利用LSTM自动编码器预测极端事件
原始链接:
https://towardsdatascience.com/extreme-event-forecasting-with-lstm-autoencoders-297492485037
处理极端事件预测对每个数据科学家来说是个噩梦。环顾四周,我发现了处理这个问题的非常有趣的资源。就我个人而言,我真的爱上了优步研究人员发布的方法。在他们的论文中(两种版本可以在这里和这里找到),他们开发了一种ML解决方案,用于每日预测旅行者的未来需求。他们的方法吸引了我的注意,因为它普适性、解释好、易于执行。所以我的目的是用python语言再现他们的发现。这次的挑战让我很满意,最后,我提高了自己的回归预测知识。
本文的重点:
1)开发一种稳定的方法来评估和比较Keras模型(同时避免了权值种子生成器的问题);
2)实现了一个简单和聪明的LSTM自动编码器用于新特征的创建;
3) 使用简单的技巧提高时间序列的预测预测性能(见上面的步骤);
4) 处理嵌套的数据集,即我们有属于不同实体的观察数据的问题(例如不同商店/引擎/人员等的时间序列)……在这个意义上,我们只开发一个高性能的模型!
下面我们将一步步的对其进行实现
问题定义:
在Uber,对完成行程的准确预测(特别是在特殊活动期间)提供了一系列重要的好处:
更高效的司机分配,从而减少了乘客的等待时间、预算规划和其他相关任务。
为了达到对拼车司机需求的高精度预测,优步研究人员开发了一个高性能的时间序列预测模型。他们能够用来自不同地点/城市的大量异构时间序列拟合(一次性)单一模型。这个过程允许我们提取相关的时间模式。最后,他们能够预测需求,对不同的地点/城市进行概括,优于经典的预测方法。
数据集:
为了完成这项任务,优步使用了一个内部数据集,该数据集记录了不同城市之间的日常出行,包括其他功能;即天气信息和城市级信息。他们的目的是通过过去观察的固定窗口来预测第二天的需求。
不幸的是,我们没有这类数据,所以作为Kaggle粉丝,我们选择了不错的牛油果价格数据集。该数据显示了两种不同品种的历史价格,以及在多个美国市场的销量。
我们之所这样选择是由于需要一个具有时间相关性的嵌套数据集:我们对每个美国市场都有时间序列,总共54个,如果我们为每种类型(传统的和有机的)考虑一个时间序列,这个数字将增长到108个。优步研究人员强调了这种数据结构的重要性,因为它允许我们的模型发现重要的无形关系。此外,序列之间的相关性为我们的LSTM Autoencoder在特征提取过程中带来了优势。
为了建立我们的模型,我们使用了截至2017年底的价格时间序列。2018年的前2个月被存储并用作测试集。对于我们的分析,我们也将考虑所有提供的回归变量。观察结果以微弱的频率显示,所以我们的目的是:给定一个固定的过去窗口(4周)的功能,预测即将到来的弱价格。
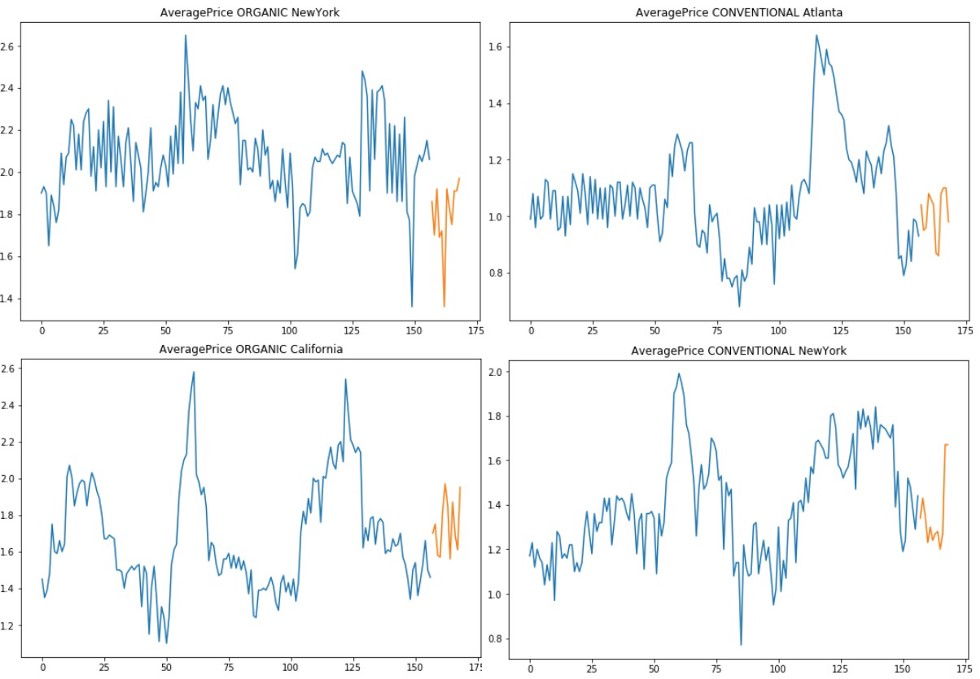
由于没有指数增长和趋势行为,我们不需要缩放我们的价格数据。
建模
为了解决我们的预测任务,我们复制了Uber提出的新的模型架构,该架构为异构预测提供了单一模型。如下图所示,模型首先通过自动特征提取对网络进行质数,训练一个LSTM Autoencoder,这对于大规模捕获复杂的时间序列动态是至关重要的。然后,特征向量与新的输入连接,并提供给LSTM Forecaster进行预测。
我们的预测工作流程很容易想象:我们有针对不同市场的每周价格(加上其他特征)的初始窗口。我们开始在它们上训练我们的LSTM自动编码器;接下来,我们删除编码器并利用它作为特性创建器。第二步也是最后一步,需要训练预测LSTM模型进行预测。基于真实/现有的回归器和之前人工生成的特征,我们可以提供下周牛油果的价格预测。
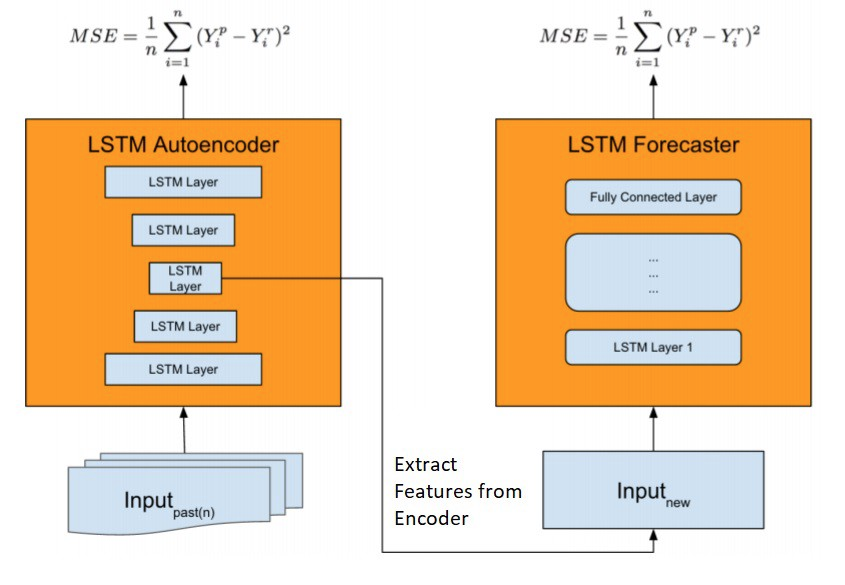
我们很容易使用Keras实现这个逻辑
我们的LSTM自动编码器由一个简单的LSTM编码器层和另一个简单的LSTM解码器组成。在评估过程中,您将了解dropout的效用,在这一点上它们是无害的,相信我!
1 inputs_ae = Input(shape=(sequence_length, n_features)) 2 encoded_ae = LSTM(128, return_sequences=True, dropout=0.5)(inputs_ae, training=True) 3 decoded_ae = LSTM(32, return_sequences=True, dropout=0.5)(encoded_ae, training=True) 4 out_ae = TimeDistributed(Dense(1))(decoded_ae) 5 sequence_autoencoder = Model(inputs_ae, out_ae)
我们计算特征提取和连接的结果与其他变量。在这一点上,我对Uber的解决方案做了一点偏差:他们建议操纵我们的编码器提取的特征向量,通过集成技术(例如,平均)来聚合它们。我决定让他们原创和自由。我做这个选择是因为它能让我在实验中取得更好的结果。
最后,预测模型是另一个简单的基于LSTM的神经网络:
1 inputs = Input(shape=(sequence_length, n_features)) 2 lstm = LSTM(128, return_sequences=True, dropout=0.5)(inputs, training=True) 3 lstm = LSTM(32, return_sequences=False, dropout=0.5)(lstm, training=True) 4 dense = Dense(50)(lstm) 5 out = Dense(1)(dense)
模型的评估
最后,我们对结果进行预测并且和其他方法进行对比。
就我个人而言,评估两种不同程序的最佳方法是尽可能多地复现它们。在这个实现中,我想展示LSTM Autoencoder作为时间序列预测相关特征创建工具的能力的证据。
在这个意义上,为了评价我们的方法的优点,我决定开发一个新的模型价格预测与我们之前的预测NN相同的结构。
它们之间唯一的区别是它们的输入特征。
第一个接收编码器输出加上回归器;
第二个变接收原始的价格加上回归器。
不确定度估计和结果
时间序列预测在本质上是至关重要的,因为它所关注的领域具有极大的变异性。此外,如果您试图建立一个基于神经网络的模型,您的结果也受制于内部权重初始化。为了克服这一缺点,存在一些不确定性估计的方法:从贝叶斯到那些基于自助理论。
在他们的工作中,优步研究人员将Bootstrap和贝叶斯方法结合起来,产生了一个简单、鲁棒和紧密的不确定性界,具有良好的覆盖和可证明的收敛性质。
这个技术非常简单实用,我们已经间接地实现了它!如下图所示,在前馈过程中,dropout应用于编码器和预测网络的所有层。因此,编码器中的随机丢失智能地干扰了嵌入空间中的输入,从而导致了潜在的模型误定,并通过预测网络进一步传播。
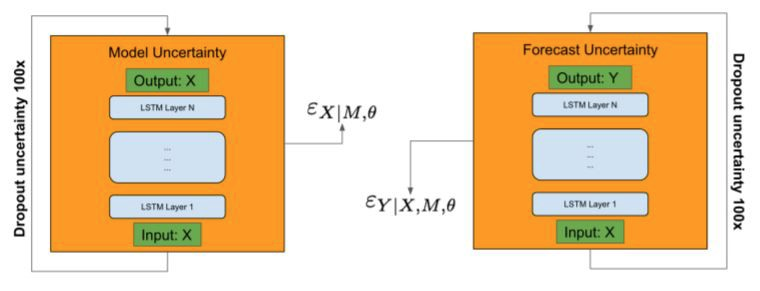
在python语言中,我们只需在我们的神经网络中添加可训练的Dropout层,并在预测过程中重新激活它们(Keras用于在预测过程中剪掉Dropout)。
对于最终的计算,必须迭代调用预测函数并存储结果。我还计算了每次交互时的预测得分(我选择了平均绝对误差)。我们必须设置计算值的次数(在我们的例子中是100次)。通过存储分数,我们可以计算MAE的平均值、标准差和相对不确定性。
我们仅用LSTM预测网络对我们的“竞争模型”复制了相同的过程。在平均分数和计算不确定性后,LSTM Autoencoder + LSTM Forecaster的最终结果优于单一的LSTM Forecaster。
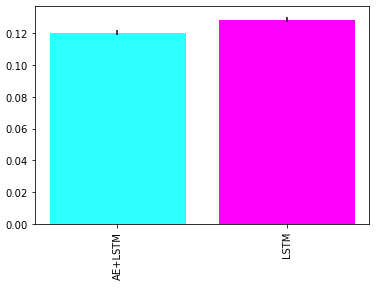
Performance (MAE) comparison on test data
总结
在这篇文章中,我复制了优步开发的用于特殊事件预测的端到端神经网络架构。我要强调的是:LSTM Autoencoder在特征提取器中的作用;该方案具有良好的可扩展性,避免了对每个时间序列训练多个模型;能够为神经网络的评估提供一种稳定和有利可图的方法。
我还指出,这种解决方案很适合当你有足够数量的时间序列共享共同的行为时……这些立即可见并不重要,Autoencoder为我们做到了这一点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号