
通俗理解决策树(概述、无公式)
决策树是数据挖掘、决策分析和人工智能中最流行的算法之一。
下面将对其流行的原因进行简单介绍。
什么是决策树?
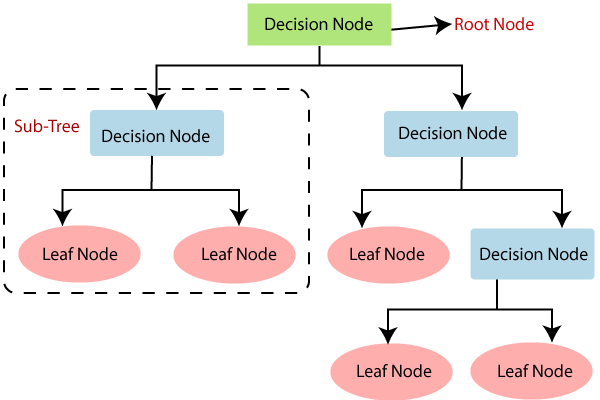
决策树是一个树状图;
节点代表选择一个属性,比如一个问题;
边代表问的问题的答案,
叶子节点代表实际输出或类标签。
决策树在生活中的应用
想象你正在计划下周的活动。你要做的事情很大程度上取决于你的朋友是否有时间和外面的天气如何。
你可以得出以下图表
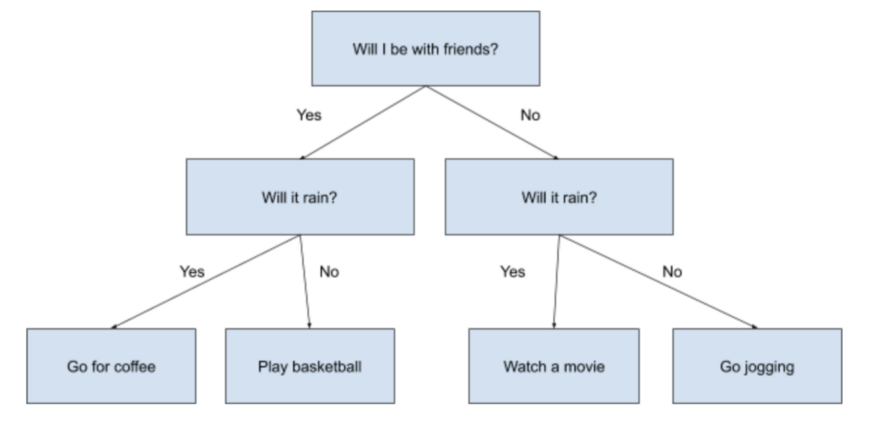
这个图表列出了一些简单的决策规则,可以帮助你根据一些其他数据来决定下周要做什么。在这种情况下,是你朋友是否有空和天气是否下雨。
决策树也是如此。只不过它们以树形结构的形式构建一组决策规则,可以通过归来来预测输入数据的结果。
决策树的应用
决策树模拟人类的决策,因此可以用于各种业务设置。公司经常用它们来预测未来的结果。例如:
1. 哪个客户会保持忠诚,哪个客户会流失?(分类决策树)
2. 根据客户的产品选择,我们能向他们多卖多少?(回归决策树)
3. 接下来我应该向我的博客读者推荐哪篇文章呢?(分类决策树)
决策树的机器学习方法
决策树属于一类有监督的机器学习算法,用于分类(预测离散结果)和回归(预测连续数值结果)预测建模。
该算法的目标是从一系列的输入变量及其属性特征对目标变量进行预测。构建一个树结构的方法通过从根节点开始,经过一系列的二分操作(yes / no),向下传递,直到叶节点,最终得到决策。
每次分割都将输入变量划分为特征区域,用于后续的分割。我们可以这样想象整个树的结构:

决策树算法
决策树构建的方法有很多:
1. ID3:迭代二分法
2. C4.5: ID3的继承者
3. CART:分类回归树
4. CHAID:卡方自动交互检测
5. MARS:多元自适应回归样条
每个新算法是基于已有算法的提升,为了在具有噪音和复杂的数据上实现更高精度。
决策树的实现
通常,决策树算法可以分解成一系列的步骤:
- 属性选择
1. 从整个数据集的所有特征或者属性开始
2. 查看所有可能属性值,选择一个可以将数据集最佳分割的值
3. 什么是“最佳分割”很大程度上取决于最后建立的是分类决策树还是回归决策树;
最佳分割方法:
1. 在树的根节点拆分数据集,并移动到每个分支中的子节点。
2. 对于每个决策节点,重复属性特征选择以及属性值的选择,以确定最佳分割。
3. 这是一种贪心算法:它只查看给定区域属性的最佳局部分割(而不是全局最优),以提高构建树的效率。
4. 不断迭代,直到:
a) 已经到达了每个叶子节点
b) 我们达到了一些停止的标准。
例如,我们可能设置了最大深度,它只允许从根节点到终端节点进行一定数量的分割。或者,我们可能已经在每个终端节点中设置了最小的样本数,以防止终端节点分裂超过某个点。
评价指标
分类决策树的指标
- 基尼指数
- 信息熵
回归决策树的指标
- 方差
决策树模型的优劣
决策树的优势:
1) 可解释性;
2) 对数据预处理要求较少
3) 尺度缩放性能好
4) 对违反假设的鲁棒性
5) 可以同时处理数值型和类别型的数据
决策树的劣势:
1) 容易过拟合
2) 对输入数据的变化不鲁棒
3) 倾向于对占有主导类别的偏差
模型的改进
有几种方法可以改进决策树,每一种方法都通过调整超参数来解决该算法的特定缺点:
——————
针对过拟合问题
指定叶片分裂的最小样本
最大深度
修剪
——————
针对模型精度
集成方法:随机森林
特征选择或降维
提升树
