从零单排Hadoop——1.搭建Hadoop开发环境
Hadoop环境准备:ubuntu 12.05、Hadoop 2.4
一.安装ssh
由于hadoop可以配置为集群运行,因此系统需要安装ssh工具保证集群中各节点可以互相访问。
获取ssh软件:
sudo apt-get install openssh-server
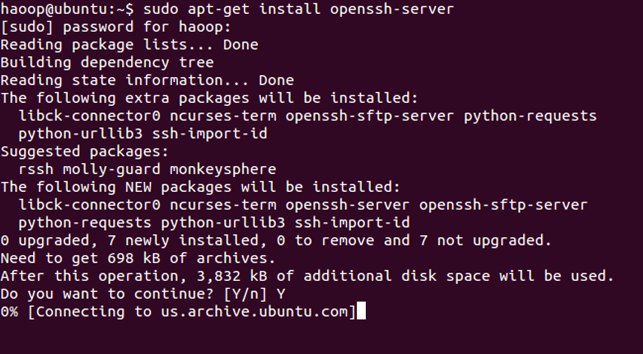
安装完成后,启动服务:
sudo /etc/init.d/ssh start
查看服务是否正确启动:
ps -e | grep ssh
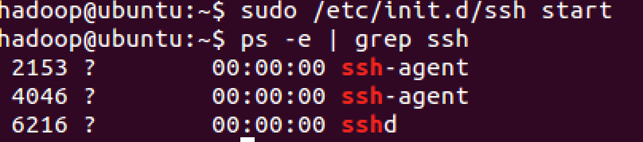
设置免密码登录,生成私钥和公钥:
ssh-keygen -t rsa -P ""
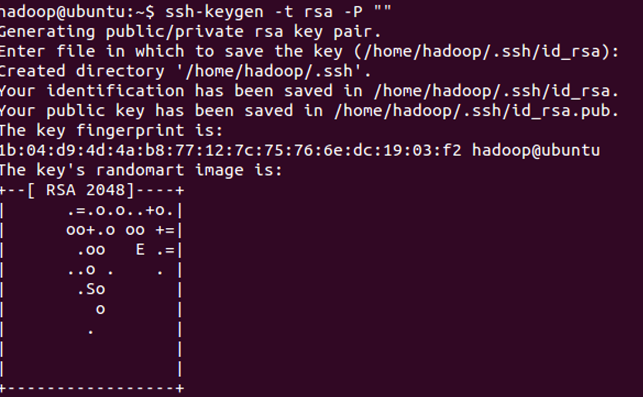
此时会在/home/hadoop/.ssh下生成两个文件:id_rsa和id_rsa.pub,前者为私钥,后者为公钥。
将公钥追加到authorized_keys中,它用户保存所有允许以当前用户身份登录到ssh客户端用户的公钥内容。
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys

登录ssh,测试是否配置成功:
ssh localhost
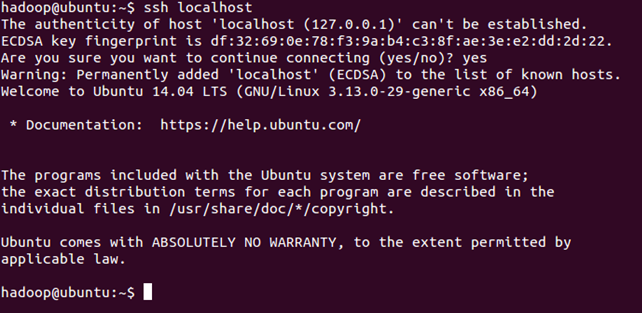
退出
exit
二.安装配置java环境
获取jdk安装包:
sudo apt-get install openjdk-7-jdk
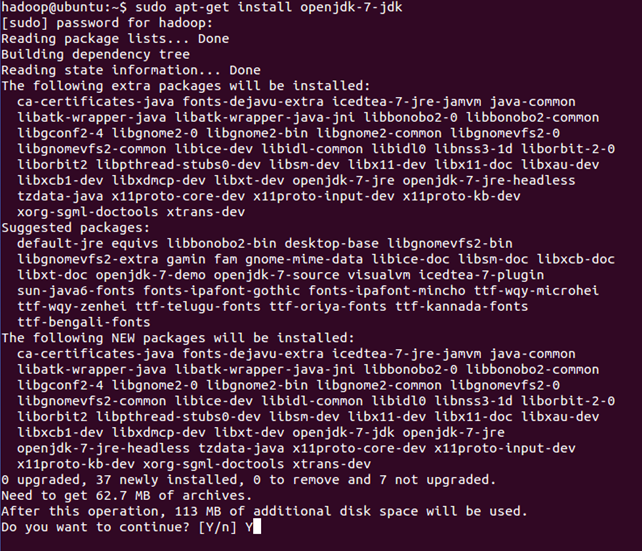
查看安装结果,输入命令:java -version,结果如下表示安装成功。

三.安装hadoop
1、官网下载http://mirror.bit.edu.cn/apache/hadoop/common/
2、安装
解压
sudo tar xzf hadoop-2.4.0.tar.gz
假如我们要把hadoop安装到/usr/local下,拷贝到/usr/local/下,文件夹为hadoop
sudo mv hadoop-2.4.0 /usr/local/hadoop
赋予用户对该文件夹的读写权限
sudo chmod 774 /usr/local/hadoop
3、配置
1)配置~/.bashrc
配置该文件前需要知道Java的安装路径,用来设置JAVA_HOME环境变量,可以使用下面命令行查看安装路径
update-alternatives --config java
执行结果如下:

完整的路径为/usr/lib/jvm/java-7-openjdk-amd64/jre/bin/java,只取前面的部分 /usr/lib/jvm/java-7-openjdk-amd64配置.bashrc文件
sudo gedit ~/.bashrc
该命令会打开该文件的编辑窗口,在文件末尾追加下面内容,然后保存,关闭编辑窗口。
#HADOOP VARIABLES START
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
export HADOOP_INSTALL=/usr/local/hadoop
export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
export YARN_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib"
#HADOOP VARIABLES END
最终结果如下:
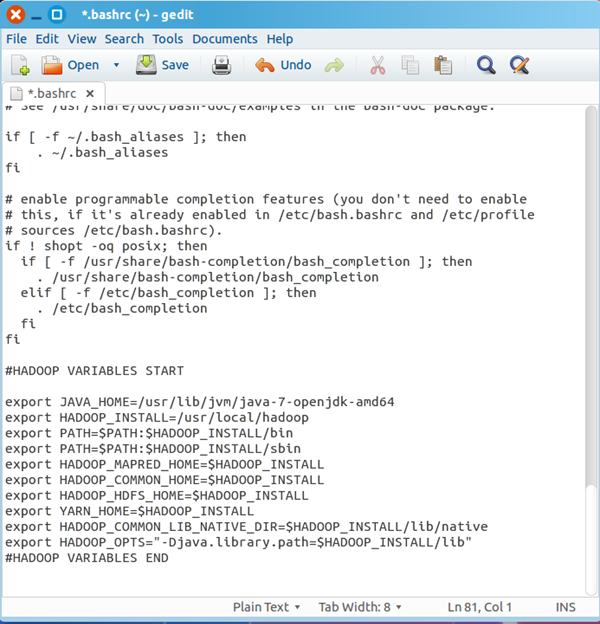
执行下面命,使添加的环境变量生效:
source ~/.bashrc
2)编辑/usr/local/hadoop/etc/hadoop/hadoop-env.sh 执行下面命令,打开该文件的编辑窗口
sudo gedit /usr/local/hadoop/etc/hadoop/hadoop-env.sh
找到JAVA_HOME变量,修改此变量如下
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
修改后的hadoop-env.sh文件如下所示:
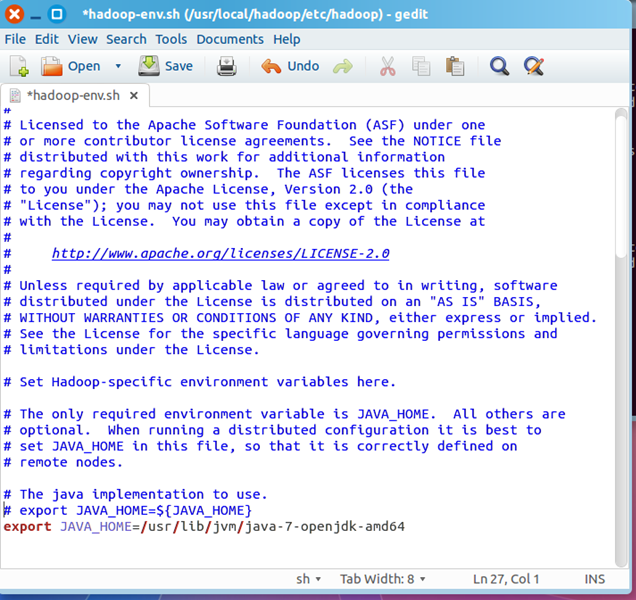
四.测试
单机模式安装完成,下面通过执行hadoop自带实例WordCount验证是否安装成功,/usr/local/hadoop路径下创建input文件夹
mkdir input
拷贝README.txt到input
cp README.txt input
执行WordCount
bin/hadoop jar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.4.0-sources.jar org.apache.hadoop.examples.WordCount input output

执行结果
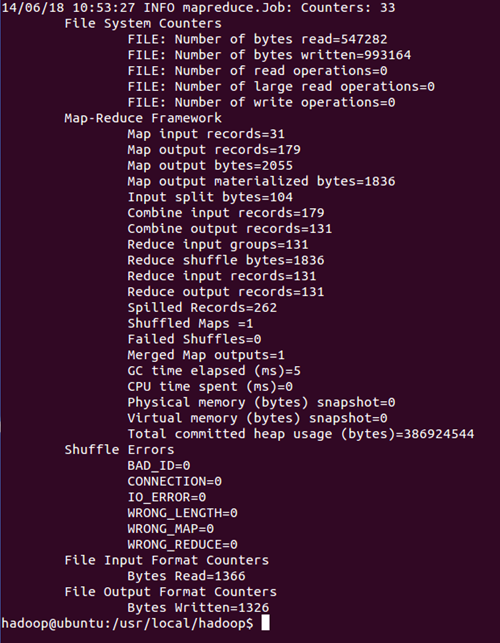
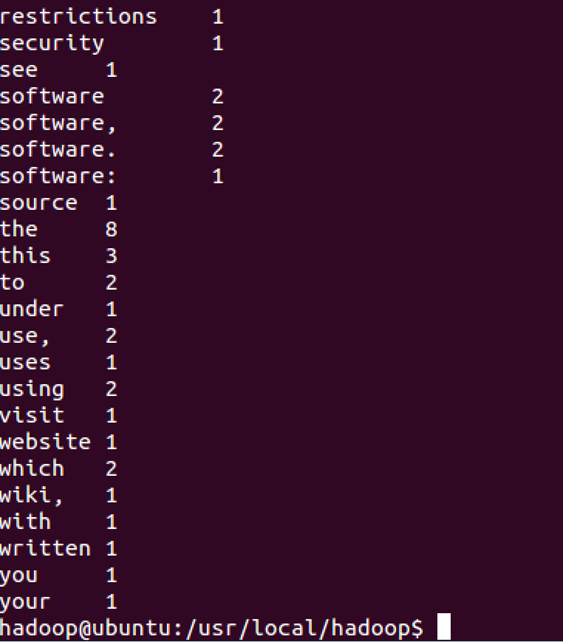
执行 cat output/*,查看字符统计结果
五.hadoop组件相关配置
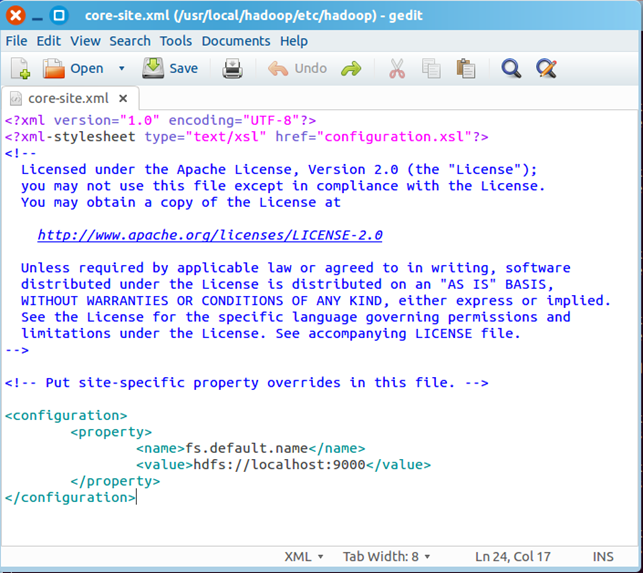
1)配置core-site.xml
/usr/local/hadoop/etc/hadoop/core-site.xml 包含了hadoop启动时的配置信息。编辑器中打开此文件
sudo gedit /usr/local/hadoop/etc/hadoop/core-site.xml

在该文件的<configuration></configuration>之间增加如下内容:
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
保存、关闭编辑窗口,最终修改后的文件内容如下:
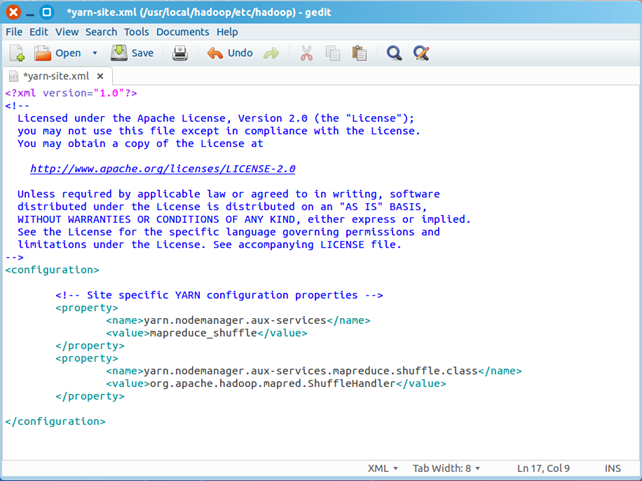
2)配置yarn-site.xml
/usr/local/hadoop/etc/hadoop/yarn-site.xml包含了MapReduce启动时的配置信息。编辑器中打开此文件
sudo gedit yarn-site.xml

在该文件的<configuration></configuration>之间增加如下内容:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
保存、关闭编辑窗口,最终修改后的文件内容如下:
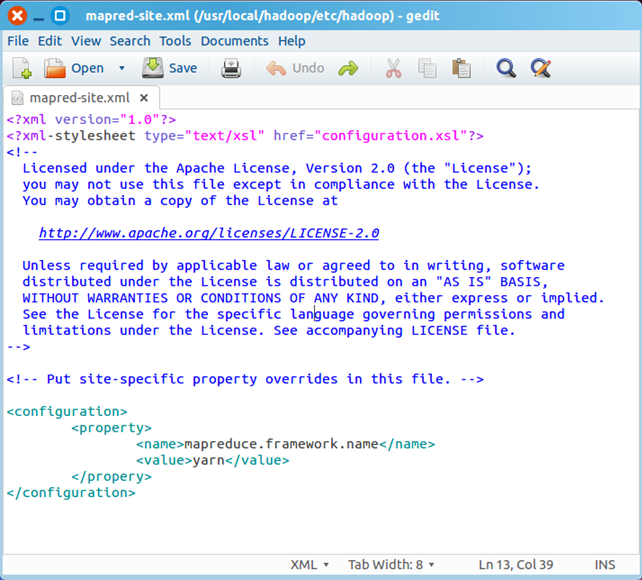
3)创建和配置mapred-site.xml
默认情况下,/usr/local/hadoop/etc/hadoop/文件夹下有mapred.xml.template文件,我们要复制该文件,并命名为mapred.xml,该文件用于指定MapReduce使用的框架。 复制并重命名
cp mapred-site.xml.template mapred-site.xml
编辑器打开此新建文件
sudo gedit mapred-site.xml

在该文件的<configuration></configuration>之间增加如下内容:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
保存、关闭编辑窗口,最终修改后的文件内容如下
4)配置hdfs-site.xml
/usr/local/hadoop/etc/hadoop/hdfs-site.xml用来配置集群中每台主机都可用,指定主机上作为namenode和datanode的目录。创建文件夹,如下图所示
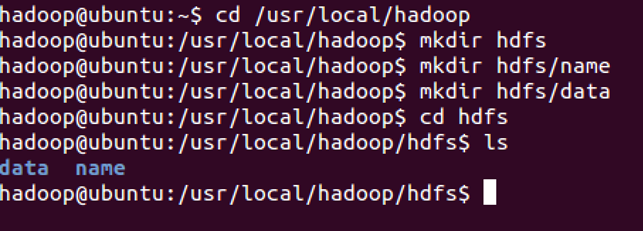
也可以在别的路径下创建上图的文件夹,名称也可以与上图不同,但是需要和hdfs-site.xml中的配置一致。编辑器打开hdfs-site.xml
在该文件的<configuration></configuration>之间增加如下内容:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hdfs/data</value>
</property>
保存、关闭编辑窗口,最终修改后的文件内容如下:
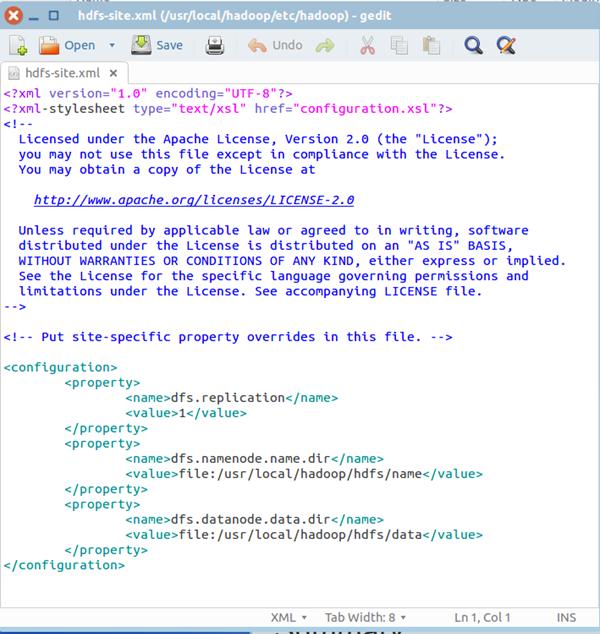
5)格式化hdfs
hdfs namenode -format
只需要执行一次即可,如果在hadoop已经使用后再次执行,会清除掉hdfs上的所有数据。
6)启动Hadoop
经过上文所描述配置和操作后,下面就可以启动这个单节点的集群,执行启动命令:
sbin/start-dfs.sh
如果有yes /no提示,输入yes,回车即可。接下来,执行:
sbin/start-yarn.sh
执行完这两个命令后,Hadoop会启动并运行,执行 jps命令,会看到Hadoop相关的进程,如下图:
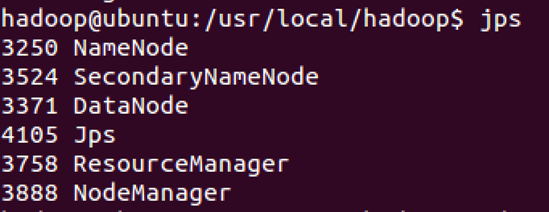
浏览器打开 http://localhost:50070/,会看到hdfs管理页面
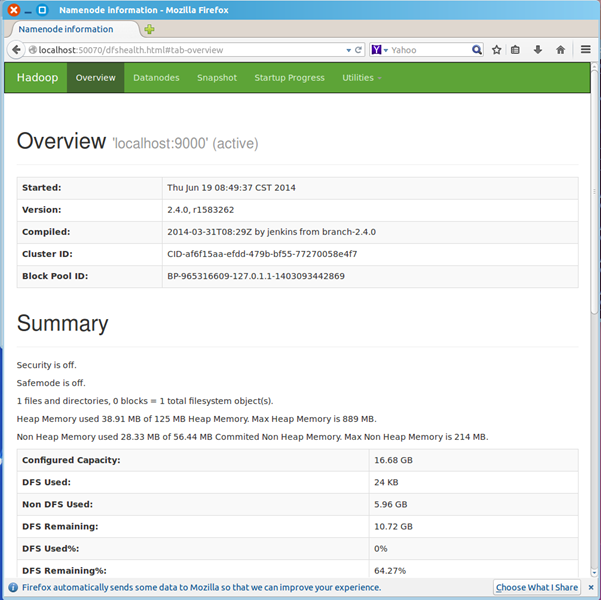
浏览器打开http://localhost:8088,会看到hadoop进程管理页面
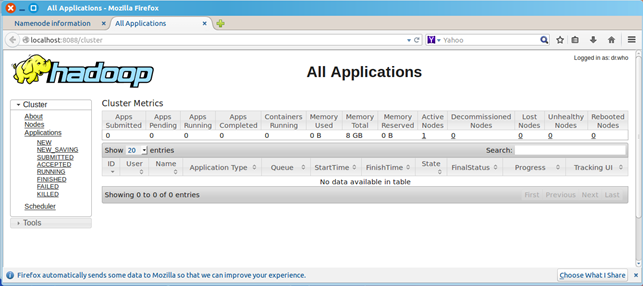
六、验证
dfs上创建input目录
bin/hadoop fs -mkdir -p input

把hadoop目录下的README.txt拷贝到dfs新建的input里
hadoop fs -copyFromLocal README.txt input

运行WordCount
hadoop jar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.4.0-sources.jar org.apache.hadoop.examples.WordCount input output

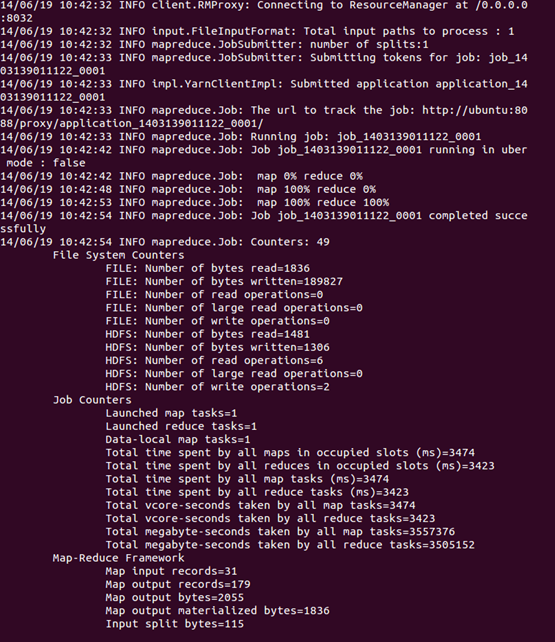
运行完毕后,查看单词统计结果
hadoop fs -cat output/*


 浙公网安备 33010602011771号
浙公网安备 33010602011771号