python-爬取网页
爬虫简介
网络蜘蛛,网络机器人,抓取网络数据的程序
其实就是用Python程序模仿人点击浏览器并访问网站,而且模仿的越逼真越好
目的
公司业务所需数据
公司项目测试数据
法律法规
爬取的属于开放数据不能涉及个人信息或商业机密
没有侵入性,不破坏网站正常运行(不能频繁爬取导致网站瘫痪)
没有实质性替代被爬者提供的产品或服务(例如不能爬取别人的文章或视频在别处牟利)
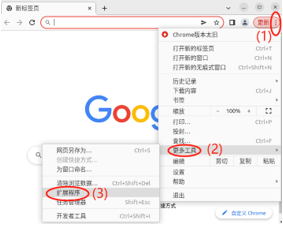
XPathHelper(谷歌用于解析XPath表达式的插件)
下载好XPathHelper==>打开Chrome浏览器==>设置==>更多工具==>扩展程序==开发者模式==加载已解压的扩展程序==>重启浏览器
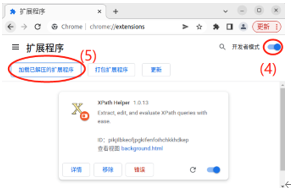
使用方法选定内容后右键检查,Ctrl + Shift + X 启动XPathHelper,在左边参照开发者窗口写Xpath表达式,右边比对结果是否正确
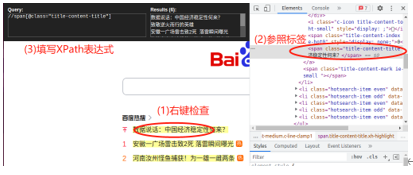
XPath表达式子
可以在html中定位标签的字符串
语法:
// 从任意位置的标签中查找
例//div 查找的是页面中所有的div标签
例//div 查找的是页面中所有的div标签
标签名 标签名查找要给出查找路径
例/html/body/div/ul/ 查找到的是层级在/html/body/div/里面的ul标签
@ 选取属性(按标签带有的属性查找)
例//div[@class="nev"] 查找的是页面中所有类名为nev的div标签
例//div[@class="search_nav clearfloat"]/ul/li查找的是页面中带有类名search_nav clearfloat的div的ul/li路径下的li标签
标签名[数字] 查找同一层级标签的第几个,1为第一个
例//div[@class="search_nav clearfloat"]/ul/li[3]查找的是页面中带有类名search_nav clearfloat的div的ul/li路径下的li标签中的第三个(注要li都同属于同一个父标签才可行)
. 选取当前节点(用于代码中从当前的节点往下继续搜索)
|两个表达式的并集,相当与"或"
selenium
简介
web网站自动化测试工具,通过编写自动化程序,模拟人在浏览器中操作网页,从网页获取信息
原理

安装selenium
在命令行安装Python库:
Linux操作系统:sudo pip3 install selenium -i https://pypi.douban.com/simple/
Windows:python -m pip install selenium -i https://pypi.douban.com/simple/
安装浏览器驱动chromedriver
根据浏览器版本下载驱动(选择与自身浏览器版本最最相近的版本)
http://npm.taobao.org/mirrors/chromedriver(浏览器驱动下载网址)
驱动下载完成后
Linux安装
下载后提取到主目录
使用命令拷贝到/usr/bin/目录下:sudo cp chromedriver /usr/bin/
添加权限:sudo chmod 777 /usr/bin/chromedriver
Windows
把解压后文件拷贝到python安装目录的Scripts目录下
查看python安装目录(cmd命令行):where python
打开浏览器
普通浏览器(会打开浏览器页面)
from selenium.webdriver import Chrome (固定写法,Chrome可换成ie,Firefox等浏览器,现在用的是谷歌浏览器驱动古是Chrome) with Chrome() as driver: driver.get("网址")
无界面浏览器(不会打开浏览器页面)
from selenium.webdriver import Chrome,ChromeOptions option = ChromeOptions() option.add_argument("--headless") with Chrome(options=option) as driver: driver.get("网址")
操作浏览器
# 强制等待 import time time.sleep(数值) # 滑动滚动条 driver.execute_script("window.scrollBy(数值,数值)")
定位html标签
from selenium.webdriver.common.by import By # 查找单个元素,结果类型为WebElement 标签 = driver.find_element(By.XPATH, 'XPath表达式') # 查找多个元素,结果类型为list[WebElement] 标签列表= driver.find_elements(By.XPATH, 'XPath表达式')
操作html标签
# 获取标签文本 结果 = 标签.text
# 获取标签属性值 结果 =标签.get_attribute("属性名")
# 模拟鼠标单击 标签.click() # 模拟键盘输入 标签.send_keys("内容") # 清空输入框值 标签.clear() # 模拟特殊按键 from selenium.webdriver.common.keys import Keys 标签.send_keys(Keys.ENTER)
反爬与反反爬
反爬机制:网站通过相应的策略或技术,防止爬虫获取数据
反反爬策略:分析网站反爬策略或技术,破解反爬获取数据
# 3. 反反爬浏览器 import os from selenium.webdriver import Chrome, ChromeOptions options = ChromeOptions() dir = r"C:\Users\%s\AppData\Local\Google\Chrome\User Data" % os.getlogin() # Windows dir = "/home/%s/.config/google-chrome" % os.getlogin() # Linux options.add_argument("user-data-dir=" + dir) # 设置用户数据目录 options.add_argument("--disable-blink-features=AutomationControlled") # 禁用启用Blink运行时的功能 options.add_experimental_option("excludeSwitches", ["enable-automation"]) # 去除浏览器检测框 with Chrome(options=options) as driver: driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", { "source": """ Object.defineProperty(navigator, 'webdriver', { get: () => undefined }) """}) # 再次覆盖window.navigator.webdriver的值 driver.get("网址")
Pandas-python数据分析工具
江湖流传一句话:分析不识潘大师(Pandas),纵是老手也枉然
Python数据分析工具,可以完美代替Excel完成除单元格样式设置外的所有功能
安装 在命令行安装Python库: Linux操作系统:sudo pip3 install pandas -i https://pypi.douban.com/simple/ Linux操作系统:sudo pip3 install openpyxl -i https://pypi.douban.com/simple/ Windows:python -m pip install pandas -i https://pypi.douban.com/simple/
Windows:python -m pip install openpyxl -i https://pypi.douban.com/simple
使用pandas将数据放入表格
from pandas import DataFrame # list_result 为列表,里面元素是字典,转换为xlsx表格后,字典的键为列名,字典的值为表格每一行 DataFrame(list_result).to_excel("游戏信息.xlsx", index=False)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号