扩散模型的观后感
近期不得不提的AI作画,实在是太火了。因此,跑去看了diffusion model的基本原理,公式推导比较难。
大概意思上,分为两个步骤。一是训练过程,给定时间迭代步和包含噪声的图,要求模型能够推理出噪声,并采用mseloss反向传播。二是逆扩散过程,从一个完全的噪声图开始,不断迭代模型求取出一部分过程噪声,将纯噪声图还原成高清图。
推荐看看这篇博文,讲的很好,基本不需要再看其他文章:
Diffusion Models:生成扩散模型 - 知乎 (zhihu.com)
一,为何逆扩散过程从一个完全的噪声图开始?
实际上,我觉得从一个包含部分噪声的图开始是最好的,这样既能保证生成的多样性,又能保证结果不是单纯随机的。事实上,很多AI作画除了输入随机变量外,都会要求输入一些标签或者原始图,所以原论文的做法应该是不那么好的。
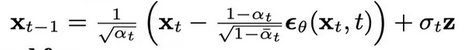
二,扩散过程中,噪声系数beta为什么要取一个很小的值?beta为什么要随时间步慢慢变大?
如果不取一个很小的数,在10步以内,高清图就会变成一张纯噪声图。我想如此激烈的变化,应该是不便于模型学习的吧。
除此以外,为了防止生成的总的噪声的均值、方差过于大或小,论文还引入了sqrt(1-beta)。
beta还是一个超参数,应当随着时间步慢慢增大,这样后加入的噪声成分总是会大于前者。Zt为时间t加入的噪声。
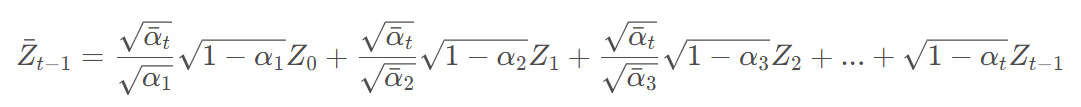
![]()
![]()
因此,
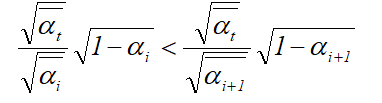
三、损失函数的求取。
扩散模型损失函数的求取耐人寻味。
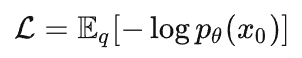
作者给出了这样一个交叉熵公式,意思是求取原始图像和经过逆扩散后生成图像的差异。(该交叉熵不可能小于0)
但是该值不好求取,因此,作者就想到了求取该值的上界。通过最小化上界,来使得交叉熵足够小。
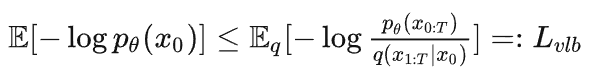
也就是最小化Lvlb。
该值又可以被简化为,最终得mseLoss(均方误差)。
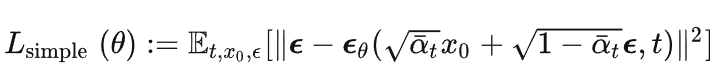

 浙公网安备 33010602011771号
浙公网安备 33010602011771号