用Pytorch迁移学习
在进行深度学习的时候,有时候使用迁移学习可以得到更好的结果;
什么是迁移学习?
迁移学习使用在大型数据集上预训练的网络;
使用迁移学习的好处是神经网络已经从大型数据集中学到了很多重要特征
当我们使用我们自己的数据集后,我们只需要进行微调就可以得到很好的结果;
在本博文中,我们将使用VGG16,该模型的权重来自与ImageNet数据集;
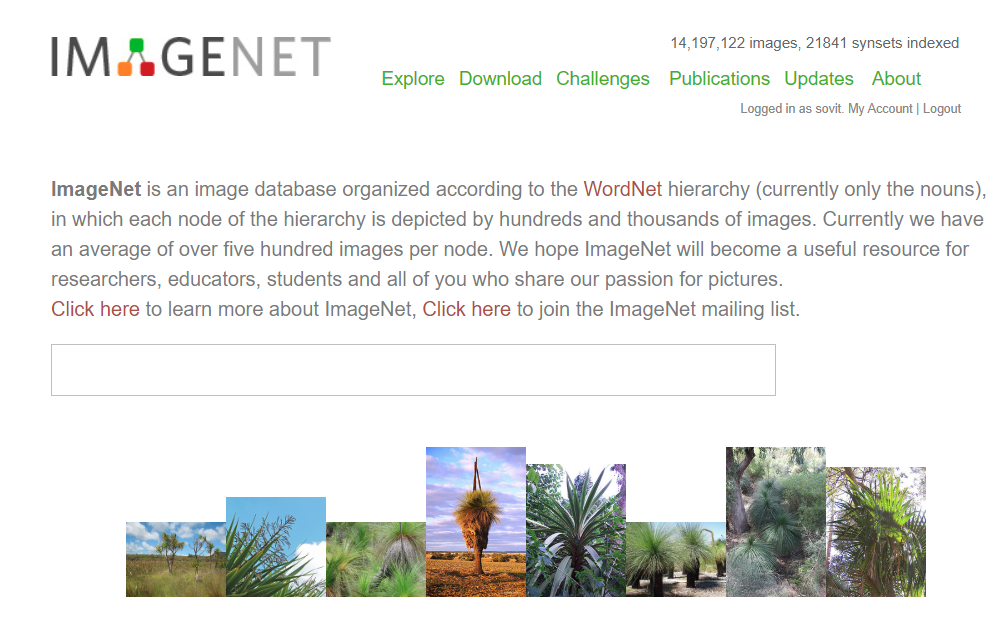
ImageNet包含了超过14百万的图像,覆盖了大概22000个图像类别;
VGG16
基本架构:
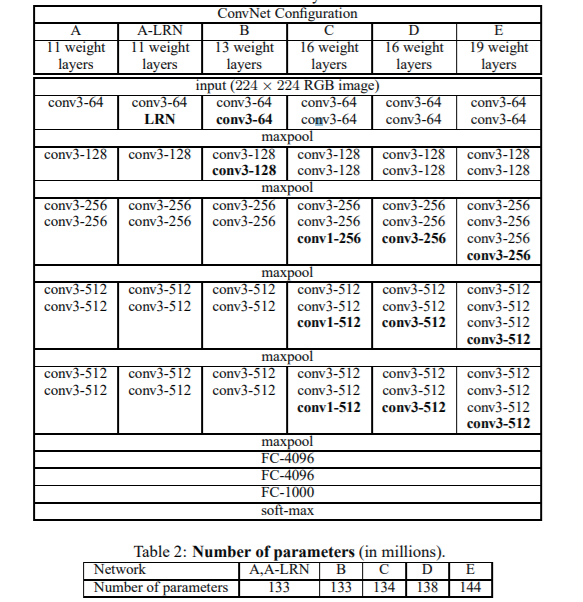
我们使用16层的架构,也就是VGG16,具有138百万个参数;
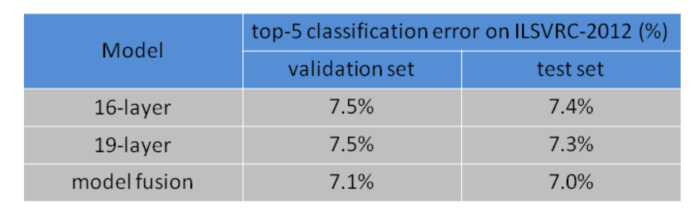
VGG网络模型在ImageNet上的作用效果:
在2014年,VGG 16层网络实现了92.6%的分类精度;VGG19为92.7%
我们的方法

我们使用VGG16对CIFAR10图像进行分类;虽然这个数据集不是很大,但是对迁移学习来说已经足够了;
导入所需的模块和包
导入包
1 import torch 2 import torchvision 3 import torchvision.transforms as transforms 4 import torch.optim as optim 5 import time 6 import torch.nn.functional as F 7 import torch.nn as nn 8 import matplotlib.pyplot as plt 9 from torchvision import models
检查GPU设备
1 # check GPU availability 2 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") 3 print(device)
下载和准备数据集
1 transform = transforms.Compose( 2 [transforms.Resize((224, 224)), 3 transforms.ToTensor(), 4 transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) 5 trainset = torchvision.datasets.CIFAR10(root='./data', train=True, 6 download=True, transform=transform) 7 trainloader = torch.utils.data.DataLoader(trainset, batch_size=32, 8 shuffle=True) 9 testset = torchvision.datasets.CIFAR10(root='./data', train=False, 10 download=True, transform=transform) 11 testloader = torch.utils.data.DataLoader(testset, batch_size=32, 12 shuffle=False)
下载VGG16网络
1 vgg16 = models.vgg16(pretrained=True) 2 vgg16.to(device) 3 print(vgg16)
打印结果:
1 VGG( 2 (features): Sequential( 3 (0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) 4 (1): ReLU(inplace=True) 5 (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) 6 (3): ReLU(inplace=True) 7 (4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) 8 (5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) 9 (6): ReLU(inplace=True) 10 (7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) 11 (8): ReLU(inplace=True) 12 (9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) 13 (10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) 14 (11): ReLU(inplace=True) 15 (12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) 16 (13): ReLU(inplace=True) 17 (14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) 18 (15): ReLU(inplace=True) 19 (16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) 20 (17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) 21 (18): ReLU(inplace=True) 22 (19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) 23 (20): ReLU(inplace=True) 24 (21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) 25 (22): ReLU(inplace=True) 26 (23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) 27 (24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) 28 (25): ReLU(inplace=True) 29 (26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) 30 (27): ReLU(inplace=True) 31 (28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) 32 (29): ReLU(inplace=True) 33 (30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) 34 ) 35 (avgpool): AdaptiveAvgPool2d(output_size=(7, 7)) 36 (classifier): Sequential( 37 (0): Linear(in_features=25088, out_features=4096, bias=True) 38 (1): ReLU(inplace=True) 39 (2): Dropout(p=0.5, inplace=False) 40 (3): Linear(in_features=4096, out_features=4096, bias=True) 41 (4): ReLU(inplace=True) 42 (5): Dropout(p=0.5, inplace=False) 43 (6): Linear(in_features=4096, out_features=1000, bias=True) 44 ) 45 )
冻结网络权重
原始的网络是进行1000个分类,通过观察上面的线性层也可以确认这点;
但是我们需要进行的分类是10个类别。
因此我们需要做些改变;
这个模型已经学习了ImageNet中很多的特征;
因此,冻结Conv2d()中的权重可以是模型使用所有的预训练权重;
这部分实际上就是迁移学习;
下面的代码对于10个类别进行分类是必要的;
1 # change the number of classes 2 vgg16.classifier[6].out_features = 10 3 # freeze convolution weights 4 for param in vgg16.features.parameters(): 5 param.requires_grad = False
优化器和损失函数
1 # optimizer 2 optimizer = optim.SGD(vgg16.classifier.parameters(), lr=0.001, momentum=0.9) 3 # loss function 4 criterion = nn.CrossEntropyLoss()
函数的训练和验证:
在validate()部分,我们计算了损失和精度;但是我们不会反向传播梯度;
反向传播只在训练的时候用到;
1 # validation function 2 def validate(model, test_dataloader): 3 model.eval() 4 val_running_loss = 0.0 5 val_running_correct = 0 6 for int, data in enumerate(test_dataloader): 7 data, target = data[0].to(device), data[1].to(device) 8 output = model(data) 9 loss = criterion(output, target) 10 11 val_running_loss += loss.item() 12 _, preds = torch.max(output.data, 1) 13 val_running_correct += (preds == target).sum().item() 14 15 val_loss = val_running_loss/len(test_dataloader.dataset) 16 val_accuracy = 100. * val_running_correct/len(test_dataloader.dataset) 17 18 return val_loss, val_accuracy
定义训练的方法:
1 # training function 2 def fit(model, train_dataloader): 3 model.train() 4 train_running_loss = 0.0 5 train_running_correct = 0 6 for i, data in enumerate(train_dataloader): 7 data, target = data[0].to(device), data[1].to(device) 8 optimizer.zero_grad() 9 output = model(data) 10 loss = criterion(output, target) 11 train_running_loss += loss.item() 12 _, preds = torch.max(output.data, 1) 13 train_running_correct += (preds == target).sum().item() 14 loss.backward() 15 optimizer.step() 16 train_loss = train_running_loss/len(train_dataloader.dataset) 17 train_accuracy = 100. * train_running_correct/len(train_dataloader.dataset) 18 print(f'Train Loss: {train_loss:.4f}, Train Acc: {train_accuracy:.2f}') 19 20 return train_loss, train_accuracy
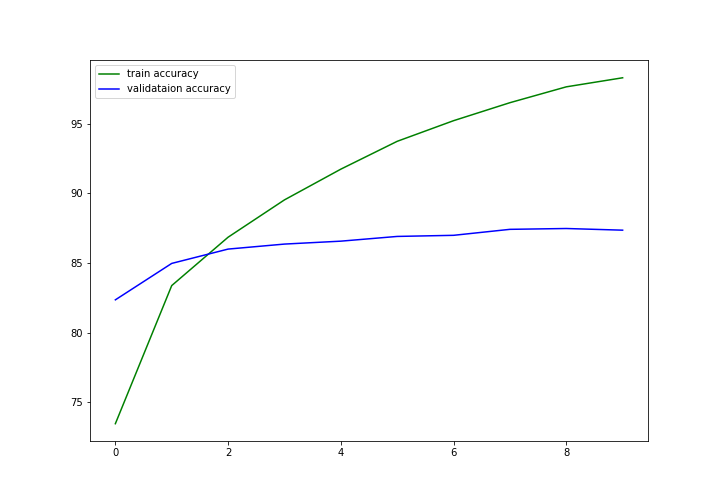
训练和验证模型10次,每次都调用fit()和validate()返回损失和精度;
1 train_loss , train_accuracy = [], [] 2 val_loss , val_accuracy = [], [] 3 start = time.time() 4 for epoch in range(10): 5 train_epoch_loss, train_epoch_accuracy = fit(vgg16, trainloader) 6 val_epoch_loss, val_epoch_accuracy = validate(vgg16, testloader) 7 train_loss.append(train_epoch_loss) 8 train_accuracy.append(train_epoch_accuracy) 9 val_loss.append(val_epoch_loss) 10 val_accuracy.append(val_epoch_accuracy) 11 end = time.time() 12 print((end-start)/60, 'minutes')
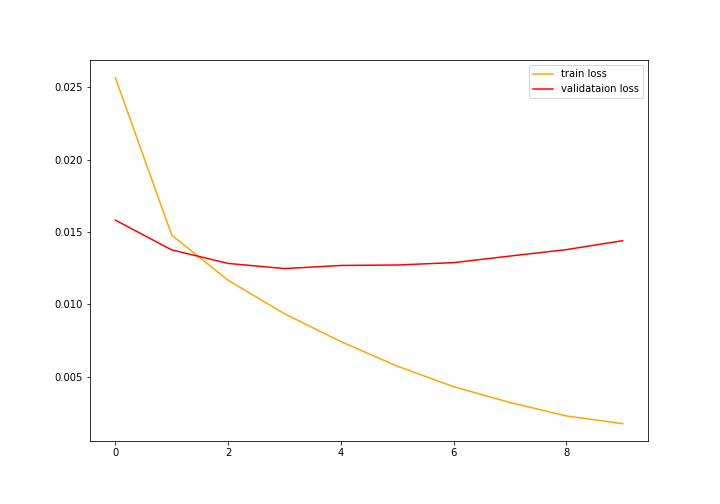
绘图:
1 plt.figure(figsize=(10, 7)) 2 plt.plot(train_accuracy, color='green', label='train accuracy') 3 plt.plot(val_accuracy, color='blue', label='validataion accuracy') 4 plt.legend() 5 plt.savefig('accuracy.png') 6 plt.show()
1 plt.figure(figsize=(10, 7)) 2 plt.plot(train_loss, color='orange', label='train loss') 3 plt.plot(val_loss, color='red', label='validataion loss') 4 plt.legend() 5 plt.savefig('loss.png') 6 plt.show()