使用Pytorch搭建VGG网络——以VGG11为例
在深度学习中,我们可以使用预训练的模型来进行微调或者迁移学习;
有时候在没有预训练模型的情况下,我们也使用pytorch或者tf中预定义的模型;
但是手动实现理解深度学习模型也是非常重要的;
这也就是我们为什么要在这里实现CGG16的深度学习模型;
在本教程中,我们将学习到:
一、VGG11网络
1)网络的基本架构;
2)不同的卷积和全连接层;
3)参数的数量
4)实现细节
二、使用Pytorch手动实现VGG11
我们将实现原始论文中的VGG11深度学习神经网络:
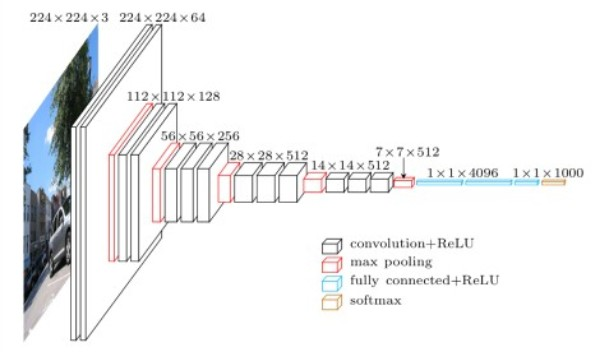
一、VGG11网络
1)网络的基本架构;
在论文中,作者不止介绍了一种VGG网络,而是介绍了一系列的网络配置;
每个都有不同的网络结构;
他们在层的数量以及层的配置上略有出入;
接下来,我们主要关注的是VGG11,这里的11代表的是,有11个参数层;其中8层卷积层,3层全连接层;
表1&2 ConvNet 网络配置及网络参数
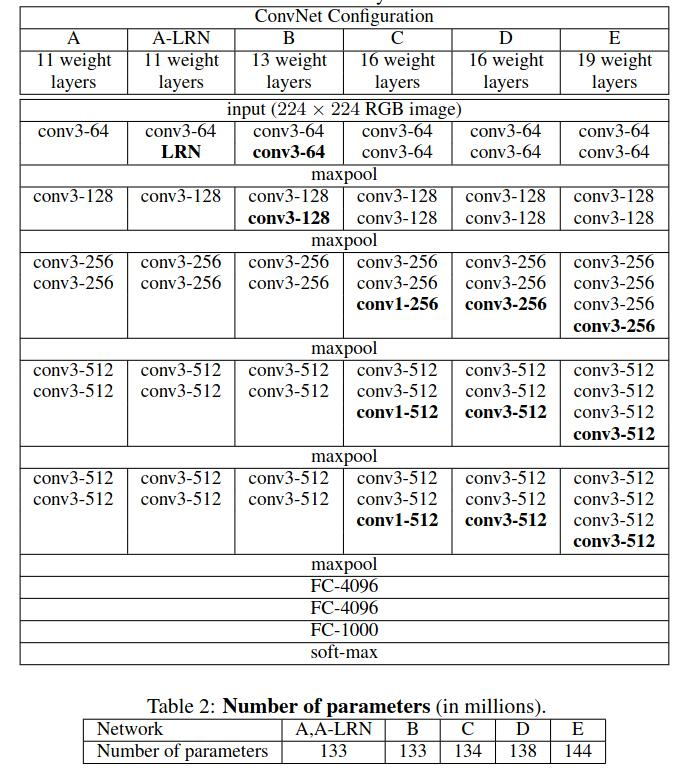
2)不同的卷积和全连接层;
3)参数的数量
VGG11有133 百万个参数,具体的计算过程如下:
参考链接

参数总量: 138357544 138348355
参数内存消耗: 527.7570MB
4)实现细节
由于原论文中没有包含BN层,所以为了学习,我们将按照论文的方式进行网络搭建;
下面所有实现的细节都和论文相同;包含了卷积层、最大池化层、激活层(ReLU)以及全连接层;
因此,接下来实现的VGG11将包含:
- 11个权重层(卷积+全连接)
卷积层3*3kernel size 以及步长1,padding1
- 2D的最大池化层;
需要注意的是,不是所有的卷积层后面都跟着最大池化层
- ReLU非线性激活函数
首先来看一下VGG11的架构:
表3 VGG11的基本架构
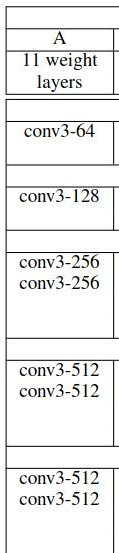
表4. VGG11的所有层
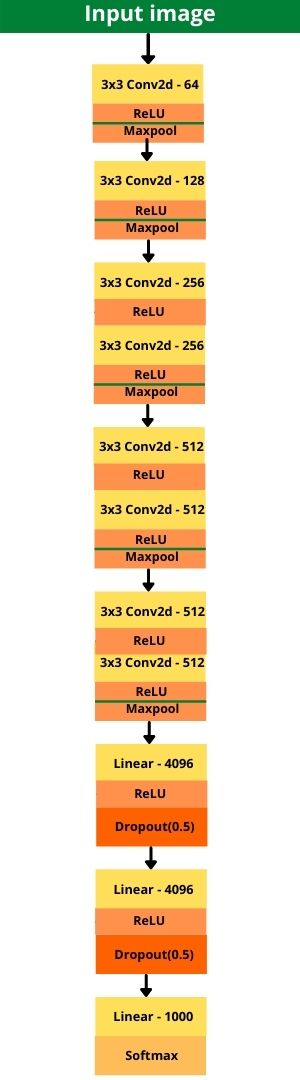
表4 更加直观的展示了每层的细节;需要注意的是,Dropout层在原始论文中没有给出来,但是在原始实现的时候论文也用到了Dropout层
二、使用Pytorch手动实现VGG11
1)导入需要的模块
1 import torch 2 import torch.nn as nn
2)定义VGG11的模块类
1 # the VGG11 architecture 2 class VGG11(nn.Module): 3 def __init__(self, in_channels, num_classes=1000): 4 super(VGG11, self).__init__() 5 self.in_channels = in_channels 6 self.num_classes = num_classes 7 # convolutional layers 8 self.conv_layers = nn.Sequential( 9 nn.Conv2d(self.in_channels, 64, kernel_size=3, padding=1), 10 nn.ReLU(), 11 nn.MaxPool2d(kernel_size=2, stride=2), 12 nn.Conv2d(64, 128, kernel_size=3, padding=1), 13 nn.ReLU(), 14 nn.MaxPool2d(kernel_size=2, stride=2), 15 nn.Conv2d(128, 256, kernel_size=3, padding=1), 16 nn.ReLU(), 17 nn.Conv2d(256, 256, kernel_size=3, padding=1), 18 nn.ReLU(), 19 nn.MaxPool2d(kernel_size=2, stride=2), 20 nn.Conv2d(256, 512, kernel_size=3, padding=1), 21 nn.ReLU(), 22 nn.Conv2d(512, 512, kernel_size=3, padding=1), 23 nn.ReLU(), 24 nn.MaxPool2d(kernel_size=2, stride=2), 25 nn.Conv2d(512, 512, kernel_size=3, padding=1), 26 nn.ReLU(), 27 nn.Conv2d(512, 512, kernel_size=3, padding=1), 28 nn.ReLU(), 29 nn.MaxPool2d(kernel_size=2, stride=2) 30 ) 31 # fully connected linear layers 32 self.linear_layers = nn.Sequential( 33 nn.Linear(in_features=512*7*7, out_features=4096), 34 nn.ReLU(), 35 nn.Dropout2d(0.5), 36 nn.Linear(in_features=4096, out_features=4096), 37 nn.ReLU(), 38 nn.Dropout2d(0.5), 39 nn.Linear(in_features=4096, out_features=self.num_classes) 40 ) 41 def forward(self, x): 42 x = self.conv_layers(x) 43 # flatten to prepare for the fully connected layers 44 x = x.view(x.size(0), -1) 45 x = self.linear_layers(x) 46 return x
如你所见,VGG11包含了pytorch中常见的方法:__init__()方法和forward()方法
下面我们将解释这些方法的细节:
__init__() 方法
- 接受 In_channels和num_classes两个参数;(通道数和分类数量)
- 从11行开始,我们有整个的卷积层定义。使用Sequential类(来自于torch.nn)使得我们可以正确的堆叠这些层;
- 第一个Conv2d()层具有in_channels和self.in_channels;输出层具有64层;kenel的大小是3,并且padding是1;
- 在2D最大池化后使用ReLU激活函数;
- 之后增加输出通道的层数,直至达到512层;
- 需要注意的一点:不是所有的卷积层都有最大池化层;
- 最终的卷积层具有512个输出通道,并且后面接ReLU激活函数和最大池化;
在全连接层,定义self.linear_layers,使用序列模块定义所有的全连接线性层;
- 对所有的VGG架构来说,全连接部分都是一样的;
forward()方法
- 在47行,定义卷积操作,输出特征图;
- 在49行,展平特征图,最后输入线性层;
- 最后得到softmax输出
三、检查VGG11实现的正确性
- 参数的检查,最终的参数应该是132,863,336;
- 检查最终的输出;
1 if __name__ == '__main__': 2 # initialize the VGG model for RGB images with 3 channels 3 vgg11 = VGG11(in_channels=3) 4 # total parameters in the model 5 total_params = sum(p.numel() for p in vgg11.parameters()) 6 print(f"[INFO]: {total_params:,} total parameters.") 7 8 # forward pass check 9 # a dummy (random) input tensor to feed into the VGG11 model 10 image_tensor = torch.randn(1, 3, 224, 224) # a single image batch 11 outputs = vgg11(image_tensor) 12 print(outputs.shape)
最后的输出:
1 [INFO]: 132,863,336 total parameters. 2 torch.Size([1, 1000])
最后检查通过以后可以在CUDA()上运行。
四、总结和结论
本文主要研究了如何搭建一个VGG11基本框架,后续将会研究如何训练VGG,如何实现VGG整个架构;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号