多线程以rtsp流调用多路海康摄像头的思考
如题,我使用了多线程,以rtsp流调用多路海康摄像头。使用了opencv作为拉流库,但是结果不如人意。
当摄像头数增加时,cpu占用率变化不大,但是却出现了卡顿。当增大到5个时,甚至发生崩溃。
我使用了千兆光纤网,显然不是带宽问题。
那会不会是imshwo显示久了不更新呢,显然不是。接受速度快于显示时会发生这个现象,startWindowThread()可以解决这个问题。
我的猜测有两个:
1.cpu亲和性问题,可能只逮着一个cpu调用了。
2.opencv的拉流问题,我猜测是 多路的时候仍然共享某些未知的资源,因此会互相争抢和阻塞,最终导致某一路被停滞时间过长,rtsp流服务断掉崩溃。
一、cpu亲和性
win下的线程的cpu亲和性,可以通过SetThreadAffinityMask来设置。
linux下则需要pthread中的pthread_setaffinity_np来设置。
在win下我设置了线程的cpu亲和性,但是问题并没有得到解决,甚至效果还不如不设置的时候。
所以我猜测,操作系统本身就会为线程分配cpu,内部有一套调度逻辑,为了验证这个猜想,我设计了一个试验。
通过开多个线程,观察他们是否调用同一个cpu。用到了下面的这个cpp:
#include <opencv2/opencv.hpp>
#include <opencv2/imgproc.hpp>
#include <opencv2/highgui.hpp>
#include <pthread.h>
#include <windows.h>
#include <iostream>
#include <stdio.h>
using namespace cv;
DWORD GetThreadAffinityMask()
{
DWORD mask = 1;
DWORD old = 0;
// try every CPU one by one until one works or none are left
while (mask)
{
old = SetThreadAffinityMask(GetCurrentThread(), mask);
if (old)
{ // this one worked
SetThreadAffinityMask(GetCurrentThread(), old); // restore original
return old;
}
else
{
if (GetLastError() != ERROR_INVALID_PARAMETER)
return 0; // fatal error, might as well throw an exception
}
mask <<= 1;
}
return 0;
}
void* video_thread(void* arg)
{
std::string* str = (std::string*)arg;
VideoCapture cap;
cap.open(*str);
if (!cap.isOpened())
{
return NULL;
}
while (1)
{
clock_t st = clock();
Mat img;
cap >> img;
if (img.empty())
{
break;
}
std::cout<<*str << " " << GetThreadAffinityMask()<<"time:"<<clock()-st<<std::endl;
imshow(*str,img);
cv::waitKey(1);
}
return NULL;
}
int main()
{
pthread_t th1,th2,th3;
std::string str1("C:\\Users\\lvdon\\Desktop\\other\\lane_video\\1.avi");
std::string str2("C:\\Users\\lvdon\\Desktop\\other\\lane_video\\2.avi");
std::string str3("C:\\Users\\lvdon\\Desktop\\other\\lane_video\\3.avi");
pthread_create(&th1,NULL, video_thread,&str1);
pthread_create(&th1, NULL, video_thread, &str2);
pthread_create(&th1, NULL, video_thread, &str3);
while (1)
{
;
}
}
给出的结果是65535,我的电脑是16核心数,没有超线程,也就是对所有的cpu程序亲和,所以并不是因为cpu亲和性问题导致卡顿。
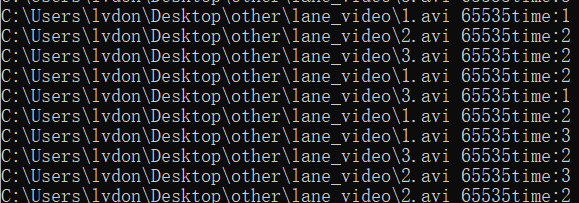
二、opencv拉流
opencv拉流依赖于ffmpeg库。
我通过降低码率、分辨率,确确实实地提高了运行速度,但我仍然不知道内部发生了什么?因为他的cpu使用率还是很低。
以下两篇也是通过类似的方式来解决这个问题,但是到底是不是如我猜测那样,我根本就不知道。
https://zhuanlan.zhihu.com/p/536225346
https://www.5axxw.com/questions/simple/borrkz

 浙公网安备 33010602011771号
浙公网安备 33010602011771号