维度灾难及超参数寻优(高斯过程)
一、维度灾难
维度灾难指的是当样本维度过高时,发生过拟合,验证集结果变差。
样本维度越高,能够提供的信息就越多,但是其中有可能会提供一些无关的信息。
而且随着维度越高,样本集在高维空间就会出现稀疏性,简单来说,就是需要更多的样本来填补这个空间。
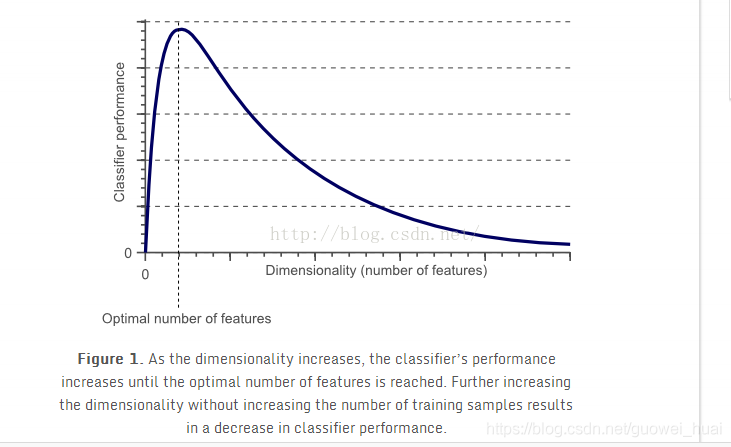
上图所示,纬度高确实能带来一定提升,但是如果过高,就会发生维度灾难。
解决维度灾难的方法是降维或者采用一些泛化能力强的分类器,如线性分类器等。
二、超参数寻优
如何在超参数中寻找一组合适的组合,改善模型性能是每位炼丹师的目标。
我之前一直在思考使用正交实验、极差分析的方法来进行寻优,因为这个思路比较简单,肯定会有人做,结果我发现了这篇博客:
(40条消息) 机器学习调参——通过正交实验进行机器学习超参数调整的尝试_CubDonkey的博客-CSDN博客
相交于网格搜索、随机搜索要强,但是这种方法仍然要使用较多的实验组合,比较浪费时间。
比较受推崇的是贝叶斯优化:
贝叶斯优化/Bayesian Optimization - 知乎 (zhihu.com)
贝叶斯优化问题相当复杂,需要理解高斯过程,而高斯过程的推导也很复杂,在B站的白板推导中有介绍:
机器学习-白板推导系列(二十)-高斯过程GP(Gaussian Process)_哔哩哔哩_bilibili
简而言之,就是下面这一段话,Y是观察值,X是预测值。其寻优规则为通过观察值Y给出预测值X*,预测出最大值(不确定度+预测均值),观察该值,将该值加入Y中,重复流程。

舒尔补公式求高斯过程后验表达式:
(41条消息) 标准高斯过程回归(Gaussian Processes Regression, GPR)从零开始,公式推导_今天也是睡觉的一天的博客-CSDN博客


补充说明一下 协方差的行列式为先验、后验协方差行列式的乘积:
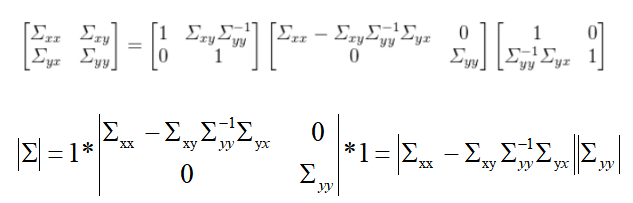
另外给出一段高斯过程的代码,转载别人,修改了一下:
(3 封私信) 如何通俗易懂地介绍 Gaussian Process? - 知乎 (zhihu.com)
import matplotlib.pyplot as plt import numpy as np from scipy import interpolate import pylab as pl #高斯核函数 Beta=1.0 def gaussian_kernel(x1,x2,l=0.5,sigma_f=0.2): x1=np.array(x1) x2=np.array(x2) m, n = x1.shape[0],x2.shape[0] dist_matrix = np.zeros((m,n),dtype=float) for i in range(m): for j in range(n): dist_matrix[i][j]= np.sum((x1[i]- x2[j])** 2) return sigma_f ** 2 * np.exp(- 0.5 / l** 2* dist_matrix) #生成观测值,取sin函数没有别的用意,单纯就是为了计算出Y def getY(X): X = np.asarray(X) Y = -np.power(X-6,2)*0.1+ np.random.normal(0,0.01, size=X.shape) return Y.tolist() #根据观察点X,修正生成高斯过程新的均值和协方差 def update(Y,X,X_star,EX,EX_star): X = np.asarray(X) X_star = np.asarray(X_star) Y=np.array(Y).reshape(-1,1) EX=np.array(EX).reshape(-1,1) EX_star=np.array(EX_star).reshape(-1,1) K_YY = gaussian_kernel(X,X) # K(X,X) K_ff = gaussian_kernel(X_star,X_star) # K(X*,X*) K_Yf = gaussian_kernel(X,X_star) # K(X,X*) K_fY = K_Yf.T # K(x*,x)协方差矩阵是对称的,因此分块互为转置 K_YY_inv = np.linalg.inv(K_YY + 1e-8 * np.eye(len(X))) #(N,N) mu_star = K_fY.dot(K_YY_inv).dot(Y-EX)+EX_star cov_star = K_ff - K_fY.dot(K_YY_inv).dot(K_Yf) return mu_star.ravel().tolist(),cov_star f, ax = plt.subplots(3,1, sharex=True,sharey=True) #绘制高斯过程的先验 x_list=[1,2,5,9] Ex_list=[0,0,0,0] x_star_list=[x*0.1 for x in range(0,100)] Ex_star_list=[0 for x in range(0,100)] cov_star=gaussian_kernel(x_star_list,x_star_list) uncertainty=1.96 * np.sqrt(np.diag(cov_star)) ax[0].fill_between(x_star_list, Ex_star_list+ uncertainty,Ex_star_list - uncertainty, alpha=0.1) ax[0].plot(x_star_list,Ex_star_list,label="expection") ax[0].legend() #绘制基于观测值的高斯过程后验 y_list=getY(x_list) Ex_star_list,cov_star=update(y_list,x_list,x_star_list,Ex_list,Ex_star_list) uncertainty=1.96 * np.sqrt(np.diag(cov_star)) ax[1].fill_between(x_star_list, Ex_star_list+ uncertainty,Ex_star_list - uncertainty, alpha=0.1) ax[1].plot(x_star_list,Ex_star_list,label="expection") ax[1].scatter(x_list,y_list,label="observation point", c="red", marker="x") ax[1].legend() #寻优 P=[x_star_list[0],Ex_star_list[0]+ Beta*uncertainty[0]] Ex_list=[] for m,n in zip(x_star_list,Ex_star_list+ Beta*uncertainty): if P[1]<n: P[1]=n P[0]=m x_list.append(P[0]) f1=interpolate.interp1d(x_star_list , Ex_star_list , kind=1) for m in x_list: Ex_list.append(f1(m)) y_list=getY(x_list) Ex_star_list,cov_star=update(y_list,x_list,x_star_list,Ex_list,Ex_star_list) uncertainty=1.96 * np.sqrt(np.diag(cov_star)) ax[2].fill_between(x_star_list, Ex_star_list+ uncertainty,Ex_star_list - uncertainty, alpha=0.1) ax[2].plot(x_star_list,Ex_star_list,label="expection") ax[2].scatter(x_list,y_list,label="observation point", c="red", marker="x") ax[2].legend() plt.show()
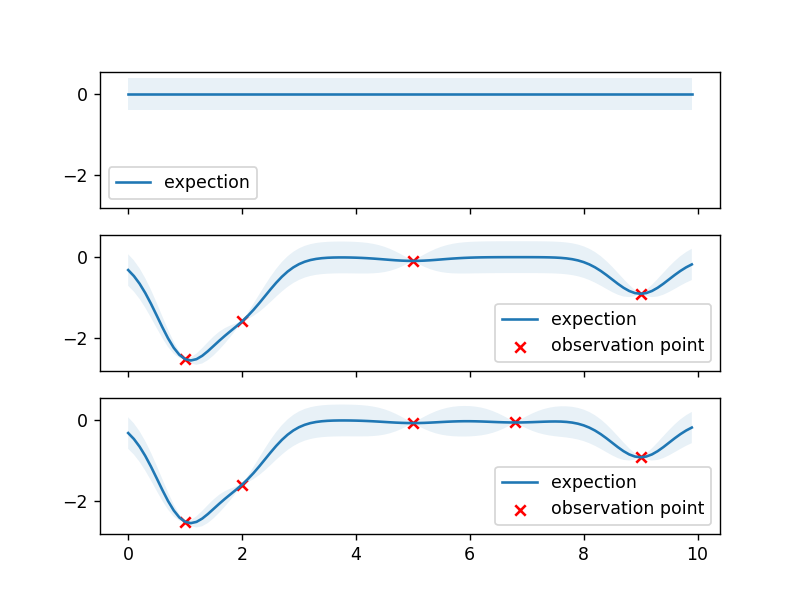
朝未探索的地方取值
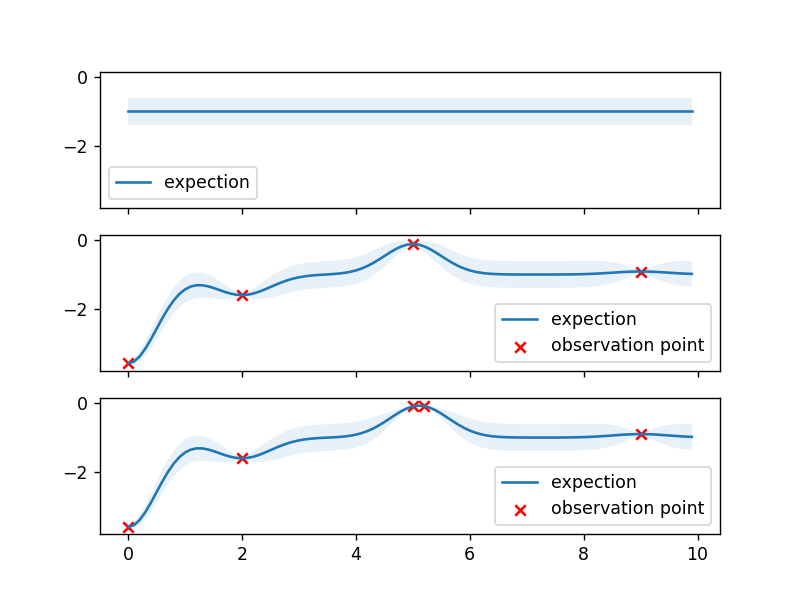
朝最大方向取值

 浙公网安备 33010602011771号
浙公网安备 33010602011771号