Calech101数据集ResNet34
本博文内容:
- Caltech101数据集;
- 神经网络(模型、工具、目录)
- 编写代码
一、Caltech101数据集;
这个数据集包含了101类的图像,每类大约有40~800张图像,大部分是50张/类,在2003年由lifeifei收集,每张图像的大小大约是300x200.
图像的类别分布:
按Top40图片数量从大到小的顺序展示:
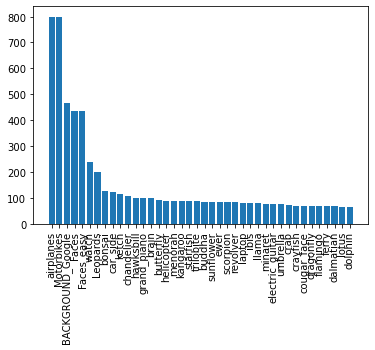
整体数据集情况:
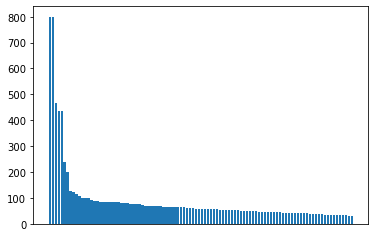
可以看到图片的数量非常不均衡;
像这样类别不均衡的图片是深度学习表现力的的主要原因之一
二、神经网络(模型、工具、目录)
网络:ResNet34
使用 ImageNet中预训练好的权重——迁移学习提高深度学习的表现力
对于隐藏层的权重,我们将不进行更新,但是我们会微调ResNet34网络的头部来支持我们的网络;
当进行微调的时候,我们同样也会加入Droput层;
如何在类别不均衡的图片上实现较高的精度
图片类别不均衡的解决方法:
1)获取更多的数据
2)使用数据增强;
在数据无法增多的情况下,数据增强效果比较好;数据增强使神经网络可以看到数据不同类型的变化,大小、角度、颜色等;
但是我们现在不使用上述两种方法,事实上,我们将采用的是迁移学习和微调神经网络来实现更高的精度;
工具:
Install PyTorch.
Install pretraindemodels. ——提供ResNet预训练模型
pip install pretrainedmodels
Install imutils ——实现图片的旋转缩放等;
pip install imutils
目录
1 ├───input 2 │ ├───101_ObjectCategories 3 │ │ ├───accordion 4 │ │ ├───airplanes 5 │ │ ├───anchor 6 │ │ ├───ant 7 │ │ ├───BACKGROUND_Google 8 │ │ ├───barrel 9 │ │ ├───bass 10 │ │ ├───beaver 11 │ │ ├───binocular 12 │ │ ├───bonsai 13 │ │ ├───brain 14 │ │ ├───brontosaurus 15 ... 16 ├───outputs 17 │ ├───models #最终训练好的模型结果 18 │ └───plots 19 └───src 20 └───train.py
- 编写代码
导入相关的包
1 # imports 2 import matplotlib.pyplot as plt 3 import matplotlib 4 import joblib 5 import cv2 #把图片读入到数据集中 6 import os 7 import torch 8 import numpy as np 9 import torch.nn as nn 10 import torch.nn.functional as F 11 import torch.optim as optim 12 import time 13 import random 14 import pretrainedmodels 15 from imutils import paths 16 from sklearn.preprocessing import LabelBinarizer 17 from sklearn.model_selection import train_test_split 18 from torchvision.transforms import transforms 19 from torch.utils.data import DataLoader, Dataset 20 from tqdm import tqdm 21 matplotlib.style.use('ggplot') 22 '''SEED Everything''' 23 def seed_everything(SEED=42): #应用不同的种子产生可复现的结果 24 random.seed(SEED) 25 np.random.seed(SEED) 26 torch.manual_seed(SEED) 27 torch.cuda.manual_seed(SEED) 28 torch.cuda.manual_seed_all(SEED) 29 torch.backends.cudnn.benchmark = True # keep True if all the input have same size. 30 SEED=42 31 seed_everything(SEED=SEED) 32 '''SEED Everything'''
超参数的设置:
定义设备、EOPCH以及batch size
1 if torch.cuda.is_available(): 2 device = 'cuda' 3 else: 4 device = 'cpu' 5 6 epochs = 5 7 BATCH_SIZE = 16
准备标签和图像
1 image_paths = list(paths.list_images('../input/101_ObjectCategories')) 2 data = [] 3 labels = [] 4 for image_path in image_paths: 5 label = image_path.split(os.path.sep)[-2] 6 if label == 'BACKGROUND_Google': 7 continue 8 image = cv2.imread(image_path) 9 image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) 10 data.append(image) 11 labels.append(label) 12 data = np.array(data) 13 labels = np.array(labels)
使用One-hot编码对label进行编码
定义图像变换
1 # define transforms 2 train_transform = transforms.Compose( 3 [transforms.ToPILImage(), 4 transforms.Resize((224, 224)), 5 transforms.ToTensor(), 6 transforms.Normalize(mean=[0.485, 0.456, 0.406], 7 std=[0.229, 0.224, 0.225])]) 8 val_transform = transforms.Compose( 9 [transforms.ToPILImage(), 10 transforms.Resize((224, 224)), 11 transforms.ToTensor(), 12 transforms.Normalize(mean=[0.485, 0.456, 0.406], 13 std=[0.229, 0.224, 0.225])])
一般只对训练数据进行数据变换;
所以我们在此分开写训练和验证的数据变换函数;
数据分割,切分为训练、验证和测试集
1 # divide the data into train, validation, and test set 2 (X, x_val , Y, y_val) = train_test_split(data, labels, 3 test_size=0.2, 4 stratify=labels, 5 random_state=42) 6 (x_train, x_test, y_train, y_test) = train_test_split(X, Y, 7 test_size=0.25, 8 random_state=42) 9 print(f"x_train examples: {x_train.shape}\nx_test examples: {x_test.shape}\nx_val examples: {x_val.shape}")
输出:
1 x_train examples: (5205,) 2 x_test examples: (1736,) 3 x_val examples: (1736,)
创建自定义数据集和Loaders
1 # custom dataset 2 class ImageDataset(Dataset): 3 def __init__(self, images, labels=None, transforms=None): 4 self.X = images 5 self.y = labels 6 self.transforms = transforms 7 8 def __len__(self): 9 return (len(self.X)) 10 11 def __getitem__(self, i): 12 data = self.X[i][:] 13 14 if self.transforms: 15 data = self.transforms(data) 16 17 if self.y is not None: 18 return (data, self.y[i]) 19 else: 20 return data 21 22 train_data = ImageDataset(x_train, y_train, train_transform) 23 val_data = ImageDataset(x_val, y_val, val_transform) 24 test_data = ImageDataset(x_test, y_test, val_transform)
1 # dataloaders 2 trainloader = DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True) 3 valloader = DataLoader(val_data, batch_size=BATCH_SIZE, shuffle=True) 4 testloader = DataLoader(test_data, batch_size=BATCH_SIZE, shuffle=False)
注意:只对训练集和验证集进行shuffle,对测试集不进行shuffle
神经网络模型搭建;
1 # the resnet34 model 2 class ResNet34(nn.Module): 3 def __init__(self, pretrained): 4 super(ResNet34, self).__init__() 5 if pretrained is True: 6 self.model = pretrainedmodels.__dict__['resnet34'](pretrained='imagenet') 7 else: 8 self.model = pretrainedmodels.__dict__['resnet34'](pretrained=None) 9 10 # change the classification layer 11 self.l0 = nn.Linear(512, len(lb.classes_)) 12 self.dropout = nn.Dropout2d(0.4) 13 def forward(self, x): 14 # get the batch size only, ignore (c, h, w) 15 batch, _, _, _ = x.shape 16 x = self.model.features(x) 17 x = F.adaptive_avg_pool2d(x, 1).reshape(batch, -1) 18 x = self.dropout(x) 19 l0 = self.l0(x) 20 return l0 21 model = ResNet34(pretrained=True).to(device)
优化器和损失函数定义
1 # optimizer 2 optimizer = optim.Adam(model.parameters(), lr=1e-4) 3 # loss function 4 criterion = nn.CrossEntropyLoss()
训练函数:
1 # training function 2 def fit(model, dataloader): 3 print('Training') 4 model.train() 5 running_loss = 0.0 6 running_correct = 0 7 for i, data in tqdm(enumerate(dataloader), total=int(len(train_data)/dataloader.batch_size)): 8 data, target = data[0].to(device), data[1].to(device) 9 optimizer.zero_grad() 10 outputs = model(data) 11 loss = criterion(outputs, torch.max(target, 1)[1]) 12 running_loss += loss.item() 13 _, preds = torch.max(outputs.data, 1) 14 running_correct += (preds == torch.max(target, 1)[1]).sum().item() 15 loss.backward() 16 optimizer.step() 17 18 loss = running_loss/len(dataloader.dataset) 19 accuracy = 100. * running_correct/len(dataloader.dataset) 20 21 print(f"Train Loss: {loss:.4f}, Train Acc: {accuracy:.2f}") 22 23 return loss, accuracy
验证函数:
1 #validation function 2 def validate(model, dataloader): 3 print('Validating') 4 model.eval() 5 running_loss = 0.0 6 running_correct = 0 7 with torch.no_grad(): 8 for i, data in tqdm(enumerate(dataloader), total=int(len(val_data)/dataloader.batch_size)): 9 data, target = data[0].to(device), data[1].to(device) 10 outputs = model(data) 11 loss = criterion(outputs, torch.max(target, 1)[1]) 12 13 running_loss += loss.item() 14 _, preds = torch.max(outputs.data, 1) 15 running_correct += (preds == torch.max(target, 1)[1]).sum().item() 16 17 loss = running_loss/len(dataloader.dataset) 18 accuracy = 100. * running_correct/len(dataloader.dataset) 19 print(f'Val Loss: {loss:.4f}, Val Acc: {accuracy:.2f}') 20 21 return loss, accuracy
测试函数:
1 correct = 0 2 total = 0 3 with torch.no_grad(): 4 for data in testloader: 5 inputs, target = data[0].to(device), data[1].to(device) 6 outputs = model(inputs) 7 _, predicted = torch.max(outputs.data, 1) 8 total += target.size(0) 9 correct += (predicted == torch.max(target, 1)[1]).sum().item() 10 return correct, total
模型的训练:
1 train_loss , train_accuracy = [], [] 2 val_loss , val_accuracy = [], [] 3 print(f"Training on {len(train_data)} examples, validating on {len(val_data)} examples...") 4 start = time.time() 5 for epoch in range(epochs): 6 print(f"Epoch {epoch+1} of {epochs}") 7 train_epoch_loss, train_epoch_accuracy = fit(model, trainloader) 8 val_epoch_loss, val_epoch_accuracy = validate(model, valloader) 9 train_loss.append(train_epoch_loss) 10 train_accuracy.append(train_epoch_accuracy) 11 val_loss.append(val_epoch_loss) 12 val_accuracy.append(val_epoch_accuracy) 13 end = time.time() 14 print((end-start)/60, 'minutes') 15 torch.save(model.state_dict(), f"../outputs/models/resnet34_epochs{epochs}.pth") 16 # accuracy plots 17 plt.figure(figsize=(10, 7)) 18 plt.plot(train_accuracy, color='green', label='train accuracy') 19 plt.plot(val_accuracy, color='blue', label='validataion accuracy') 20 plt.xlabel('Epochs') 21 plt.ylabel('Accuracy') 22 plt.legend() 23 plt.savefig('../outputs/plots/accuracy.png') 24 # loss plots 25 plt.figure(figsize=(10, 7)) 26 plt.plot(train_loss, color='orange', label='train loss') 27 plt.plot(val_loss, color='red', label='validataion loss') 28 plt.xlabel('Epochs') 29 plt.ylabel('Loss') 30 plt.legend() 31 plt.savefig('../outputs/plots/loss.png')
结果保存
1 # save the accuracy and loss lists as pickled files 2 print('Pickling accuracy and loss lists...') 3 joblib.dump(train_accuracy, '../outputs/models/train_accuracy.pkl') 4 joblib.dump(train_loss, '../outputs/models/train_loss.pkl') 5 joblib.dump(val_accuracy, '../outputs/models/val_accuracy.pkl') 6 joblib.dump(val_loss, '../outputs/models/val_loss.pkl')
测试网络模型:
1 correct, total = test(model, testloader) 2 print('Accuracy of the network on test images: %0.3f %%' % (100 * correct / total)) 3 print('train.py finished running')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号