Spark相关
Apache Zeppelin是一个让交互式数据分析变得可行的基于网页的开源框架。
Zeppelin提供了数据分析、数据可视化等功能,方便你做出可数据驱动的、可交互且可协作的精美文档,
并且支持多种语言,包括 Scala(使用 Apache Spark)、Python(Apache Spark)、SparkSQL、 Hive、 Markdown、Shell等。
如图
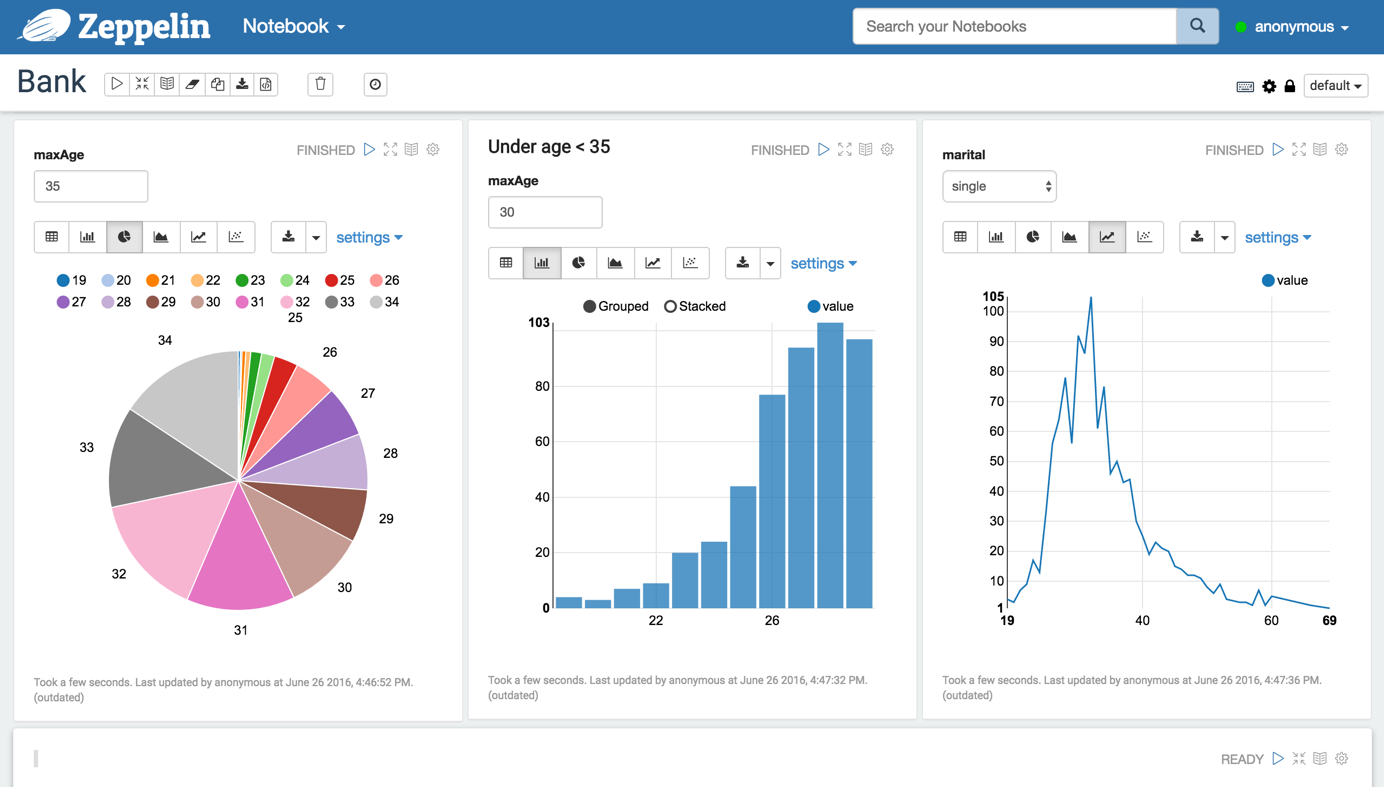
Zeppelin内置了对Spark的集成,提供了:
- 自动地SparkContext和SQL Context的注入
- 运行时自动从本地文件系统或者maven库导入依赖的jar。
- 取消job,并且显示他的进度。
安装使用
Zeppelin是Apache的一个孵化项目,目前最新的版本是0.5.6,支持Spark1.6.0。可以直接下载二进制包或者
源码包编译安装。
下面是一个用scala从hdfs上读取数据,然后用sql进行分析的例子
1 | val bankText = sc.textFile("hdfs://localhost:19000/home/qixia/zeppelin/bank/bank-full.csv") |

进阶配置
Zeppelin的工作方式和Spark的Thrift Server很像,都是向Spark提交一个应用(Application),然后每一个查询对应一个stage。
因此,在启动Zeppelin前,可以通过配置环境变量ZEPPELIN_JAVA_OPTS来对即将启动的Spark driver进行配置,例如"-Dspark.executor.memory=8g -Dspark.cores.max=64"。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号