
联邦学习中的推理攻击
Inference Attacks in FL
在人工智能领域,推理攻击是提取没有公开的但攻击者感兴趣的信息。在联邦学习中,如果云聚合器是攻击者,那么其获知的信息可能包含模型参数、梯度、训练集的边界分布等等;其未知的信息可能包括客户端的训练集信息(图像内容、某特定成员信息、属性等)
推理攻击的分类
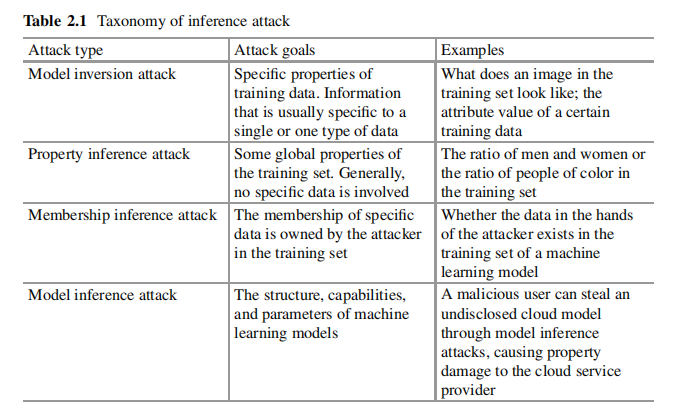
根据攻击者的目的分为:模型逆向攻击、属性推理攻击、成员推理攻击和模型推理攻击。
-
模型逆向攻击(Model inversion attacks)
模型逆向攻击又叫模型重构攻击(Model reconstruction attack, RA)。攻击者企图从模型中获取训练数据集的原始数据信息。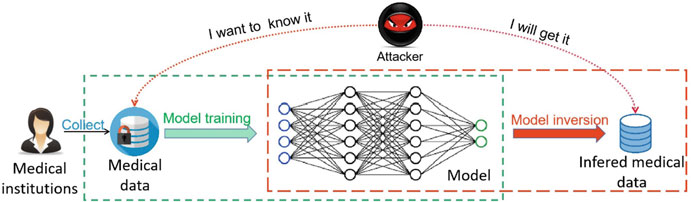
-
属性推理攻击(Property inference attacks, PIA)
攻击者企图获取训练数据集的统计信息,如某些属性人群的比例等。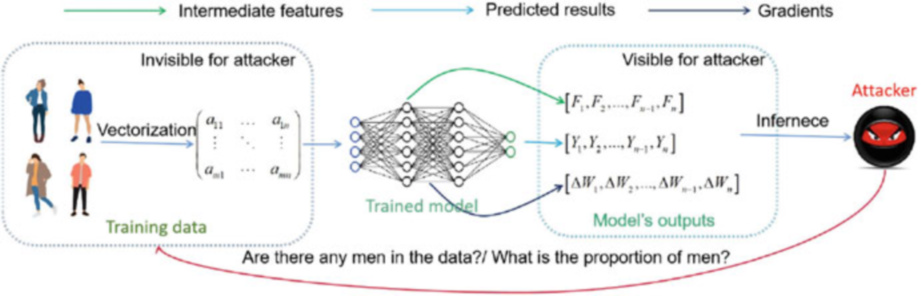
-
成员推理攻击(Membership inference attacks, MIA)
攻击者企图获知某一条给定数据是否在目标模型的训练集中(利用目标模型的输出推断)。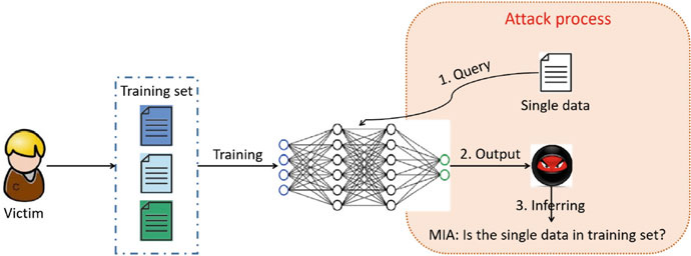
-
模型推理攻击(Model inference attacks)
模型推理攻击又叫模型提取攻击(Model extraction attack, MEA).目标是生成一个与目标模型相似的替代模型。模型推理攻击更常见于传统机器学习中,而不是联邦学习中。
联邦学习中的推理攻击
模型逆向攻击(重构攻击RA, Res)
在联邦学习中,重构攻击中的私有数据指客户端本地数据,公开数据指全局模型(中央服务器和客户端能够获取的)和梯度(中央服务器能够获取的)。因此可以进一步将联邦学习中的MIA分成两类:针对聚合梯度的攻击和针对全局模型的攻击。
针对聚合梯度的攻击
均方误差损失函数的定义:
反向传播算法中\(W\)和\(b\)如下计算:
可以通过以下两种方式重构客户端的输入\(x\):
- 可以发现\(\frac{\nabla W_{i}}{\nabla b}=x_{i}\)。因此客户端的隐私可能会在客户端上传梯度给中央服务器时泄露。
- \(\nabla W_{i}\) 和\(x_i\) 是成比例的,因此当中央服务器没有接收到\(\nabla b\) 时,原始数据可以通过调整比例值获取,尤其是当数据\(x_i\) 是图像时,通过可视化方式可以直观判断比例是否正确。
上述相同的攻击策略可以被应该用到有多个隐藏层的神经网络(即深度神经网络)中。深度神经网络的\(W\) 和\(b\) 梯度如下:
就有:
其中\(W_{i,k}^{1}\)和\(b_{i}^{1}\)代表第一个隐藏层的梯度和偏置;\(\lambda\)是正则化系数。
当\(\lambda=0\)时,\(\frac{\nabla W_{i,k}^{1}}{\nabla b_{i}^{1}}\)就是数据\(x\),而当\(\lambda>0\)时,\(\frac{\nabla W_{i,k}^{1}}{\nabla b_{i}^{1}}\)是数据\(x\)的近似值。
然而,这种方法并不适用于复杂神经网络,如卷积神经网络。为此,Zhu等人提出了一个梯度拟合方法——Deep Leakage from Gradients(DLG),该方法通过最小化噪声和全局模型下获得的原始数据之间的梯度差异来优化噪声,从而逐渐泄露原始数据。通过对噪声的优化,噪声将逐渐转化为与原始梯度对应的数据,即私有数据。
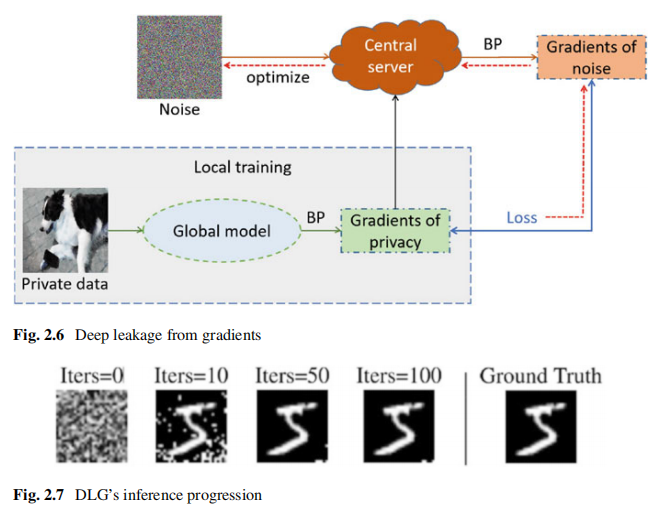
其中,\(\nabla_\theta\mathcal{L}_\theta(x,y)\)和\(\nabla_\theta\mathcal{L}_\theta\left(x^*,y\right)\)分别代表私有数据和噪声产生的梯度,\(d\)是一个距离度量函数。
值得注意的是,优化的推导需要一个二阶可推导的全局模型。因此,当全局模型的激活函数是一个二阶不可推导的函数时,如ReLU、leaky_ReLU等,则不能使用该方法。

其中,BP代表back-propagation algorithm,即反向传播算法。
作者还证明了重构攻击在聚合梯度上也可能存在。例如当攻击者获得聚合梯度\(\Delta W=\frac{1}{n}(\Delta w_{1}+\Delta w_{2}+\Delta w_{3}+\ldots+\Delta w_{n})
\)时,攻击者只需要知道\(n\)的值就可以推断出\(W_1\)到\(W_n\)对应的所有数据。此外,DLG除了能推理原始数据\(x\)之外,还可以推理原始数据的标签\(y\),但错误率很高。Zhao等人提出的Improved Deep Leakage from Gradients (iDLG)方法可以提高标签推理准确率。
使用独热编码的神经网络其交叉熵损失函数定义如下:其中\(x\)是输入,\(c\)是标签
根据反向传播算法,每个\(y\)对应的梯度定义如下:
通常来说,联邦学习中基于梯度的推理攻击只能在中央服务器实现。因此在这些方法中中央服务器被认为是恶意的。
针对全局模型的攻击
机器学习模型会在训练过程中会以某种方式“记住”训练数据,因此全局模型是否会泄露隐私值得关注。在联邦学习中,中央服务器和客户端共享全局模型和所有的细节。因此,不同于基于梯度的攻击,客户端和中央服务器都有可能被攻击者腐化来达到他们的恶意目标。
但联邦学习中大多数基于模型的攻击是依赖生成对抗网络方法或与基于梯度的攻击联合。Hitaj等人证明恶意客户端可以使用生成对抗网络执行重构攻击来获取客户端的隐私信息,把他们这种方法记作DMU-GAN。DMU-GAN获取的更像是一个平均样本,也就是说不是一个特定的样本点,而是对应于某一个特定标签的平均样本。然而在人脸识别中,其与基于梯度的攻击效果没什么不同,因为每个标签对应一个特定的人。另外DMU-GAN显著阻碍联邦学习的训练过程,这是的这种攻击非常容易被检测到。
属性推理攻击(PIA, Property Inference Attacks)
不同于重构攻击专注于推理数据集的数据表示,属性推理攻击更注意数据集的整体统计特征。
通常大多数属性推理攻击假设攻击者拥有和受害者数据集分布相同的辅助数据集,这在联邦学习设定中是合理的。属性推理攻击的核心思想是攻击者将辅助数据集分成几部分,为便于理解,假设分成两部分\(P\)和\(\bar{P}\),分别代表拥有属性\(p\)和不拥有属性\(p\)。攻击者分别利用这两个数据集训练连个影子模型。理论上其中一个影子模型会捕捉到属性\(p\),而其余影子模型则没有,这使得他们的输出有区别。接着攻击者利用这些拥有属性P的输出形成一个元数据集。使用元数据集可以训练判别模型,通过输出数据判断目标数据集是否含有属性P。
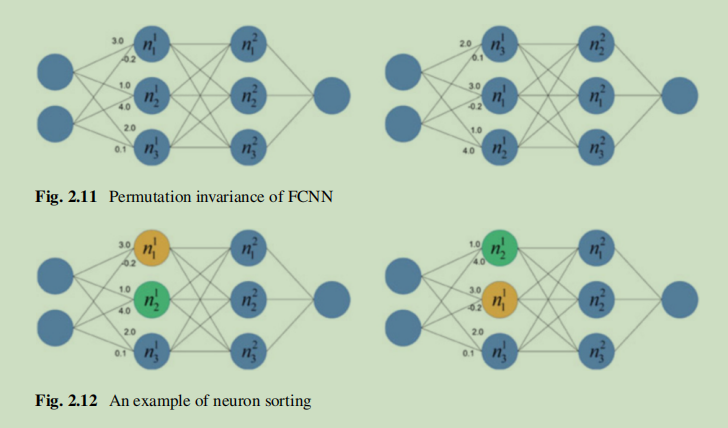
这种方法很直接,但只适用于传统机器学习模型,例如隐式马尔科夫链和支持向量机,而对于大多数主流深度神经网络失效。主要原因是全连接神经网络的排列不变性。而解决这个问题Ganju提出两种方法:1.神经元排序(根据对应权重总和对影子模型中每一层节点排序),这种方法通过输入预定模式消除了排序不变性的影响,然而这种方法没有考虑等效网络的影响,因为大量参数将给训练元分类器和影子模型带来巨大挑战 2.基于深度集的表示法,深度集允许输入具有排列不变性,而基于深度集的网络可以实现具有不变性的函数,如图集合\(A\)有三种不同的表示,但它们与顺序的不同在本质上是相同的。对于一个普通的神经网络\(F(·)\),元素的顺序会产生不同的输出。\(F'(·)\)满足排列不变性可以解决这个问题,并且输入结果是它应该的那样无论集合的元素顺序怎样。
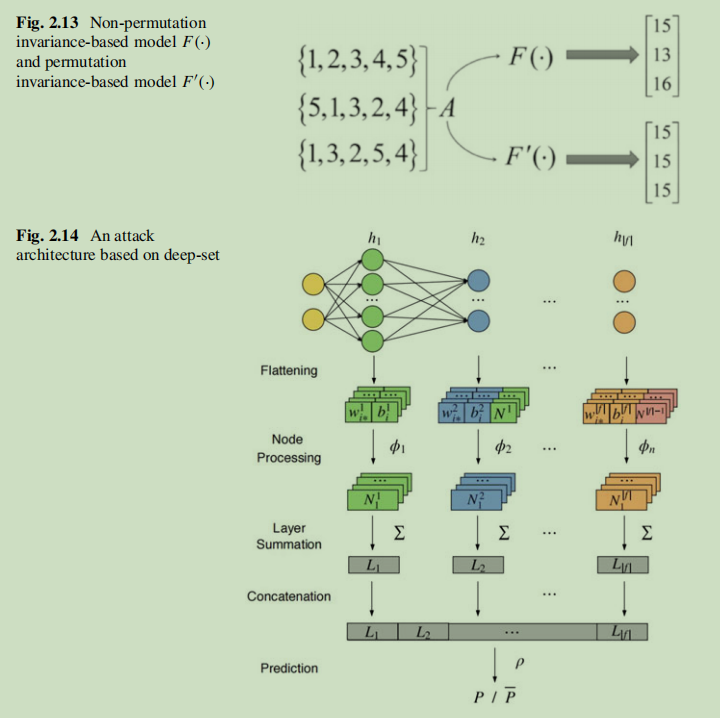
此外,Melis等人进一步将属性推理攻击融入联邦学习设置中。他们没有使用目标模型的输入作为元分类器的输入,而是使用联邦学习过程中的梯度作为输入,实验结果证明这种方法在推理与目标模型任务不相关的属性时更有效,并且可以应用在更复杂的数据集中。
成员推理攻击(MIA, Membership Inference Attacks)
在MIA中,攻击者对特定的数据点(例如,人、图像等)是否在受害者模型的训练集中感兴趣,这是联邦学习系统中一个严重的威胁。
基本思路:使用影子训练集建立一个影子模型来模拟目标模型的表现,之后通过影子模型获得影子训练集和影子测试集的相应输出,使用“在训练集中”和“不在训练集中”来分别标记这些输出。最后攻击者使用新构建的数据集来训练元分类器(也就是攻击模型)。该元分类器根据该实例对应的输出可以判断一个实例是否在目标模型的训练集中。
在成员推理攻击中,知识可以被粗略分为四个类别:数据知识、训练知识、模型知识和输出知识。
- 数据知识:数据知识决定了对手如何构建有效的影子训练集。
当敌手不能获得目标数据分布式,可以采用以下两种方法:- 统计合成:对手可能有一些统计信息,如某些特征的边缘分布。他们可以从这些边际分布中取样。
- 模型合成:如果攻击者既没有数据分布,也没有统计知识,他们可以利用目标模型获得阴影训练集。直觉是,由目标模型分类的具有高置信度的样本更有可能在统计上与目标训练集中的数据相似。
- 训练知识:训练知识是指训练过程中的一些超参数,如训练时代、优化器、学习速率等。
- 模型知识:模型知识主要是指模型结构,其中包括每个神经网络层所使用的结构和激活函数。
- 输出知识:输出知识决定了攻击者将从目标模型中获得什么样的反馈。
有三种主要的输出知识类型:- 敌手获得了完全输出的知识,这意味着他们知道每个类别的置信度。
- 敌手拥有部分输出知识,这意味着攻击者只能获得具有最高置信度的前k个。
- 敌手只能获得与输入对应的硬标签(没有置信度信息)。
在协同训练设置下,如果攻击者通过影响训练的中间结果来实现成员推理攻击,那么我们将这种攻击称为主动攻击(如模型逆向攻击、属性推理攻击),否则称为被动攻击。
Shokri等人的论文中提出了三个强假设:
- 需要训练多个影子模型,这大大增加了攻击的成本。
- 攻击者需要了解目标模型的结构,并将其作为影子模型的结构。
- 攻击者必须知道目标分布,才能实现有效的攻击。
这些假设虽然在某些场景能实现,但这严重阻碍了成员推理攻击的广泛使用。

Li等人首先使用一个影子模型来拟合目标模型的行为,使影子模型输出的概率分布与目标模型输出的概率分布相等。其次,他们利用影子模型上目标数据的损失来确定目标数据是否在目标训练集中。 此外,他们还结合了对抗性攻击的思想,并通过对抗性扰动的大小来判断目标样本的隶属度。直觉是,目标模型在训练集上的判断模型通常是非常鲁棒的;因此,它需要比其他样本更多的扰动来改变标签。
模型推理攻击
模型推理攻击的目的是获取公众认为不知道的信息,如目标模型的结构和参数。
防御推理攻击
-
基于机器学习优化的防御
-
学习机制
模型过拟合的主要原因之一是模型容量的规模较大。因此,一般来说,在相同的条件下,一个规模更大的网络更有能力进行训练,更容易记住相关信息,从而导致过拟合,这使得过拟合的网络很容易受到推理攻击。 -
正则化
正则化的目的是优化模型的性能。 正则化并不改变模型的结构。它将使一定的模型参数接近于0,以减少其对模型的影响。 此外,这些参数所捕获的特征的权重将显著减少,但不会完全丢失。因此,它比过拟合更柔和一些,但它也使模型容易受到推理攻击。 -
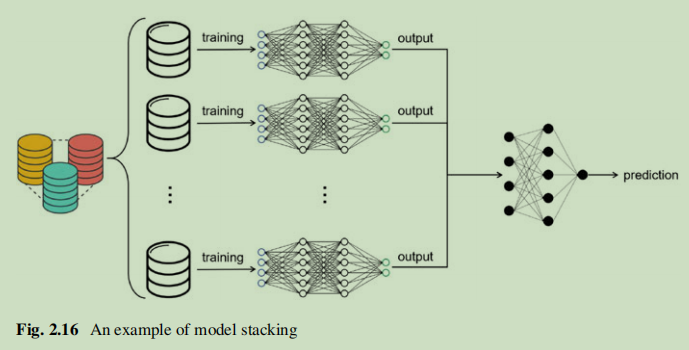
模型堆叠
模型叠加本质上是一种集成学习。它通过将训练集分成成对的不相交的集合,使用训练集训练多个模型,然后将它们组合成一个聚合的模型来进行预测。该方法可以有效地提高模型的推广性。此外,与前两种方法相比,它可以更好地减轻推理攻击。
-
-
基于扰动的防御
推理攻击使用现有知识\(K\)来推断未知数据U。人们很难不去思考\(K\)和\(U\)之间的特定关系是否支持推理攻击的可能性。破坏这种关系最简单的方法之一是向\(K\)添加噪声。差分隐私(DP)是目前广泛研究的扰动方法之一,例如在基于梯度的重构攻击中对梯度添加扰动;在属性推理攻击中对模型输出添加扰动以及在对模型参数添加扰动。一般来说,防御者可以干扰优化算法、模型参数、中间模型结果(如梯度)、模型输出等。 -
知识蒸馏
Hinton等人提出了一种基于模型压缩的知识蒸馏技术。 Shejwalkar等人应用了知识蒸馏来对抗推理攻击。他们最小化了学生模型和教师模型输出之间的KL散度(信息论中流行的距离度量),避免了直接使用特定的数据集来训练学生模型(用于部署),从而在一定程度上减轻了推理攻击。Kaya等人比较了知识蒸馏和各种正则化技术,实验表明知识蒸馏是一种有效的防御方法。然而,它们中没有一个在最先进的攻击设置下被实验验证,而且大多数的防御只能用一个公共训练集来构建。 -
对抗机器学习
对抗性机器学习的主要思想是,当训练或部署模型时,防御者从他的角度优化模型。目前的对抗性机器学习主要可分为两大类:- 在训练阶段,防御者将现有的攻击策略作为模型训练过程的正则化项添加到模型训练过程中。例如,在MIA中,最大限度化攻击模型的损失,最小化模型效用的损失,形成最小-最大博弈。显然,这将不可避免地降低目标模型的效用。
- 在预测阶段,由于攻击模型以目标模型的输出作为输入,并且攻击模型容易受到对抗性样本的影响,因此,防御者可以对目标模型的输出添加复杂的扰动,将其变成一个对抗性的样本,从而减轻攻击。这种防御策略可以缓解由于隐私保护和模型效用的权衡所造成的问题
-
基于加密的方法
同态加密是目前最有前途的隐私保护方法。例如,敌手可以在联邦学习中基于梯度执行模型逆向攻击。但是,如果梯度采用同态加密进行加密,它不仅可以完成梯度的聚合操作,还可以防止MIAs。然而,加密方法经常带来很高的通信和计算成本。因此,它很难在大规模的应用程序中实现。此外,对于基于目标模型输出的攻击(如机器学习即服务场景中的攻击),加密并不是一种有效的防御方法。

