
循环卷积网络教程1 ——RNN基础介绍
卷积神经网络(RNN)是一种流行的网络结构,可以处理很多NLP的任务。尽管它们最近非常流行,但是对于其如何工作原理的解释是非常少有的。这个是这个教程将要做的事情。接下来要讲一下多系列:
1. 介绍RNN(本部分)
2. 利用Python和Theano实现一个RNN
3.通过BPTT算法理解后向传播和梯度消失问题
4.实现一个GRU/LSTM RNN
本部分教程将实现一个RNN语言模型。
应用这个模型有两个方面的原因:
1)它允许我们评估任意的句子,基于他们在现实生活中有多大的出现的可能性;这给我们一个语法和语义正确性的衡量方法。这个模型典型应用于机器翻译系统;
2)一个语言模型允许我们生成新的文本(我认为这是非常棒的应用)。训练一个语言模型基于Shakespeare允许我们生成Shakespeare类似的文本。这个有趣的发布论证了字符级的语言模型的能力;
我假设你对于基本的卷积网络的框架是熟悉的;如果你不熟,你可能想要从头开始实现一个神经网络,它将指导您了解非循环网络背后的思想和实现。
什么是RNN?
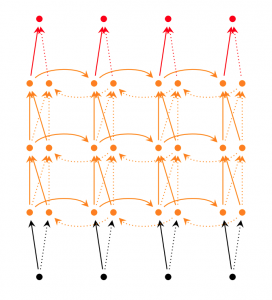
RNN背后的原理是利用序列信息。在一个传统的卷积网络中,我们假设的是所有的输入和输出都是独立的。但是对于许多任务来说,这个是一个非常差劲的假设。如果你想预测一个句子中下一个单词,你最好知道这个单词之前的词。RNN被称为recurrent 因为它们对序列的每个元素执行相同的任务,同时输出依赖于前期的计算。另一种方式思考RNN是他们有记忆,可以捕捉过去计算过的信息。在理论上来说,RNN可以使用任意长的序列中的信息,但在实践中,它们只能向后看几个步骤(稍后详细介绍)。典型的RNN是这样的:
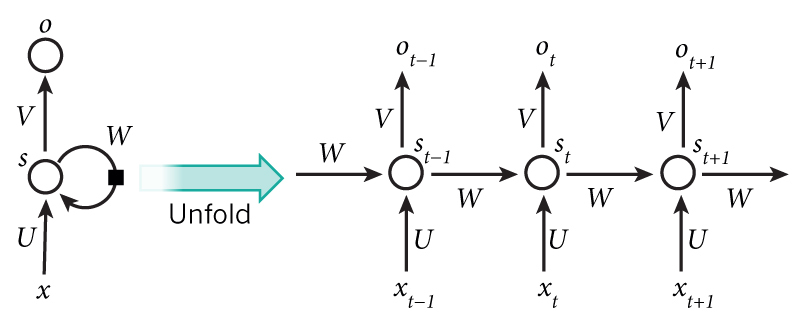
图 1 递归神经网络及其前向计算展开
上面的图显示了一个RNN被展开成一个完整的网络。展开的意思是我们写出了完整序列的网络。例如,如果我们关心的序列是一个包含5个单词的句子,那么这个网络将被展开为一个5层的神经网络,每层对应一个单词。RNN计算的公式如下:
- xt 是t时刻的输入。举例来说,x1是一个one-hot的向量对应于一个句子的第二个单词;
- St是时刻的隐藏状态。这个网络的“memory”,St的计算是基于之前的隐藏状态和现有步骤的输入得到的。St=f(Uxt+WSt-1) f通常为非线性的激活函数,例如tanh,ReLU,S-1通常需要在第一层隐藏状态计算,最开始的话初始化为0。
- Ot是每个时刻t的输出。举例来说,如果我们想要预测一个句子下一个单词,通过我们的词典,它可能是一个向量的概率。
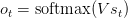
有一些需要注意的地方:
- 你可以认为隐藏状态St是网络的记忆。St捕捉的信息是过去时间步骤内发生了什么。输入步骤Ot是仅仅根据t时刻上的记忆进行计算的。正如上面提到的,实际上这是有些复杂的,因为St不能够捕捉很多时段之前的信息。
- 不像其他传统的深度神经网络在每一层使用不同的参数,而RNN共享相同的参数(U,V,W上述),这反映了这样一个事实,即我们在每一步执行相同的任务,只是使用不同的输入。这大大减少了我们需要学习的参数的总数。
- 上面的步骤在每个时间段都有输出,但是依赖于不同的任务,可能是不必要的。例如,在预测一个句子的情感时,我们可能只关心最终的输出结果,而不是每个单词后面的情感。类似地,我们可能不需要在每个时间步长都有输入。RNN的主要特征是它的隐藏状态,它捕获了序列的一些信息。
RNN可以做什么?
在许多NLP任务中,神经网络已显示出巨大的成功。在这一点上,我应该提到最常用的RNNs类型是lstm,它在捕获长期依赖关系方面比普通的RNNs要好得多。但是不用担心,LSTMs本质上与我们将在本教程中开发的RNN是一样的,它们只是计算隐藏状态的方式不同。我们将在后面的文章中更详细地介绍LSTMs。下面是一些RNNs在NLP中的示例应用(通过非详尽列表)。
语言模型和文本生成:
给定一个单词序列,我们想要预测每个单词出现前一个单词的概率。语言模型允许我们衡量一个句子的可能性,这对于及其翻译很重要(因为出现频率高的句子往往是正确的)。能够预测下一个单词的一个副作用是我们得到了一个生成模型,它允许我们通过从输出概率抽样来生成新的文本。依赖我们的训练数据,我们可以生成各种各样的东西。在语言建模,我们的输入通常是一个单词序列(编码为1 -h),输出通常是预测的单词。当训练网络的时候,我们设置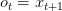 ,因为我们想要在t时刻预测下一个单词。
,因为我们想要在t时刻预测下一个单词。
机器翻译:
机器翻译与语言建模的相似之处在于我们的输入是我们源语言中的一系列单词。我们想要输出我们目标语言的单词序列。一个关键的差异在于我们的输出只有在完整语句输入结束后才开始,因为我们翻译的句子的第一个单词可能需要从完整的输入序列中捕获的信息。
图2. 机器翻译
语音辨识:
给定来自声音信号的输入序列,我们可以预测一系列语音片段及其概率。
图片描述生成
与卷积神经网络一起,神经网络被用作模型的一部分,用于生成未标记图像的描述。它的工作效果非常好。合并后的模型甚至将生成的单词与图像中的特征对应起来。
RNN的训练:
训练一个RNN类似于传统的神经网络。我们同样也使用了反向传播算法,但是稍微有点变化。由于网络中所有时间步长都共享这些参数,因此每个输出点的梯度不仅取决于当前时间步长的计算,还取决于之前的时间步长。例如,为了计算t=4时的梯度,我们需要反向传播3步并将梯度相加。这被称为时间反向传播(BPTT)。如果这还没有完整的概念,不要担心,我们会有一个完整帖子关于相关的细节。目前而言,只需要知道这个事实:由于所谓的消失/爆炸梯度问题,使用BPTT训练的普通RNNs在学习长期依赖(例如,步骤之间相距很远的依赖)方面存在困难。有一些机制,以及相应的RNN网络类型是专门设计来解决这些问题的。
RNN拓展
多年来,研究人员已经开发出更复杂的类型的RNNs处理一些原始RNN模型的缺点。我们将讨论他们的更多细节在后面的帖子,但我希望这部分作为简要概述,以便您熟悉的模型的概况。
双向RNN:
双向神经网络是基于这样一种思想,即t时刻的输出可能不仅依赖于序列中先前的元素,还依赖于未来的元素。例如,要预测一个序列中缺失的单词,您需要同时查看左右上下文。双向网络非常简单。它们只是两个重叠在一起的神经网络。然后根据这两个rnn的隐藏状态计算输出。

图3. 双向循环网络
深度双向RNN:
Deep (Bidirectional) RNNs
类似于双向RNNs,只有我们现在每个时间步有多个层。在实践中,这给了我们一个更高的学习能力(但我们也需要大量的训练数据)。
LSTM网络:
LSTM网络现在非常流行,我们在上面简要地讨论过。LSTMs与RNNs没有根本不同的架构,但是它们使用不同的函数来计算隐藏状态。LSTMs中的内存称为cells,您可以将它们视为黑盒,接受前一个状态h_{t-1}和当前输入x_t作为输入。在内部,这些 cell 决定哪些要保留(哪些要删除)内存。然后,它们将前一状态、当前内存和输入组合起来。事实证明,这些类型的单位在捕获长期依赖时非常有效
总结:
到目前为止一切顺利。我希望你已经对什么是rnn和它们能做什么有了基本的了解。在下一篇文章中,我们将使用Python和Theano实现语言模型RNN的第一个版本。请在评论中留下问题!
