LSTM:在Python中使用PyTorch使用LSTM进行时间序列预测
原文链接:
https://stackabuse.com/time-series-prediction-using-lstm-with-pytorch-in-python/
时间序列数据,顾名思义是一种随时间变化的数据类型。例如,24小时时间段内的温度,一个月内各种产品的价格,一个特定公司一年的股票价格。高级的深度学习模型,如长短期记忆网络(LSTM),能够捕捉时间序列数据中的模式,因此可以用来预测数据的未来趋势。在本文中,您将看到如何使用LSTM算法使用时间序列数据进行未来预测。
Dataset and Problem Definition
我们将使用的数据集内置在Python Seaborn库中。让我们先导入所需的库,然后再导入数据集:
1 import torch 2 import torch.nn as nn 3 4 import seaborn as sns 5 import numpy as np 6 import pandas as pd 7 import matplotlib.pyplot as plt 8 %matplotlib inline
读入数据
1 import pandas as pd 2 flight_data = pd.read_csv('./data/flights.csv') #或者flight_data = sns.load_datasets("flights") 3 flight_data.head()
输出:
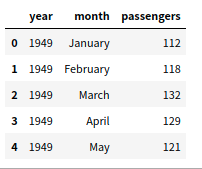
flight_data.shape
#输出: (144,3)
数据集有三列:year、month以及passengers,包含了12年的乘客出行纪录;
任务:
根据面132个月的出行数据预测后12个月的出行数据;
绘制每个月的乘客出行频率:
1 plt.plot(flight_data['passengers']) 2 plt.grid(True) 3 plt.title("Month vs passenger") 4 plt.ylabel("Total passengers") 5 plt.xlabel("Months") 6 plt.autoscale(axis='x',tight=True)
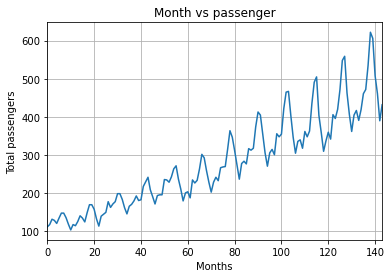
从输出结果中可以看出,每年的乘客数量是在逐渐递增的;
在同一年内,乘客的数量是波动的,这是符合常识的,因为在节假日的时候,乘客的数量相较于一年中的其他日子是会变多的;
数据预处理:
首先,看一下数据集中的列的数据类型:
1 flight_data.columns
输出:
all_data = flight_data['passengers'].values.astype(float)
接下来,将数据集划分为训练数据集和验证数据集:
test_data_size = 12 train_data = all_data[:-test_data_size] #size=132 test_data = all_data[-test_data_size:] #size=12
此时,数据集并没有经过标准化处理;
但是乘客数量在刚开始的年份要远小于近两年的数量;
我们将使用Min/max进行标准化;
1 from sklearn.preprocessing import MinMaxScaler 2 3 scaler = MinMaxScaler(feature_range=(-1,1)) 4 train_data_normalized = scaler.fit_transform(train_data.reshape(-1,1))
之后,将其转化为tensor的数据形式:
train_data_normalized = torch.FloatTensor(train_data_normalized).view(-1) #转换成1维张量
最后,就是将数据处理成sequences和对应标签的形式;
在这里,我们取时间窗口为12,因为一年有12个月,这个是比较合理的;
1 train_window=12 2 3 def create_inout_sequences(input_data,tw): 4 inout_seq = [] 5 L = len(input_data) 6 for i in range(L-tw): 7 train_seq = input_data[i:i+tw] 8 train_label = input_data[i+tw:i+tw+1] 9 inout_seq.append((train_seq,train_label)) 10 return inout_seq 11 12 train_inout_seq = create_inout_sequences(train_data_normalized,train_window)
#一共有120个样本 132-12=120
创建LSTM模型:
1 class LSTM(nn.Module): 2 def __init__(self, input_size=1,hidden_layer_size=100,output_size=1): 3 super().__init__() 4 5 self.hidden_layer = hidden_layer_size 6 self.lstm = nn.LSTM(input_size,hidden_layer_size) 7 self.linear = nn.linear(hidden_layer_size,uotput_size) 8 self.hidden_cell = (torch.zeros(1,1,self.hidden_layer_size), 9 torch.zeros(1,1,self.hidden_layer_size)) 10 def forward(self, input_seq): 11 lstm_out, self.hidden_cell = self.lstm(input_seq.view(len(input_seq),1,-1), self.hidden_cell) 12 predictions = self.linear(lstm_out.view(len(input_seq),-1)) 13 return predictions[-1]
input_size:对应的输入数据特征; 虽然我们的序列长度是12,但是对于每个月来说,我们只有1个值,例如,乘客的总数量,因此输入的size是1;
hidden_layer_size: 每层的神经元的数量,我们每层一共有100个神经元;
output_size:预测下一个月的输出数量,输出的size为1;
之后我们创建hidden_layer_size, lstm, linear 以及hidden_cell。
LSTM算法接收三个输入:之前的输入状态;之前的的cell状态以及当前的输入;
hidden_cell变量包含了先前的隐藏状态和cell状态;
lstm和linear层变量,用于创建LSTM和线性层;
在forward()算法中,使用input_seq作为输入参数,首先被传递给lstm;
lstm的输出,包含了当前时间戳下的隐藏层和细胞状态,以及输出;
lstm层的输出被传递给Linear层,预测的乘客数量,就是predictions的最后一项;
1 model = LSTM() 2 loss_function = nn.MSELoss() 3 optimizer = torch.optim.Adam(model.parameters(),lr=0.001)
1 # 模型的训练 2 epochs = 15 3 4 for i in range(epochs): 5 for seq, labels in train_inout_seq: 6 optimizer.zero_grad() 7 model.hidden_cell = (torch.zeros(1,1,model.hidden_layer_size), 8 torch.zeros(1,1,model.hidden_layer_size)) 9 10 y_pred = model(seq) 11 12 single_loss = loss_function(y_pred, labels) 13 single_loss.backward() 14 optimizer.step() 15 16 if i%2 ==1 : 17 print(f'epoch:{i:3} loss:{single_loss.item():10.8f}') 18 print(f'epoch:{i:3} loss:{single_loss.item():10.8f}')
模型的预测:
1 # 预测: 2 fut_pre = 12 3 4 test_inputs = train_data_normalized[-train_window:].tolist() 5 print(test_inputs) 6 7 model.eval() 8 for i in range(fut_pre): 9 seq = torch.FloatTensor(test_inputs[-train_window:]) 10 with torch.no_grad(): 11 model.hidden = (torch.zeros(1,1,model.hidden_layer_size), 12 torch.zeros(1,1,model.hidden_layer_size)) 13 14 test_inputs.append(model(seq).item())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号