Pytorch下卷积自编码器的实现
原文链接:https://debuggercafe.com/machine-learning-hands-on-convolutional-autoencoders/
本文将包含两个方面研究内容:
1) 使用Pytorch进行卷积自编码的实现;
2) 在网络学习过程中可视化和对比原始图像及重构图像
数据集: CIFAR10
该数据集具有RGB三个通道;
包含60000张32*32个彩色图片;
数据集被分为10个类别,每个类别有6000张图片,其中5000张用于训练,1000张用于测试;

卷积自编码器的实现
(1)导入相关的包
1 import os 2 import torch 3 import torchvision 4 import torch.nn as nn 5 import torchvision.transforms as transforms 6 import torch.optim as optim 7 import torch.nn.functional as F 8 import matplotlib.pyplot as plt 9 from torchvision import datasets 10 from torch.utils.data import DataLoader 11 from torchvision.utils import save_image
(2) 超参数的定义
1 NUM_EPOCHS = 50 2 LEARNING_RATE = 1e-3 3 BATCH_SIZE = 32
(3) 加载数据
1 trainset = datasets.CIFAR10( 2 root='./data', 3 train=True, 4 download=True, 5 transform=transform 6 ) 7 testset = datasets.CIFAR10( 8 root='./data', 9 train=False, 10 download=True, 11 transform=transform 12 ) 13 trainloader = DataLoader( 14 trainset, 15 batch_size=BATCH_SIZE, 16 shuffle=True 17 ) 18 testloader = DataLoader( 19 testset, 20 batch_size=BATCH_SIZE, 21 shuffle=True 22 )
(4)实用函数的定义
1 def get_device(): 2 if torch.cuda.is_available(): 3 device = 'cuda:0' 4 else: 5 device = 'cpu' 6 return device 7 def make_dir(): 8 image_dir = 'Conv_CIFAR10_Images' 9 if not os.path.exists(image_dir): 10 os.makedirs(image_dir) 11 def save_decoded_image(img, name): 12 img = img.view(img.size(0), 3, 32, 32) 13 save_image(img, name)
(5)定义卷积自编码神经网络
1 class Autoencoder(nn.Module): 2 def __init__(self): 3 super(Autoencoder, self).__init__() 4 # encoder 5 self.enc1 = nn.Conv2d( 6 in_channels=3, out_channels=8, kernel_size=3 7 ) 8 self.enc2 = nn.Conv2d( 9 in_channels=8, out_channels=4, kernel_size=3 10 ) 11 # decoder 12 self.dec1 = nn.ConvTranspose2d( 13 in_channels=4, out_channels=8, kernel_size=3 14 ) 15 self.dec2 = nn.ConvTranspose2d( 16 in_channels=8, out_channels=3, kernel_size=3 17 ) 18 def forward(self, x): 19 x = F.relu(self.enc1(x)) 20 x = F.relu(self.enc2(x)) 21 x = F.relu(self.dec1(x)) 22 x = F.relu(self.dec2(x)) 23 return x 24 net = Autoencoder() 25 print(net)
(6)定义损失函数和优化器
1 criterion = nn.MSELoss()
2 optimizer = optim.Adam(net.parameters(), lr=LEARNING_RATE)
(7)定义训练函数和验证函数
1 def train(net, trainloader, NUM_EPOCHS): 2 train_loss = [] 3 for epoch in range(NUM_EPOCHS): 4 running_loss = 0.0 5 for data in trainloader: 6 img, _ = data # no need for the labels 7 img = img.to(device) 8 optimizer.zero_grad() 9 outputs = net(img) 10 loss = criterion(outputs, img) 11 loss.backward() 12 optimizer.step() 13 running_loss += loss.item() 14 15 loss = running_loss / len(trainloader) 16 train_loss.append(loss) 17 print('Epoch {} of {}, Train Loss: {:.3f}'.format( 18 epoch+1, NUM_EPOCHS, loss)) 19 20 if epoch % 5 == 0: 21 save_decoded_image(img.cpu().data, name='./Conv_CIFAR10_Images/original{}.png'.format(epoch)) 22 save_decoded_image(outputs.cpu().data, name='./Conv_CIFAR10_Images/decoded{}.png'.format(epoch)) 23 24 return train_loss 25 26 def test_image_reconstruction(net, testloader): 27 for batch in testloader: 28 img, _ = batch 29 img = img.to(device) 30 outputs = net(img) 31 outputs = outputs.view(outputs.size(0), 3, 32, 32).cpu().data 32 save_image(outputs, 'conv_cifar10_reconstruction.png') 33 break
(8)调用函数&绘图
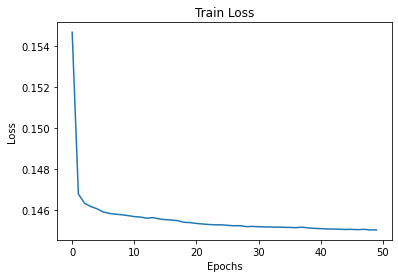
1 device = get_device() 2 print(device) 3 net.to(device) 4 make_dir() 5 train_loss = train(net, trainloader, NUM_EPOCHS) 6 plt.figure() 7 plt.plot(train_loss) 8 plt.title('Train Loss') 9 plt.xlabel('Epochs') 10 plt.ylabel('Loss') 11 plt.savefig('conv_ae_cifar10_loss.png') 12 test_image_reconstruction(net, testloader)

原始图像

生成图像

 浙公网安备 33010602011771号
浙公网安备 33010602011771号