何恺明MAE论文简解
MAE这篇论文在2022年发表,当年比较火。
起因是nlp一直有非常棒的预训练模型,比如bert。那么cv能不能仿照一下也得到很棒的模型呢?
为此,研究开始了。
参考资料:https://zhuanlan.zhihu.com/p/439554945
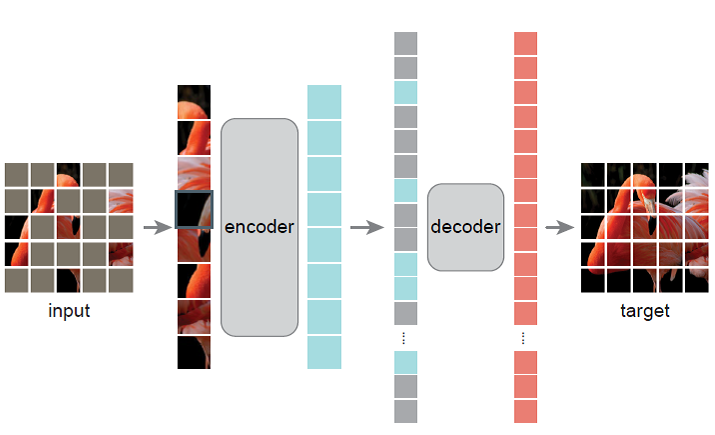
模型的结构简单易懂,就是mask一些像素块,将没有mask的像素块作为encoder的输入,输出的特征再补充一些mask特征,作为解码器的输入,最后输出重构图像。这样模型就可以学到信息密度相当高的潜在表示,可以使用encoder作为特征提取层。
作者用了一个非对称结构,encoder的参数量远大于decoder,毕竟希望得到的是encoder,decoder只是附带品,这一点很好理解。
其次,又有人讨论,这和以往的进行遮挡的数据增广有什么区别呢?
从目的上来讲,遮挡数据增广也就是cutout,其实就是drop out的一种,是强行把一些像素失活,置为某个值,这样做的好处主要是防止过拟合。但也有一个坏处,就是生成的特征特别容易受到这些失活的像素干扰,训练效果反而很差。这个问题grid mask有讲过,详情可以看https://arxiv.org/abs/2001.04086
而MAE有没有将一些特征失活呢?至少在编码器阶段是没有的,这意味编码器生成的特征不会受到失活的像素干扰,还能生成一些密度相当高的潜在表示。但是仔细看解码器阶段,又把这些失活的特征补上了,所以解码器阶段是极有可能会受到失活像素干扰。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号