


循环神经网络2——利用Python、Numpy和Theano实现RNN
语言建模
我们的目标是利用RNN建立一个语言模型。也就是,如果我们有个句子有m个单词,一个语言模型允许我们预测观察到句子的概率为:
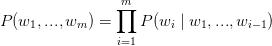
也就是说,这个句子是由每个单词前面给定词汇的概率决定的。因此,句子的概率,“他想去买一些巧克力”,将会是,给定‘他想去买一些’后,‘巧克力’的概率,乘以给定‘他想去买’后,‘一些’的概率,以此类推。
为什么这是有用的?为什么我们想要给观察到的句子分配概率值?
首先,这样一个模型可以作为评分机制。例如,一个机器翻译系统通常为一个输入句子生成多个候选句子。你可以使用语言模型选择最可能的句子。从直觉上讲,最可能的句子应该是语法正确的句子。类似的评分应用在语音识别系统。
对于语言建模问题的解决方法也有一个很酷的副作用。因为我们可以根据前面的单词预测接下来的单词出现的概率,所以我们能够生成新的文本。这是一种生成模式。给定一个现有的单词序列,我们从预测的概率中抽取下一个单词,并重复这个过程,直到我们得到一个完整的句子。Andrej Karparthy有一篇很好的文章展示了语言模型的能力。他的模型训练的是单个字符,而不是完整的单词,可以生成从莎士比亚到Linux代码的任何东西。
注意,在上面的方程中每个词的概率是条件在所有以前的单词。在实践中,许多模型很难代表这种长期依赖关系由于计算或内存的限制。他们通常局限于只看前面的几句话。RNNs理论上可以捕捉这种长期依赖,但实际上它是稍微复杂一点。我们将探讨在后面的帖子。
训练数据和预处理
为了训练我们的语言模型,我们需要文本学习。幸运的是,我们不需要任何标签语言模型训练,只是原始文本。我下载了15000略长的reddit从数据集可以在谷歌BigQuery评论。文本生成的模型将听起来像reddit评论者(希望)!但对于大多数机器学习项目我们首先需要做一些预处理数据转换为正确的格式。
1. Tokenize文本
2.移除不常见的词语
有的单词只出现了一两次。移除这些低频的词是个非常好的主意。庞大的词汇量会让我们的模型训练缓慢(稍后我们将讨论为什么会这样),而且因为我们没有很多关于这些词汇的上下文例子,所以我们无法学习如何正确地使用它们。这与人类的学习方式非常相似。要真正理解如何恰当地使用一个词,你需要在不同的上下文中看到它。
在我们的代码中,我们将词汇表限制为vocabulary_size最常见的单词(我将其设置为8000,但可以随意更改)。我们用UNKNOWN_TOKEN替换词汇表中不包含的所有单词。例如,如果我们的词汇表中没有“非线性”这个词,那么“非线性在神经网络中很重要”这句话就变成了“UNKNOWN_TOKEN在神经网络中很重要”。单词UNKNOWN_TOKEN将成为我们词汇表的一部分,我们将像预测其他单词一样预测它。当我们生成新的文本时,我们可以再次替换UNKNOWN_TOKEN,例如,通过使用一个不属于我们词汇表的随机抽样单词,或者我们可以只生成句子,直到我们得到一个不包含未知标记的句子。
3.预先考虑特殊的开始和结束标记
:我们还想知道在一个句子中哪些词是开始和结束的。为此,我们在前面添加一个特殊的SENTENCE_START标记,并在每个句子后附加一个特殊的SENTENCE_END标记。这允许我们问:假设第一个标记是SENTENCE_START,那么下一个单词可能是什么(句子实际的第一个单词)?
4. 建立模型训练指标
我们循环神经网络的输入是向量,而不是字符串。因此我们创建了单词和索引之间的映射,即index_to_word和word_to_index。例如,“友好”一词可能出现在2001索引中。训练示例x可能类似于[0,179,341,416],其中0对应于SENTENCE_START。对应的标签y为[179,341,416,1]。记住,我们的目标是预测下一个单词,所以y就是x向量移动了一个位置,最后一个元素是SENTENCE_END标记。换句话说,对上面179个单词的正确预测应该是341,即实际句子的一下个单词。
建立RNN
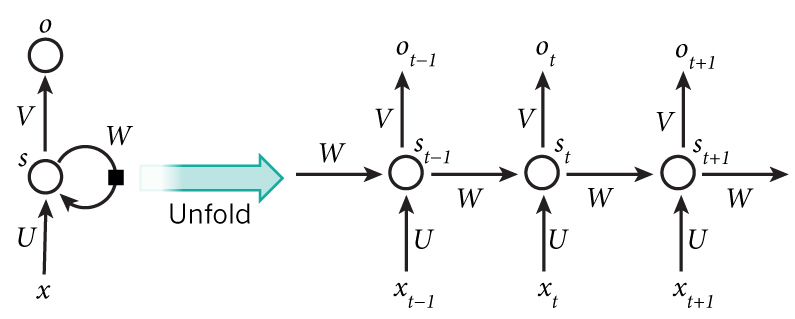
图1 RNN的展开结构
让我们具体看看我们的语言模型的RNN是什么样子的。输入x将是一个单词序列(就像上面打印的示例一样),每个x_t是一个单词。但还有一件事:由于矩阵乘法的工作原理,我们不能简单地使用一个单词索引(比如36)作为输入。相反,我们将每个单词表示为大小单热向量vocabulary_size。例如,索引为36的单词将是位置为36的标记为1,剩下的位置标记为0的向量。每个x_t为一个向量,则x为一个矩阵,每一行代表一个单词。我们将在神经网络代码中执行这个转换,而不是在预处理中执行。我们的网络o的输出也有类似的格式。每个o_t都是vocabulary_size元素的向量,每个元素表示该单词成为句子中下一个单词的概率。
让我们从头开始回顾一下RNN的公式:
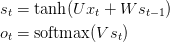
我发现写出矩阵和向量的维数是很有用的。假设我们选择的词汇量为C = 8000,隐藏层大小为H = 100。你可以把隐藏层的大小想象成我们网络的“内存”。增大它可以让我们学习更复杂的模式,但也会导致额外的计算。然后我们有: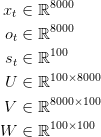
这是有价值的信息。请记住,U,V和W是我们想从数据中学习的网络参数。因此,我们需要学习总共2HC + H^2的参数。在C=8000 H=100的情况下,这是1610000。这个维度同样也告诉我们我们模型的瓶颈。注意,因为x_t是一个One-hot向量,它与U相乘本质上等同于选择U的一列,所以我们不需要执行完整的乘法。那么,我们网络中最大的矩阵乘法就是Vs_t。这就是为什么我们要尽可能地保持词汇量小。
有了这些,就可以开始我们的实现了。
初始化
我们首先声明一个RNN类,初始化参数。我将这个类称为RNNNumpy,因为稍后我们将实现Theano版本。初始化参数U、V和W有点棘手。我们不能把它们初始化为0,因为那样会导致所有层的对称计算。我们必须随机初始化它们。由于很多研究表明适当的初始化似乎对训练结果有影响。事实证明,最佳的初始化取决于激活函数(在我们的例子中是\tanh),推荐的一种方法是在间隔内随机初始化权重![\left[-\frac{1}{\sqrt{n}}, \frac{1}{\sqrt{n}}\right]](http://s0.wp.com/latex.php?latex=%5Cleft%5B-%5Cfrac%7B1%7D%7B%5Csqrt%7Bn%7D%7D%2C+%5Cfrac%7B1%7D%7B%5Csqrt%7Bn%7D%7D%5Cright%5D&bg=ffffff&fg=000&s=0 "\left[-\frac{1}{\sqrt{n}}, \frac{1}{\sqrt{n}}\right]")
1 class RNNNumpy: 2 3 def __init__(self, word_dim, hidden_dim=100, bptt_truncate=4): 4 # Assign instance variables 5 self.word_dim = word_dim 6 self.hidden_dim = hidden_dim 7 self.bptt_truncate = bptt_truncate 8 # Randomly initialize the network parameters 9 self.U = np.random.uniform(-np.sqrt(1./word_dim), np.sqrt(1./word_dim), (hidden_dim, word_dim)) 10 self.V = np.random.uniform(-np.sqrt(1./hidden_dim), np.sqrt(1./hidden_dim), (word_dim, hidden_dim)) 11 self.W = np.random.uniform(-np.sqrt(1./hidden_dim), np.sqrt(1./hidden_dim), (hidden_dim, hidden_dim))
以上,word_dim我们词汇量的大小,hidden_dim是我们隐藏层的大小(可以选择)。不要担心bptt_truncate参数现在,稍后我们将解释那是什么。
前向传播
接下来,实现前向传播。
1 def forward_propagation(self, x): 2 # The total number of time steps 3 T = len(x) 4 # During forward propagation we save all hidden states in s because need them later. 5 # We add one additional element for the initial hidden, which we set to 0 6 s = np.zeros((T + 1, self.hidden_dim)) 7 s[-1] = np.zeros(self.hidden_dim) 8 # The outputs at each time step. Again, we save them for later. 9 o = np.zeros((T, self.word_dim)) 10 # For each time step... 11 for t in np.arange(T): 12 # Note that we are indxing U by x[t]. This is the same as multiplying U with a one-hot vector. 13 s[t] = np.tanh(self.U[:,x[t]] + self.W.dot(s[t-1])) 14 o[t] = softmax(self.V.dot(s[t])) 15 return [o, s] 16 17 RNNNumpy.forward_propagation = forward_propagation
我们不仅返回计算的输出,而且还返回隐藏状态。稍后我们将使用它们来计算梯度,通过在这里返回它们,我们避免了重复计算。每个o_t都是表示我们词汇表中单词的概率向量,但有时,例如在评估我们的模型时,我们想要的只是下一个概率最高的单词。我们称这个函数为predict:
1 def predict(self, x): 2 # Perform forward propagation and return index of the highest score 3 o, s = self.forward_propagation(x) 4 return np.argmax(o, axis=1) 5 6 RNNNumpy.predict = predict
让我们尝试一下我们新实现的方法,看看一个示例输出:
np.random.seed(10) model = RNNNumpy(vocabulary_size) o, s = model.forward_propagation(X_train[10]) print o.shape print o
句子中的每个单词(45个),我们的模型预测了8000代表下一个单词的概率。注意,因为我们初始化随机值现在这些预测是完全随机的。以下给出了指标最高的概率预测每个单词:
[plain](45,)
[1284 5221 7653 7430 1013 3562 7366 4860 2212 6601 7299 4556 2481 238 2539
21 6548 261 1780 2005 1810 5376 4146 477 7051 4832 4991 897 3485 21
7291 2007 6006 760 4864 2182 6569 2800 2752 6821 4437 7021 7875 6912 3575]
[/plain]
损失的计算
为了训练我们的网络,我们需要一种方法来测量它所产生的误差。我们称之为损失函数L,我们的目标是找到参数U,V和W使我们的训练数据的损失函数最小化。损失函数的一种常见选择是交叉熵损失。如果我们有N个训练例子(文本中的单词)和C个类(词汇表的大小),那么关于我们的预测o和真实标签y的损失是:
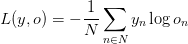
这个公式看起来有点复杂,但它所做的只是对我们的训练示例进行求和,并根据我们的预测增加损失。y(正确的单词)和o(我们的预测)越远,损失就越大。
用SGD和时间反向传播(BPTT)训练RNN
记住,我们想要找到参数U,V和W使训练数据的总损失最小化。最常见的方法是SGD,即随机梯度下降。SGD背后的想法非常简单。我们遍历了所有的训练示例,在每次迭代中,我们将参数调整到一个可以减少错误的方向。这些方向由损失的梯度给出: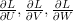 。SGD还需要一个学习率,它定义了我们希望在每次迭代中完成的步骤有多大。SGD不仅是神经网络最常用的优化方法,也是许多其他机器学习算法最常用的优化方法。因此,已经有很多关于如何使用批处理、并行性和自适应学习率来优化SGD的研究。尽管基本思想很简单,但以一种真正有效的方式实现SGD会变得非常复杂。如果你想了解更多关于SGD的知识,这是一个很好的开始。因为SGD很流行,网上有很多教程,我不想在这里复制它们。我将实现一个简单的SGD版本,即使没有优化背景也可以理解。
。SGD还需要一个学习率,它定义了我们希望在每次迭代中完成的步骤有多大。SGD不仅是神经网络最常用的优化方法,也是许多其他机器学习算法最常用的优化方法。因此,已经有很多关于如何使用批处理、并行性和自适应学习率来优化SGD的研究。尽管基本思想很简单,但以一种真正有效的方式实现SGD会变得非常复杂。如果你想了解更多关于SGD的知识,这是一个很好的开始。因为SGD很流行,网上有很多教程,我不想在这里复制它们。我将实现一个简单的SGD版本,即使没有优化背景也可以理解。
但是我们如何计算上面提到的梯度呢?在传统的神经网络中,我们通过反向传播算法来做到这一点。在RNNs中,我们使用了该算法的一个稍加修改的版本,称为时间反向传播(BPTT)。由于网络中所有时间步长都共享这些参数,因此每个输出点的梯度不仅取决于当前时间步长的计算,还取决于之前的时间步长。如果你懂微积分,其实就是运用链式法则。本教程的下一部分将全部是关于BPTT的,因此在这里我不打算详细介绍推导过程。关于反向传播的一般介绍,请查看这个和这个帖子。现在,您可以将BPTT视为黑盒。它以一个训练示例(x,y)作为输入,并返回梯度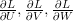 。
。

