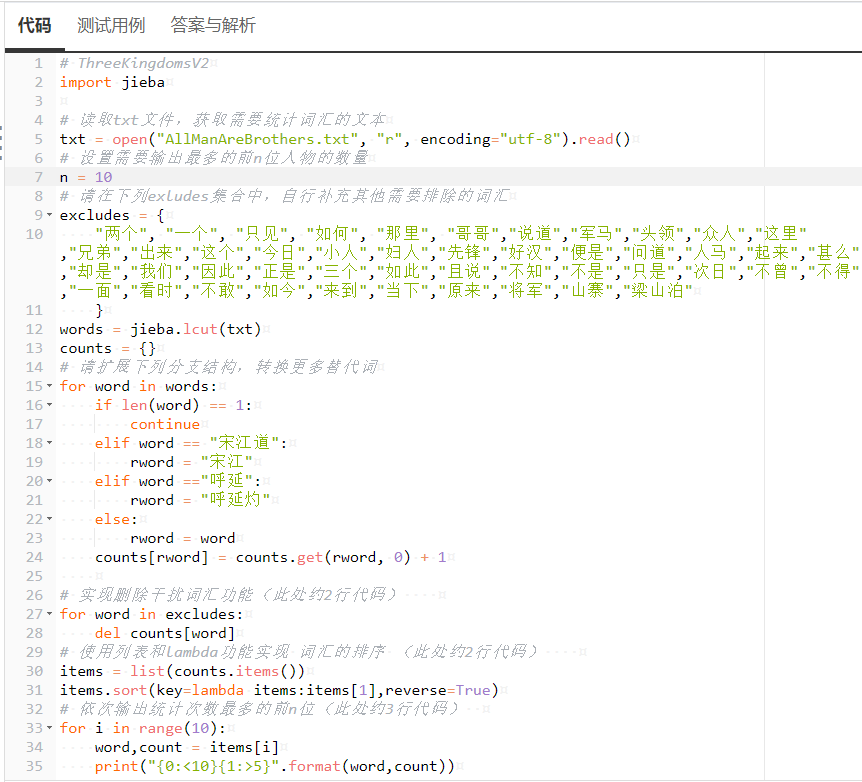
修改后最终得到正确代码。

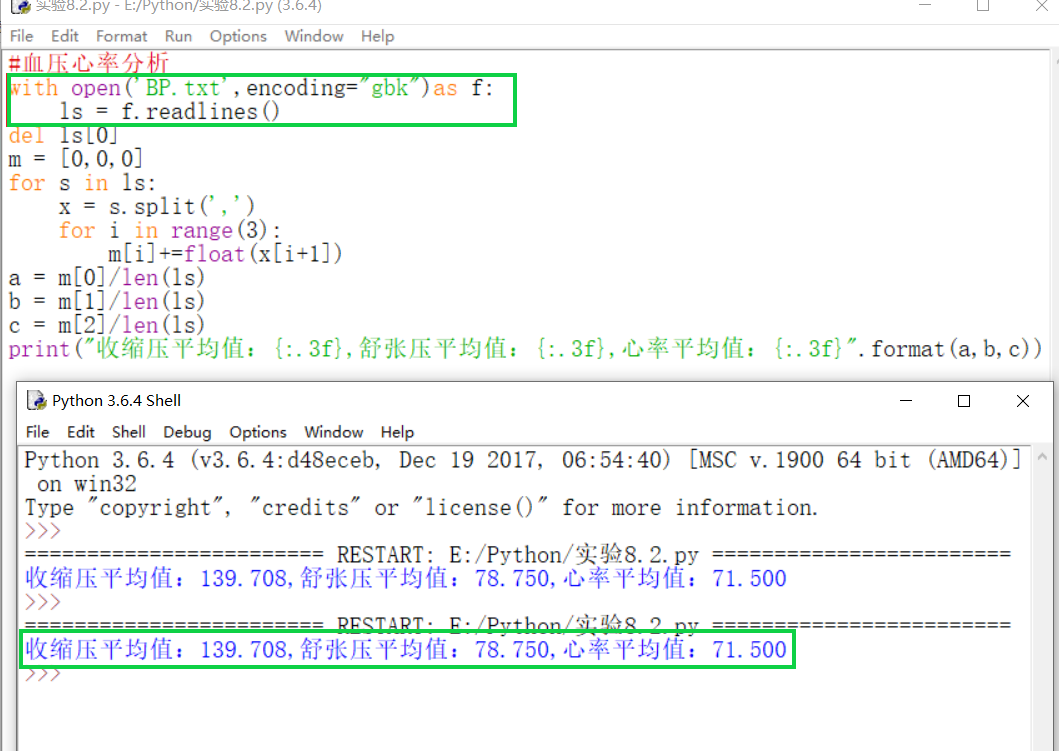
2)血压心率分析
根据提示,加上反复琢磨课本,终于在IDLE上完成了代码。
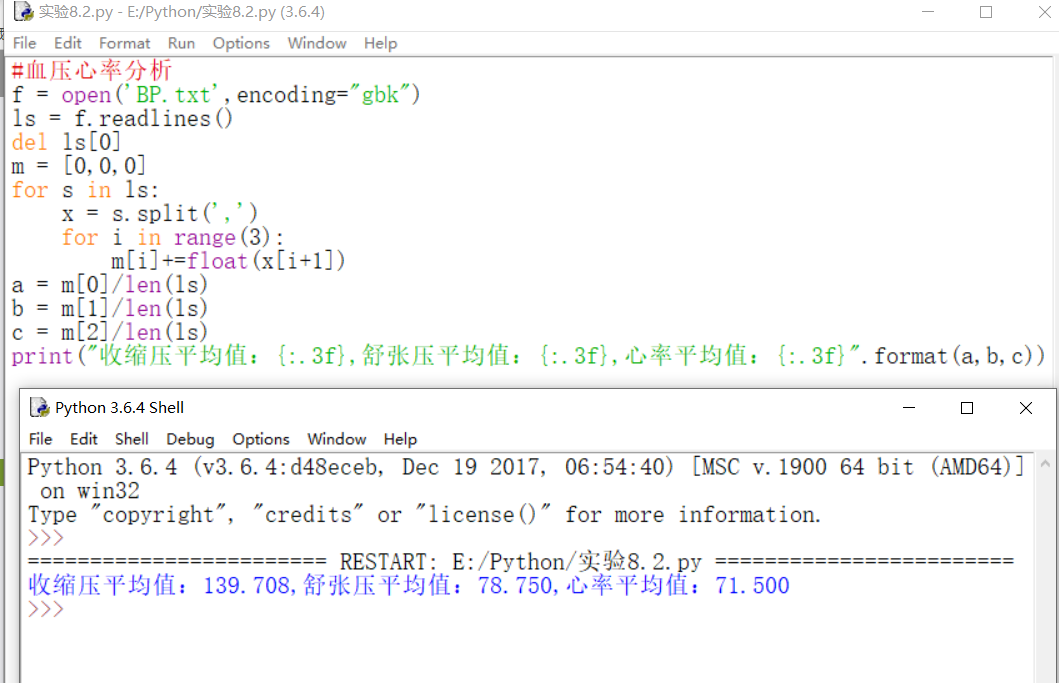
输入到Python123中,结果也正确。
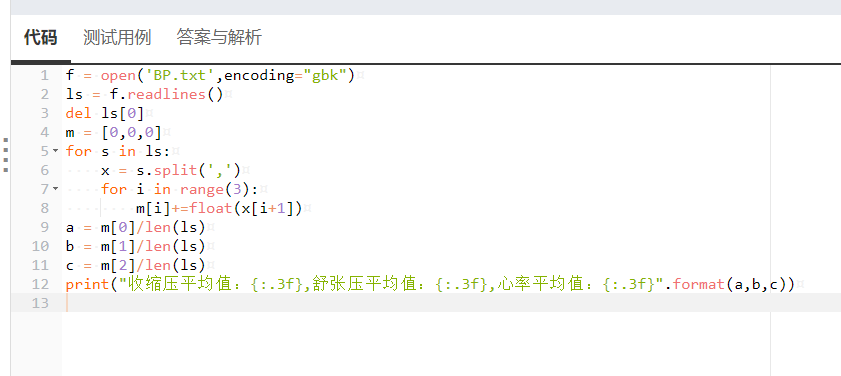
但是看到有同学用 with open()as <>:语句,出于好奇,我也尝试了一下。
发现结果也是正确的。
于是,百度了一下它们的区别。
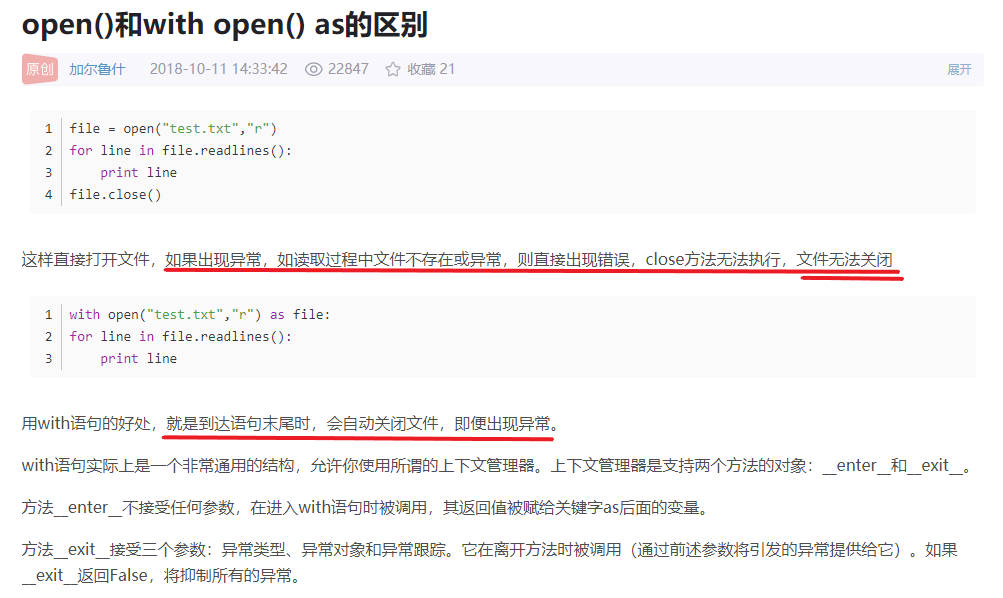

当文件出现异常时,用open()语句打开的文件会无法关闭,而用with open()as <>:语句打开的文件可以关闭。
相较之下,with open()as <>:语句更加保险安全。
总结:本次实验过程还算顺利,看书结合模板可以写出来,但这恰恰说明其实还是有许多不懂不熟,希望再接再厉。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号