总结1016
美女不能少

文件处理
文件处理方法
1.文件的概念
就是操作系统暴露给用户操作硬盘的快捷方式
2.代码打开文件的两种方式
方式1:
f = open(文件路径,读写模式,encoding='utf8')
f.close()
方式2:
with open('a.txt','r',encoding='utf8')as f1:
with子代码块
ps:with上下文管理好处在于子代码运行结束自动调用close方式关闭资源
with支持一次性打开多个文件
with open() as f1,open()as f2,open()asf3:
子代码
注意:
open方法的第一个参数是文件路径 并且撬棍跟一些字母的组合会产生特殊的含义导致路径查找混乱 为了解决该问题可以在字符串的路径前面加字母r
D:\a\n\t
r'D:\a\n\t'
以后涉及到路径的编写 推荐加上r
文件的读写模式
'r' 只读模式:只能读不能写
1.文件路径不存在:会直接报错
2.文件路径存在: 正常读取文件内容
'w' 只写模式:只能写不能看
1.文件路径不存在:自动创建
2. 文件路径存在:先清空文件内容 之后再写入
强调:换行符需要自己添加 并且再后续数据读取比对的时候也一定要注意它的存在
'a' 只追加模式:文件末尾添加数据
1.文件路径不存在:自动创建
2. 文件路径存在:自动在末尾等待追加内容
小知识
"""
当我们在编写代码的时候 有些部分不知道写什么具体代码 但是也不能空着不写
这个时候可以使用关键字
pass
...
只补全语法不执行功能 本身没有任何的含义
"""
文件的操作模式
t 文本模式
默认的模式 我们上面所写的 r w a 其实全称是rt wt at
1.只能操作文本文件
2.读写都是以字符为单位
3.需要指定encoding参数 如果不知道则会采用计算机默认的编码
b 二进制模式(bytes模式)
不是默认的模式 需要自己指定 rb wb ab
1.可以操作任意类型的文件
2.读写都是以bytes为单位
3.不需要指定encoding参数 因为它已经是二进制模式了 不需要编码
二进制模式与文本模式针对文件路径是否存在的情况下 规律是一样的!!!
文件的诸多方法
1.read()
一次性读取文件内容 并且光标停留在文件末尾 继续读取则没有内容
并且当文件内容比较多的时候 该方法还可能会造成计算机内存溢出
括号还可以填写数字 在文本模式下 表示读取几个字符
2.for 循环
一行行读取文件内容 避免内存溢出现象的产生
3.readline()
一次只读一行内容
4.readlines()
一次性读取文件内容 会按照行数组织成类列表的一个个数据值
5.readable()
判断文件是否具备读数据的能力
6.write()
写入数据
7.writeable()
判断文件是否具备写数据的能力
8.writelines()
接收一个列表 一次性将列表中所有的数据值写入
9.flush()
将内存中文件数据立刻刷到硬盘 等价于ctrl+s
文件内光标的移动
"""
seek(offset, whence)
offset是位移量 以字节为单位
whence是模式 0 1 2
0是基于文件开头
文本和二进制模式都可以使用
1是基于当前位置
只有二进制模式可以使用
2是基于文件末尾
只有二进制模式可以使用
"""
计算机硬盘修改数据的原理(了解)
硬盘写数据可以看成是在硬盘上刻字 一旦需要修改中间内容 则需要重新刻字
因为刻过的字不可能从中间再分开
硬盘删除数据的原理
不是直接删除而是改变状态 等待后续数据的覆盖才会被真正删除
文件内容修改(了解)
方式1:覆盖写(建立在有a.txt文件的情况下)
with open(r'a.txt', 'r',encoding='utf8')as f:
data = f.read()
with open(r'a.txt', 'w', encoding='utf8')as f1:
f1.write(data.replace('哈哈','嘿嘿'))
方式2:换地方写
import os
with open('a.txt', 'r', encoding='utf8') as read_f, \
open('.a.txt.swap', 'w', encoding='utf-8') as write_f:
for line in read_f:
write_f.write(line.replace('小明', 'kevinSB'))
os.remove('a.txt') # 删除a.txt
os.rename('.a.txt.swap', 'a.txt') # 重命名文件
函数
函数前夕
循环
相同的代码在相同的位置反复执行
函数
相同的代码在不同的位置反复执行
ps:相同的代码不是真正一模一样而是可以通过传入的数据不同而做出不同的改变
函数相当于工具(具有一定功能)
不用函数
修理工需要修理器件要用锤子 原地打造 每次用完就扔掉 下次用继续原地打造
用函数
修理工提前准备好工具 什么时候想用就直接拿出来使用
函数的语法结构
def 函数名(参数):
'''函数注释'''
函数体代码
return返回值
1.def
定义函数的关键字
2.函数名
命名等同于变量名(尽量见名知意)
3.参数
可有可无 主要是在使用函数的时候规定要不要外界传数据进来
4.函数注释
类似于工具说明书
5.函数体代码
是整个函数的核心 主要取决于程序员的编号
6.return
使用函数之后可以返回给使用者的数据 可有可无
函数的定义与调用
1.函数在定义阶段只检测语法 不执行代码
def func():
pass
2.函数在调用阶段才会执行函数体代码
func()
3.函数必须先定义后调用
4.函数定义使用关键字def 函数调用使用>>>:函数名加括号
如果有参数则需要在括号内按照相应的规则传递参数(后续详细讲解)
函数的分类
1.空函数
函数体代码为空 使用的pass或者...补全的
空函数主要用于项目前期的功能框架
2.无参函数
定义函数的时候括号内没有参数
3.有参函数
定义函数的时候括号内写参数 调用函数的时候括号传参数
函数的返回值
1.什么是返回值
调用函数之后返回给调用者的结果
2.如何获取返回值
变量名 赋值符号 函数的调用
res = func() # 先执行func函数 然后将返回值赋值给变量res
3.函数返回值的多种情况
3.1函数体代码中没有return关键字 默认返回None
3.2函数体代码有return 如果后面没有写任何东西还是返回None
3.3函数体代码有return 后面写什么就返回什么
3.4函数体代码有return并且后面有多个数据值 则自动组织成元组返回
3.5函数体代码遇到return会立刻结束
函数的参数
越短的越简单的越靠前
越长的越复杂的越靠后
但是遇到下列的情况除外
同一个形参在调用的时候不能多次赋值
形式参数
在函数定义阶段括号内填写的参数 简称'形参'
实际参数
在函数调用阶段括号内填写的参数 简称'实参'
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
形参与实参的关系
形参类似于变量名 在函数定义阶段可以随便写 最好见名知意
def refister(name,pwd):
pass
实参类似于数据值 在函数调用阶段与形参临时绑定 函数运行结束立刻断开
register('jason',123) 形参name与jason绑定 形参pwd与123绑定
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
函数参数之位置参数
"""
补充:当子代码只有一行并且很简单的情况下 可以直接在冒号后编写 不用换行
"""
位置形参
函数定义阶段括号内从左往右依次填写的变量名
def func1(a, b, c):pass
位置实参
函数调用阶段括号内从左往右依次填写的数据值
func1(1, 2, 3)
默认参数
本质其实就是关键字形参
别名叫默认参数:提前就已经给了 用户可以不传 也可以传
'''默认参数的定义也遵循短的简单的靠前 长的复杂的靠后'''
可变长形参
*号在形参中
用于接收多余的位置参数 组织成元组赋值给*号后面的变量名
**号在形参中
用于接收多余的关键字参数 组织成字典的形式赋值给**号后面的变量名
"""
由于*和**在函数的形参中使用频率很高 后面跟的变量名推荐使用
*args
**kwargs
def index(*args, **kwargs):pass
"""
可变长实参
*在实参中
类似于for循环 将所有循环遍历出来的数据按照位置参数一次性传给函数
**在实参中
将字典打散成关键字参数的形式传递给函数
命名关键字参数(了解)
'''形参必须按照关键字参数传值>>>:命名关键字参数'''
def index(name,*args,gender='male',**kwargs):
print(name,args,gender,kwargs)
# index('jason',1,2,3,4,a=1,b=2)
index('jason', 1, 2, 3, 4, 'female', b=2)
名称空间
名称空间概念
"""
name = 'jason'
1.申请内存空间存储jason
2.给jason绑定一个变量名name
3.后续通过变量名name就可以访问到jason
"""
名称空间就是用来存储变量名与数据值绑定关系的地方(我们也可以简单的理解为就是存储变量名的地方)
1.内置名称空间
解释器运行自动产生 里面包含了很多名字
eg:len print input
2.全局名称空间
py文件运行产生 里面存放文件级别的名字
3.局部名称空间
函数体代码运行\类体代码运行 产生的空间
名称空间存活周期及作用范围(域)
存活周期
内置名称空间
python解释器启动则创建 关闭则销毁
全局名称空间
py文件执行则创建 运行结束则销毁
局部名称空间
函数体代码运行创建 函数体代码结束则销毁(类暂且不考虑)
作用域
内置名称空间
解释器级别的全局有效
全局名称空间
py文件级别的全局有效
局部名称空间
函数体代码内有效
名字的查找顺序
涉及到名字的查找 一定要先搞明白自己在哪个空间
1.当我们在局部名称空间中的时候
局部名称空间 >>> 全局名称空间 >>> 内置名称空间
2.当我们在全局名称空间中的时候
全局名称空间 >>> 内置名称空间
ps:其实名字的查找顺序是可以打破的 需要用关键字 global nonlocal
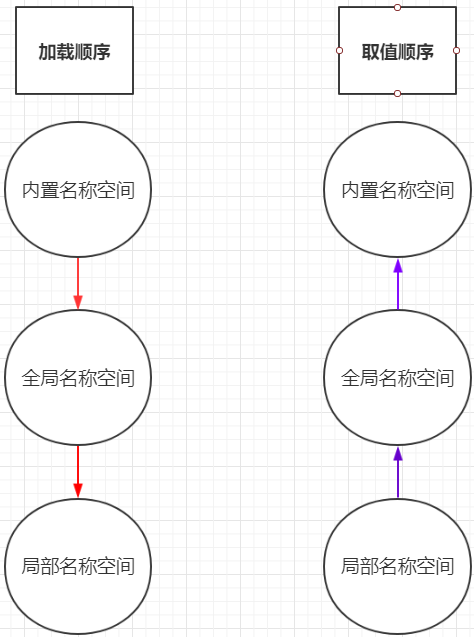
查找顺序案例
1.相互独立的局部名称空间默认不能够互相访问
def func1():
name = 'jason'
print(age)
def func2():
age = 18
print(name)
2.局部名称空间嵌套
先从自己的局部名称空间查找 之后由内而外依次查找
"""
函数体代码中名字的查找顺序在函数定义阶段就已经固定死了
x = '干饭了'
def func1():
x = 1
def func2():
x = 2
def func3():
print(x)
x = 3
func3()
func2()
func1()
"""
globaly与nonlocal关键字
globaly
局部名称空间直接修改全局名称空间中的数据
nonlocal
内层局部名称空间修改外层局部名称空间中的数据
函数名的多种用法
函数名其实绑定的也是一块内存地址 只不过该地址里面存放的不是数据值而是一段代码 函数名加括号就会找到该代码并执行
1.可以当作变量名赋值
2.可以当作函数的参数
3.可以当作函数的返回值
4.可以当作容器类型(可以存放多个数据的数据值类型)的数据
装饰器
闭包函数
定义在函数内部的函数,并且用到了外部名称空间的名字
1.定义在函数内部
2.用到外部函数名称空间中的名字
补充:两种给函数体代码传参的方式:
1.里面缺什么变量名形参就补什么变量名
2.闭包函数
装饰器简介
1.概念
在不改变被装饰对象原代码和调用方式的情况下给被装饰对象添加新的功能
2.本质
并不是一门新的技术 而是由函数参数、名称空间、函数名多种用法、闭包函数组合到一起的结果
3.口诀
对修改封闭 对扩展开放
4.储备知识
时间相关操作
import time
# print(time.time()) # 时间戳(距离1970-01-01 00:00:00所经历的秒数)
time.sleep(3)
print('睡醒了 干饭')
count = 0
# 循环之前先获取时间戳
start_time = time.time()
while count < 100:
print('哈哈哈')
count += 1
end_time = time.time()
print('循环消耗的时间:', end_time - start_time)
装饰器推导流程
import time
# def index():
# time.sleep(2)
# print('from index')
#
#
# def home():
# time.sleep(3)
# print('from home')
# start_time = time.time()
# index()
# end_time = time.time()
# print('函数index的执行时间为>>>',end_time - start_time)
'''1.直接在调用index函数的前后添加代码'''
# start_time = time.time()
# index()
# end_time = time.time()
# print('函数index的执行时间为>>>',end_time - start_time)
'''2.index调用的地方较多 代码不可能反复拷贝>>>:相同的代码需要在不同的位置反复执行>>>:函数'''
# def get_time():
# start_time = time.time()
# index()
# end_time = time.time()
# print('函数index的执行时间为>>>',end_time - start_time)
# get_time()
'''3.函数体代码写死了 只能统计index的执行时间 如何才能做到统计更多的函数运行时间 直接传参变换统计的函数'''
#
# def get_time(xxx):
# start_time = time.time()
# xxx()
# end_time = time.time()
# print('函数的执行时间为>>>', end_time - start_time)
#
#
# get_time(index)
# get_time(home)
'''4.虽然实现了一定的兼容性 但是并不符合装饰器的特征 第一种传参不行 只能考虑闭包'''
# def outer(xxx):
# # xxx = index
# def get_time():
# start_time = time.time()
# xxx()
# end_time = time.time()
# print('函数的执行时间为>>>', end_time - start_time)
# return get_time
# res = outer(index)
# res()
# res1 = outer(home)
# res1()
'''5.调用方式还是不对 如何变形>>>:变量名赋值绑定(**********)'''
# def outer(xxx):
# # xxx = index
# def get_time():
# start_time = time.time()
# xxx()
# end_time = time.time()
# print('函数的执行时间为>>>', end_time - start_time)
#
# return get_time
# res = outer(index)
# res1 = outer(index)
# res2 = outer(index)
# jason = outer(index)
# index = outer(index)
# index()
# home = outer(home)
# home()
'''6.上述装饰器只能装饰无参函数 兼容性太差'''
# def func(a):
# time.sleep(3)
# print('from func', a)
# # func(123)
#
# def func1(a, b):
# time.sleep(2)
# print('from func1', a, b)
#
# def func2():
# time.sleep(2)
# print('from func2')
# def outer(xxx):
# def get_time(a,b):
# start_time = time.time()
# xxx()
# end_time = time.time()
# print('函数的执行时间为>>>', end_time - start_time)
# return get_time
# func1 = outer(func1)
# func(1,2)
# func = outer(func)
# func(1)
# func2 = outer(func2)
# func2()
'''7.被装饰的函数不知道没有参数以及几个参数 如何兼容'''
# def func(a):
# time.sleep(3)
# print('from func', a)
#
# def func1(a, b):
# time.sleep(2)
# print('from func1', a, b)
#
# def outer(xxx):
# def get_time(*args, **kwargs): # get_time(1,2,3) args = (1,2,3)
# start_time = time.time()
# xxx(*args, **kwargs) # xxx(*(1,2,3)) xxx(1,2,3)
# end_time = time.time()
# print('函数的执行时间为>>>', end_time - start_time)
# return get_time
# func = outer(func)
# func(123)
# func1 = outer(func1)
# func1(1,2)
'''8.如果被装饰的函数有返回值'''
def func(a):
time.sleep(3)
print('from func', a)
return 'func'
def func1(a, b):
time.sleep(2)
print('from func1', a, b)
return 'func1'
def outer(xxx):
def get_time(*args, **kwargs):
start_time = time.time()
res = xxx(*args, **kwargs)
end_time = time.time()
print('函数的执行时间为>>>', end_time - start_time)
return res
return get_time
# func = outer(func)
# res = func(123)
# print(res)
func1 = outer(func1)
res = func1(123,333)
print(res)
装饰器模板
################### 必须掌握 #######################
def outer(func): # 形参func将来用于绑定真正被装饰对象的内存地址
def inner(*args, **kwargs):
# 执行被装饰对象之前可以作的操作
res = func(*args, **kwargs)
# 执行被装饰对象之后可以作的额外操作
return res
return inner
装饰器语法糖
def outer(func):
def inner(*args, **kwargs):
print('执行被装饰对象之前可以作的操作')
res = func(*args, **kwargs)
print('执行被装饰对象之后可以作的额外操作')
return res
return inner
@outer # func = outer(func)
def func():
print('from func')
return 'func'
@outer # index = outer(index)
def index():
print('from index')
return 'index'
func()
index()
多层语法糖
有参装饰器
# 校验用户是否登录装饰器
def outer(mode):
def login_auth(func_name):
def inner(*args, **kwargs):
username = input('username>>>:').strip()
password = input('password>>>:').strip()
if mode == '1':
print('数据直接写死')
elif mode == '2':
print('数据来源于文本文件')
elif mode == '3':
print('数据来源于字典')
elif mode == '4':
print('数据来源于MYSQL')
return inner
return login_auth
'''当装饰器种需要额外的参数时>>>:有参装饰器'''
"""
函数名加括号执行优先级最高 有参装饰器的情况
先看函数名加括号的执行
然后再是语法糖的操作
"""
@outer('1') # 需要传值
def index():
print('from index')
index()
@outer('2')
def func():
print('from func')
func()
两大装饰器模板
装饰器修复技术
from functools import wraps
def outer(func_name):
@wraps(func_name) # 仅仅是为了让装饰器的效果更加逼真 平时可以不写
def inner(*args, **kwargs):
"""我是inner 我擅长让人懵逼"""
res = func_name(*args, **kwargs)
return res
return inner
@outer
def func():
"""我是真正的func 我很强大 我很牛 我很聪明"""
pass
help(func)
print(func)
func()
递归函数
1.函数的递归调用
函数直接或间接的调用了函数自身
# 直接调用
# 间接
'''最大递归深度:python 解释器添加的安全措施'''
'''官网提供的最大递归深度为1000 我们在测试的时候可能会出现996 997 998'''
2.递归函数
1.直接或者间接调用自己
2.每次调用都必须比上一次简单 并且需要有一个明确的结束条件
递推:一层层往下
回溯:基于明确的结果一层层往上
算法及二分法
1.什么是算法
算法就是解决问题的有效方法 不是所有的算法都很高效也有不合格的算法
2.算法应用场景
推荐算法(抖音视频推送 淘宝商品推送)
成像算法(AI相关)......
几乎涵盖了我们日常生活中的方方面面
3.算法工程师要求
待遇非常好 但是要求也非常高
4.算法部门
不是所有的互联网公司都养得起算法部门 只有大型互联网公司才有
算法部门类似于药品研发部门
5.二分法
是算法中最简单的算法 甚至都称不上是算法
"""
二分法使用要求
待查找的数据集必须有序
二分法缺陷
针对开头结尾的数据 查找效率很低
常见算法的原理以及伪代码
二分法、冒泡、快排、插入、堆排、统排、数据结构(链表 约瑟夫问题 如何链表是否成环)
"""
查找数据中某个值
# 方式1:for循环 次数较多
# 方式2:二分法 不断的对数据集做二分切割
'''代码实现二分法'''
l1 = [12, 21, 32, 43, 56, 76, 87, 98, 123, 321, 453, 565, 678, 754, 812, 987, 1001, 1232]
def get_middle(l1, target_num):
# 添加一个具体的结束条件
if len(l1) == 0:
print('很抱歉 没找到')
return
# 1.获取列表中的索引值
middle_index = len(l1) // 2
# 2.比较目标数据值与中间索引值的大小
if target_num > l1[middle_index]:
# 切片保留列表右边一半
right_l1= l1[middle_index + 1 :]
print(right_l1)
# 针对右边一般的列表继续二分并判断
return get_middle(right_l1, target_num)
if target_num < l1[middle_index]:
# 切片保留列表左边一半
lift_l1 = l1[:middle_index]
print(lift_l1)
# 针对左边一般的列表继续二分并判断
return get_middle(lift_l1,target_num)
else:
print('恭喜你 找到了')
# get_middle(l1,987)
get_middle(l1,10000)
各种表达式
三元表达式
# 简化步骤1: 代码简单并且只有一行 那么可以直接在冒号后面编写
name = 'jason'
# if name == 'jason':print('老师')
# else:print('学生')
# 三元表达式
res = '老师' if name == 'jason' else '学生'
print(res)
"""
数据值1 if 条件 else 数据值2
条件成立则使用数据值1 条件不成立则使用数据值2
当结果是二选一的情况下 使用三元表达式较为简便
并且不推荐多个三元表达式嵌套
"""
各种生成式 推导式
name_list = ['jason', 'kevin','oscar','tony','jerry']
# 给列表中所有人名的后面加上_NB的后缀
# 列表生成式
# new_list = [name + '_NB' for name in name_list]
# print(new_list)
# 复杂情况
new_list = [name + '_NB' for name in name_list if name == 'jason']
print(new_list)
new_list = ['大佬' if name == 'jason' else '小赤佬' for name in name_list if name != 'berk']
print(new_list)
# 字典生成式
# s1 = 'hello'
# for i,j in enumerate(s1):
# print(i, j)
d1 = {i:j for i , j in enumerate('hello')} 枚举
print(d1) # {0: 'h', 1: 'e', 2: 'l', 3: 'l', 4: 'o'}
# 集合生成式
res = {i for i in 'hello'}
print(res)
# 元组没有生成式: 下列的结果是生成器
res = (i+'sb' for i in 'hello')
print(res)
for i in res:
print(i)
函数内置方法
匿名函数
没有名字的函数 需要使用关键字lambda
语法结构
lambda 形参:返回值
使用场景
lambda a, b :a+b
匿名函数一般不单独使用 需要配合其他函数一起用
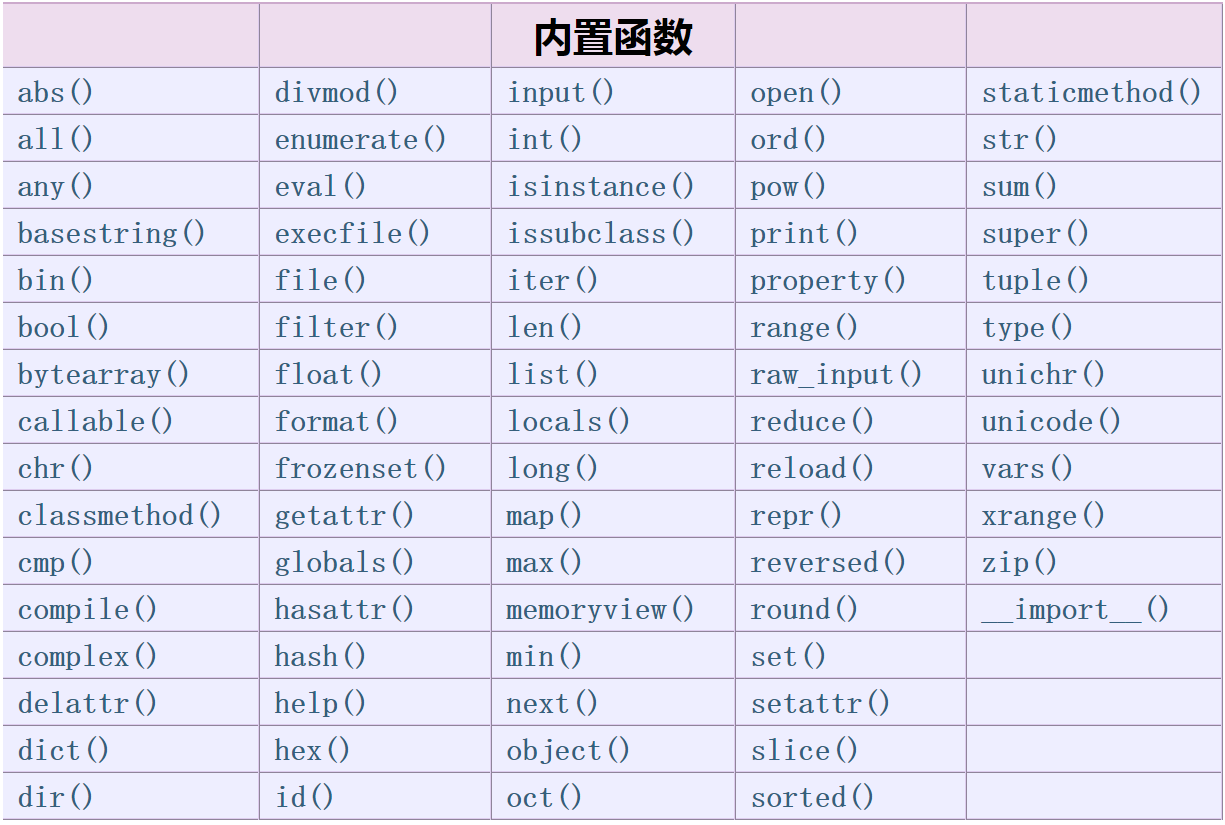
重要的内置函数
1.map() 映射
l1 = [1, 2, 3, 4, 5]
# def func(a):
# return a+1
res = map(lambda x:x+1, l1)
print(list(res))
2.max()\min()
l1 = [11, 22, 33, 44]
res = max(l1)
d1 = {'zj':100,
'jason': 99999,
'bekr':888080,
'jerry':45455454
}
def func(a):
return d1.get(a)
# res = max(d1,key=lambda k:d1.get(k))
res = max(d1, key=func)
print(res)
3.reduce
传多个值 返回一个值
把列表中所有的数值加一起
from functools import reduce
l1 = [11, 22, 334, 4555, 666, 777, 8888, 222323]
res = reduce(lambda a, b: a + b, l1)
print(res)
4.zip 多个数据集合 组合 一一对应,如果那个集合数据比较多,多出部分 直接丢掉
l1 = [11, 22, 33, 44, 55]
l2 = ['jason', 'kevin', 'oscar', 'jerry', 'tony']
l3 = [1, 2, 3, 4, 5]
res = zip(l1, l2, l3)
print(list(res))
l1 = [11, 22, 33]
l2 = ['jason', 'kevin', 'oscar', 'jerry', 'tony']
l3 = [1, 2, 3, 4]
res = zip(l1, l2, l3)
print(list(res))
5.filter 过滤 统计列表中比40大的值
l1 = [11,22,33,44,55,66,778,888]
res = filter(lambda x: x > 40, l1)
print(list(res))
6.sorted 排序
l1 = [21,12,53,64,88,44,333,555]
res = sorted(l1)
print(res) # 默认升序
常见的内置函数
# 1.abs() 绝对值
# print(abs(-100)) # 100
# print(abs(100)) # 100
# 2.all() 所有数据值对应的布尔值为True结果才是True否则返回Flase
# print(all([0,1, 2, 3])) # False
# print(all([1, 2, 3, True])) # True
# 3.any() 所有数据值对应的布尔值又一个为 True结果就是True 否则返回Flase
# print(any([0, None, '', 1])) # True
# print(any([0, None, '', ])) # False
# 4.bin() oct() hex() int()
# 5.bytes() 转换成bytes类型
# s1 = '今天周五 内容也简单'
# print(s1.encode('utf8'))
# print(bytes(s1,'utf8'))
# 6.callable() 判断名字是否可以加括号调用
# name = 'jason'
# def index():
# print('from index')
# print(callable(name)) # False
# print(callable(index)) # True
# 7.chr() ord() 基于ASCII码做数字与字母的转换
# print(chr(65)) # A
# print(ord('A')) # 65
# 8.dir() 返回括号内对象能够调用的名字
# print(dir('hello')) # 内置函数
# 9.divmod() 元组 第一个数据为整除数 第二个是余数
# res = divmod(100, 2)
# print(res) # (50, 0)
# res = divmod(100, 3)
# print(res) # (33, 1)
"""
总数据 每页展示的数据 总页码
100 10 10
99 10 10
101 10 11
"""
# page_num, more = divmod(999999, 21)
# print(divmod(99999, 10)) # (9999, 9)
#
# if more:
# page_num += 1
# print('总页码为:',page_num) # 总页面为: 47619
# 10.enumerate() 枚举
# # 11.dval() exec() 能够识别字符串中的python并执行
# s1 = 'print("哈哈哈")'
# eval(s1)
# exec(s1)
# s2 = 'for i in range(100):print(i)'
# eval(s2) # 报错 # 只能识别简单的python代码 具有逻辑性的都不行
# exec(s2) # 可以识别具有一定逻辑性的python代码
# 12.hash() 哈希加密
# print(hash('jason'))
# 13.id()数据的地址 input()输入 isinstance()输入两个值 第二个值判断第一个值是不是输入的类型
# 14.open() 打开文件
# 15.pow() 幂指数(次方) **
# 16.range() 工厂 顾头不顾尾
# 一个值 0-该数值前一个
# 两个值 从第一个开始到后面的值前一个
# 三个值 输出等差数列 第三个值为等差值
# 17.round() 五舍六入 应该是python对数值不敏感导致
# print(round(98.3)) # 98
# print(round(98.5)) # 98
# print(round(98.6)) # 99
# 18.sum() 求和
# print(sum([11, 22, 33, 44, 55, 66, 77])) # 308
迭代器
==可迭代对象
1.可迭代对象
对象内置有__iter__方法的都称为可迭代对象
"""
1.内置方法 通过点的方式能够调用的方法
2.__iter__ 双下iter方法
"""
2.可迭代对象的范围
不是可迭代对象
int float bool 函数对象
是可迭代对象
str list dict tuple set 文件对象
3.可迭代的含义
"""
迭代:更新换代(每次更新都必须依赖上一次的结果)
eg:手机app更新
"""
可迭代对象在python中可以理解为是否支持for循环
迭代器对象
1.迭代器对象
是有可迭代对象调用__iter__方法产出的
迭代器对象判断的本质是看是否内置有__iter__和__next__
2.迭代对象的作用
提供了一种不依赖于索引取值的方式
正因为有迭代器的存在 我们的字典 集合才能够被for循环
3.迭代器对象实操
s1 = 'hello' # 可迭代对象
res = s1.__iter__() # 迭代器对象
print(res.__next__()) # 迭代取值 for 循环的本质
一旦__next__取不到值 会直接报错
4.注意事项
可迭代对象调用__iter__会成为迭代器对象 迭代器对象如果还调用__iter__不会有任何变化 还是迭代器对象本身
for循环的本质
for 变量名 in 可迭代对象:
循环体代码
"""
1.先将in后的数据调用__iter__转变成迭代器对象
2.依次让迭代器对象调用__next__取值
3.一旦__next__取不到值报错 for循环会自动捕获并处理
"""
异常处理
异常捕获处理
1.异常
异常就是代码运行报错 行业术语叫bug
代码运行中一旦遇到异常会直接结束整个程序的运行 我们在编写代码的过程中要尽可能避免
2.异常分类
语法错误
不允许出现 一旦出现立刻改正 否则提桶跑路
逻辑错误
允许出现的 因为它 一眼发现不了 代码运行之才可能会出现
3.异常结构
错误位置
错误类型
错误详情

 浙公网安备 33010602011771号
浙公网安备 33010602011771号