度量学习(对比学习)
我一直在思考人脸匹配的1:1、1:N是如何做到的。首先,要做到识别出人脸;其次,在这基础上,要分辨出不同的人。
这是一个很有趣的东西。人脸类和非人脸类之间要有区分,人脸类内部的不同人之间也要有区分。
以前看到细粒度识别,其实度量学习和细粒度识别有着千丝万缕的关系,但我们暂且不谈。
来源:(29条消息) 多元组损失整理(二元组损失、三元组损失、四元组损失)_wangs1996的博客-CSDN博客
深度对比学习和度量学习中的损失函数 - 哈哈哈喽喽喽 - 博客园 (cnblogs.com)
1.二元组损失(对比损失)
![]()
Dw是数据对特征的欧式距离;Y用于表示是否同类,同类表示为0, 不同类表示为1;m是一个阈值。
二元组损失中包含了一个max函数,有一点focal loss的思想。简单来说就是对于已经易分的样本对,不必再学习;更聚焦于难分的样本对。
如果不设置这样的max函数,有可能会发生这样的事:易分样本差距越来越大,难分样本差距不变甚至缩小。
2.三元组损失
![]()
这是度量学习最为经典的损失函数,脱胎于对比损失,并被发扬光大。对于三种样本对有:
- Easy Triplets:d(a,n)>d(a,p)+margin 。负样本的距离已经大于正样本的距离,且满足间隔裕量margin。此时损失L为 0。
- Hard Triplets:d(a,n)<d(a,p) 。负样本的距离比正样本的距离还小,此时损失L大于margin。
- Semi-Hard Triplets:d(a,p)<d(a,n)<d(a,p)+margin 。负样本的距离虽比正样本大,但不满足间隔裕量margin。此时损失L大于0,但小于margin。
3、center loss
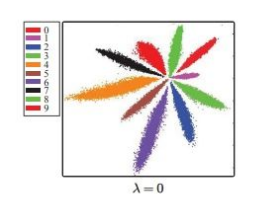

简单来说就是把左图的空间,变为右图---可以用范数度量的特征空间。
作者通过引入中心损失惩罚函数,来实现这种转变。
该损失包含softmax和center loss。m特指mini-batch的训练样本数。

理论上,每次参数更新后,都要将整个训练集前向传播一遍得到所有特征向量,然后对每个类别求平均,从而计算新的 center ,不过计算量过大,实际上是操作不了的。文章提出的方法是,在每个mini-batch中计算类别中心,并通过一个学习率a来调整当前的类别中心,如下所示:
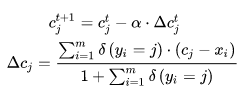

 浙公网安备 33010602011771号
浙公网安备 33010602011771号