
word2Vec简析一
本部分为数据预处理部分
word2Vec是一种将单词表示为低维向量的模型;
- Continuous Bag-of-Words Model 连续词袋模型;该模型根据一个单词的上下文来预测该单词;
- Continuous Skip-gram Model 该模型是根据一个单词来预测该单词的上下文。
Skip-gram和negative sampling
举例:
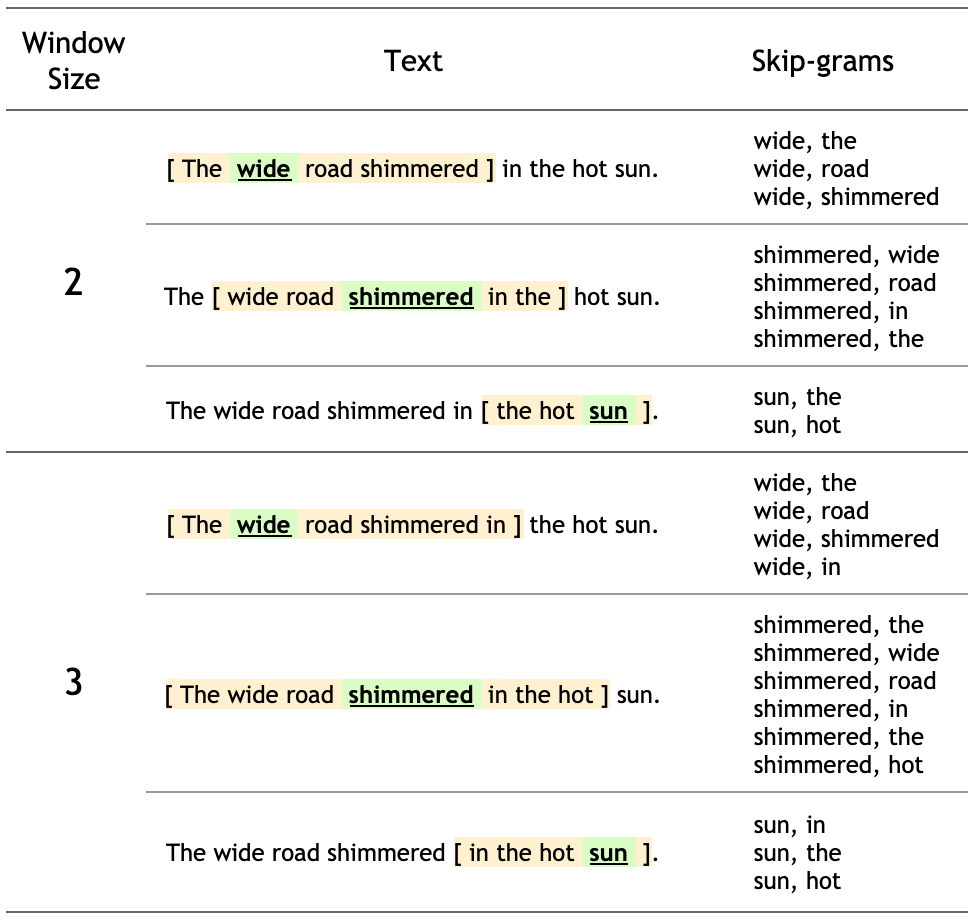
The wide road shimmered in the hot sun.
这句话的8个单词中的每个词的上下文单词是由一个窗口大小定义的。窗口大小决定了可以被视为上下文词的target_word两侧的词的长度。下面是给定一个target词在不同窗口大小下的skip-grams表:
skip-gram模型的训练目标是在给定目标词的情况下,最大化预测上下文词的概率。对于一组单词w1, w2,…wT,目标可以写成平均对数概率
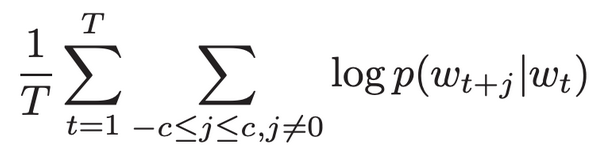
c是训练的上下文;也就是对于每个单词的每个上下文出现的概率之和作为训练目标;
概率计算如下:
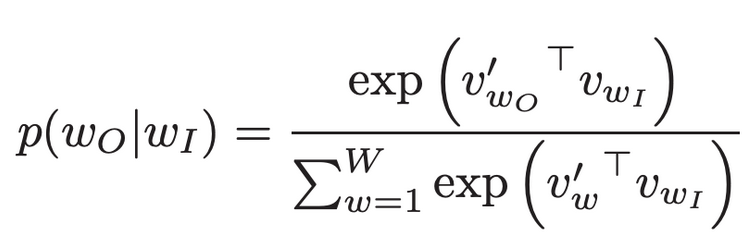
其中v和v'为单词的目标和上下文向量表示,W为词汇大小。
计算这个公式的分母涉及对通常很大(10^5-10^7)的整个词汇表单词执行完整的softmax。
Noise Contrastive Estimation 损失函数是全部的softmax最大值的有效近似。为了学习词的嵌入而不是建模词的分布,NCE损失函数可以使用非负采样进行简化。
目标词的简化负采样目标是将上下文词与从单词的噪声分布Pn(w)中提取的num_ns负样本区分开来。更准确地说,对于一个skip-gram对,词汇表上的full softmax是将目标单词的上下文单词和num_ns负样本之间的分类损失问题。
负样本定义:给定一对(target_word, context_word),这样context_word就不会出现在target_word的window_size附近。
对于示例语句,下面是几个潜在的负样本(当window_size为2时)。
(hot, shimmered)
(wide, hot)
(wide, sun)
接下来就是要生成一些skip-grams以及负例样本对于一个给定句子。
1. 导入包
1 import io 2 import itertools 3 import numpy as np 4 import os 5 import re 6 import string 7 import tensorflow as tf 8 import tqdm 9 10 from tensorflow.keras import Model, Sequential 11 from tensorflow.keras.layers import Activation, Dense, Dot, Embedding, Flatten, GlobalAveragePooling1D, Reshape 12 from tensorflow.keras.layers.experimental.preprocessing import TextVectorization1 SEED = 42 2 AUTOTUNE = tf.data.experimental.AUTOTUNE2. 给定一个样例向量化
1 sentence = "The wide road shimmered in the hot sun" 2 tokens = list(sentence.lower().split()) 3 print(len(tokens))创建一个词汇表来保存从tokens到整数索引的映射。
1 vocab, index = {}, 1 # start indexing from 1 2 vocab['<pad>'] = 0 # add a padding token 3 for token in tokens: 4 if token not in vocab: 5 vocab[token] = index 6 index += 1 7 vocab_size = len(vocab) 8 print(vocab)输出:
{'<pad>': 0, 'the': 1, 'wide': 2, 'road': 3, 'shimmered': 4, 'in': 5, 'hot': 6, 'sun': 7}
创建一个反向词汇表来保存从整数索引到标记的映射。1 inverse_vocab = {index : token for token, index in vocab.items()} 2 print(inverse_vocab)输出:
{0: '<pad>', 1: 'the', 2: 'wide', 3: 'road', 4: 'shimmered', 5: 'in', 6: 'hot', 7: 'sun'}
根据词汇表,矢量化句子:1 example_sequence=[vocab[word] for word in tokens] 2 print(example_sequence)输出:
[1, 2, 3, 4, 5, 1, 6, 7]
3. 为一个句子生成skip-grams
tf.keras.preprocessing 模块提供了一些有用的函数来简化Word2Vec的数据准备工作。
可以使用tf.keras.preprocessing.sequence.skipgrams从[0,vocab_size)范围内的tokens中生成给定window_size的skip-gram对。1 window_size = 2 2 positive_skip_grams, _ = tf.keras.preprocessing.sequence.skipgrams( 3 example_sequence, 4 vocabulary_size=vocab_size, 5 window_size=window_size, 6 negative_samples=0) 7 print(len(positive_skip_grams))4. 为一个skip-gram进行非负采样
skipgrams函数通过在给定的窗口跨度上滑动返回所有正的skip-gram对。为了作为训练的负样本,需要从词汇表中随机抽取单词。使用tf.random。log_uniform_candidate_sampler函数从给定窗口中的目标单词采样num_ns个负采样数。可以在一个skip-grams的目标单词上调用该函数,并将上下文单词作为正类传递,从而将其排除在采样之外。
# Get target and context words for one positive skip-gram. target_word, context_word = positive_skip_grams[0] # Set the number of negative samples per positive context. num_ns = 4 context_class = tf.reshape(tf.constant(context_word, dtype="int64"), (1, 1)) negative_sampling_candidates, _, _ = tf.random.log_uniform_candidate_sampler( true_classes=context_class, # class that should be sampled as 'positive' num_true=1, # each positive skip-gram has 1 positive context class num_sampled=num_ns, # number of negative context words to sample unique=True, # all the negative samples should be unique range_max=vocab_size, # pick index of the samples from [0, vocab_size] seed=SEED, # seed for reproducibility name="negative_sampling" # name of this operation ) print(negative_sampling_candidates) print([inverse_vocab[index.numpy()] for index in negative_sampling_candidates])5. 构建一个训练样本
对于给定的正例(target_word,)跳过,有num_ns负抽样不会出现在target_word的窗口大小附近。将1个正context_word和num_ns个负上下文单词批处理为一个张量。这将为每个目标词产生一组正的跳跃(标记为1)和负的样本(标记为0)。

Continuous Bag-of-Words Model
