seq2seq中的注意力机制
seq2seq中的注意力机制解决了长期梯度消失的问题,LSTM只解决了一部分长短期问题。
transformer中采用的自注意力机制多少借鉴该方法,其最核心的公式如下图所示。
Attention机制详解(一)——Seq2Seq中的Attention - 知乎 (zhihu.com)
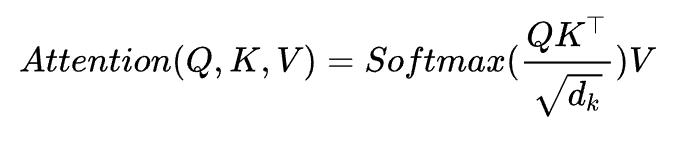
Q、K、V分别代表询问、键值以及数据值,本质就是根据输入的x分配权值,关注更有意义的部分。Q、K、V其实都是从同样的输入矩阵X线性变换而来的。我们可以简单理解成:
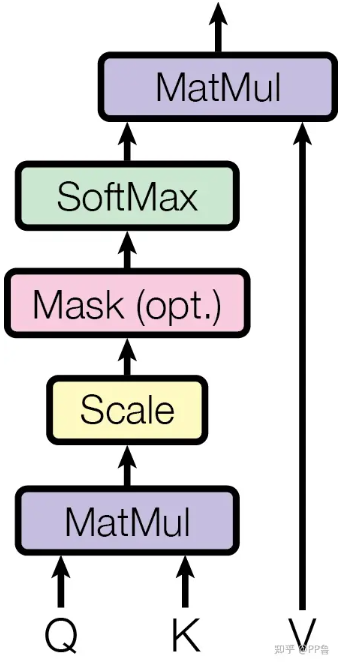
在这张图中,与
经过MatMul,生成了相似度矩阵。对相似度矩阵每个元素除以
,
为
的维度大小。这个除法被称为Scale。当
很大时,
的乘法结果方差变大,进行Scale可以使方差变小,训练时梯度更新更稳定。方差过大容易导致softmax结果非0及1,梯度更新后会造成结果振荡 ,不利于梯度稳定更新。
Properties of Dot Product of Random Vectors - 知乎 (zhihu.com)
此外,为了便于理解,提供了seq2seq的pytorch实现。
PyTorch实现Seq2Seq机器翻译 - 那少年和狗 - 博客园 (cnblogs.com)
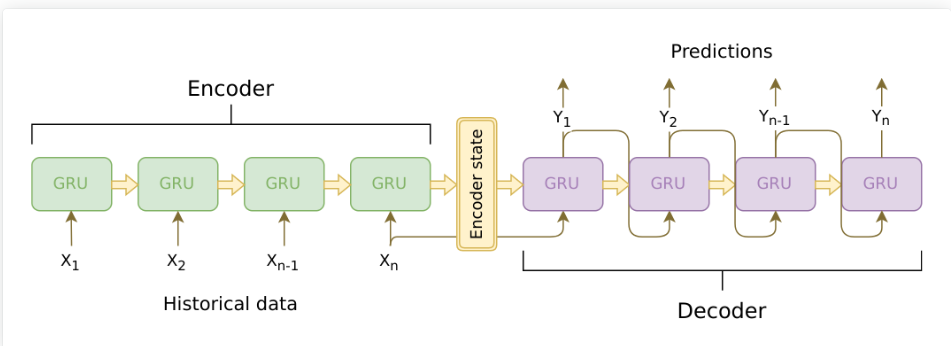
seq2seq的基本架构如图所示,可以通过输入不定长的序列,输出不定长的序列。Seq2Seq在训练阶段和预测阶段稍有差异。如果Decoder第一个预测预测的输出就错了,它会导致“蝴蝶效应“,影响后面全部内容。为了解决这个问题,在训练时,Decoder每个时间步的输入不全是上一个时间步的输出,而以一定的概率选择真实值作为输入。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号