python读取csv编码问题
python读取csv编码问题
主要参考https://www.cnblogs.com/shengulong/p/7097869.html
https://www.cnblogs.com/buptldf/p/4805879.html
首先对相关编码进行简单的介绍:
ASCII码
由于计算机只能处理数字,当处理文本时,需要将文本转换为数字。
最早计算机设计采用8比特作为一个字节,所以一个字节所表示最大的整数为255。0-255被用来表示大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码。比如大写的英文字母A编码为65,小写的英文字母z编码为122。
如果要表示中文,显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
GB 2312的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率。
GBK 向下与 GB 2312 编码兼容, GBK是采用单双字节变长编码,英文使用单字节编码,完全兼容ASCII字符编码,中文部分采用双字节编码。
Unicode编码
Unicode当然是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样。
UTF-8
为了提高Unicode的编码效率,于是就出现了UTF-8编码。UTF-8可以根据不同的符号自动选择编码的长短。
由于字符编码种类非常多,因此Excel有选择性的支持了ANSI(微软自已的)和UNICODE(大而全),不支持UTF-8很正常。记事本支持UTF-8编码。
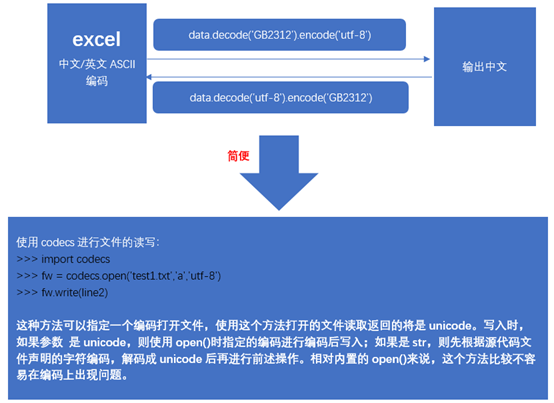
excel打开csv文件,可以识别编码"GB2312",但是不能识别"utf-8",数据库里的字符串编码是utf-8.因此:
当从csv读取数据(data)到数据库的时候,需要先把GB2312转换为unicode编码,然后再把unicode编码转换为utf-8编码:data.decode('GB2312').encode('utf-8')
用gb2312编码的csv文件,再notepad++打开如果为乱码的话,需要将Notepad++中的字符编码修改为中文;
如果在csv中,采用的是unicode编码,则打开Notepad++无任何问题