01_58同城页面字体加密逆向分析
逆向介绍
- 通过对
https://sz.58.com/searchjob/?pts=1641212057373页面进行爬取,发现网站部分敏感信息存在字体加密,字体加密情况如下:
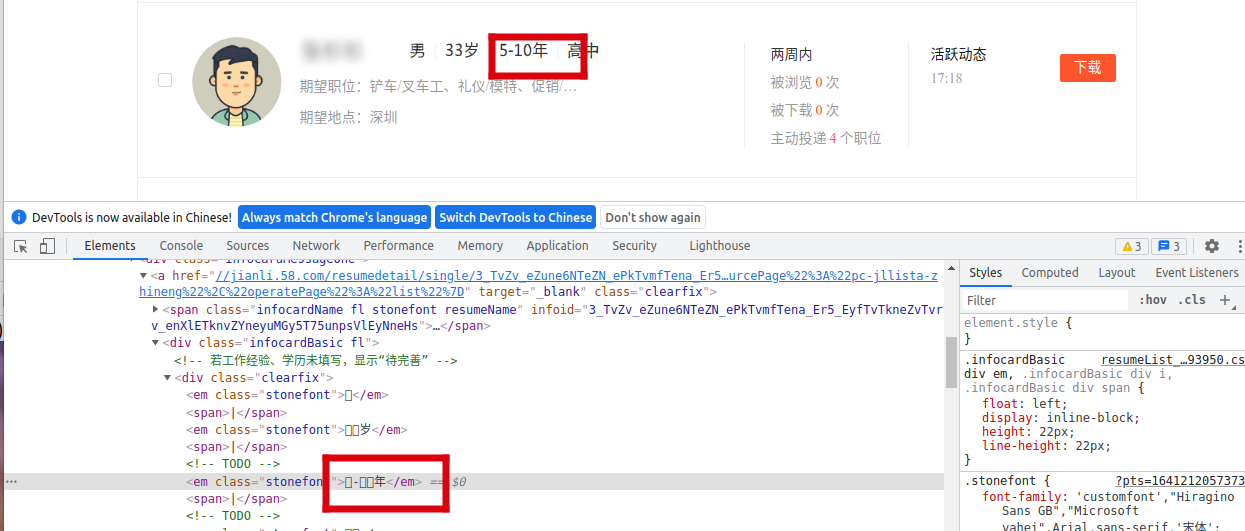
1.获取网站源代码进行分析
通过分析发现字体库存在网页源代码当中:

进过对网站多次刷新发现每一次网站的这一段代码都会发生变化,且加密方式是base64,下面通过代码获取网站的这一字符串并进行解密:
import requests
import base64
url = 'https://sz.58.com/searchjob/?pts=1641212057373'
headers = {
"cookie": 'PPU="UID=78153680881173&UN=h68s69wp0&TT=6bccb10df57fb938500a589cd90c4329&PBODY=bwiLti_c_Pqb1432wbdadP2lTlPGZptJZdfMfhdQdDbNIMpgAgUwNGF32__rz_VU2eKPhZES4jR2QO7b2fFmjbmX4My3ckD2YS5AseLV4b4TVYSiKX2kcM-WZEEREbhrW_jDTGHwck8LqMXSraqSYCLxnymtDuCt3ricY8oQj5o&VER=1&CUID=orzl7ykvSExgUPdZh72bQg"',
"user-agent": 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
html = response.content.decode(response.encoding)
bs64 = re.findall('base64,(.*?)\).*format\("woff"\)', html, re.S)
if len(bs64) >= 1:
BS = base64.b64decode(bs64[0].strip())
with open('58.woff', mode='wb') as fp:
fp.write(BS)
通过代码对加密的字符串进行解密后发现是一个二进制的woff文件数据,保存woff文件后通过http://font.qqe2.com/在线字体编辑器打开进行查看,发现就是加密的字体信息,打开后的文件如下:
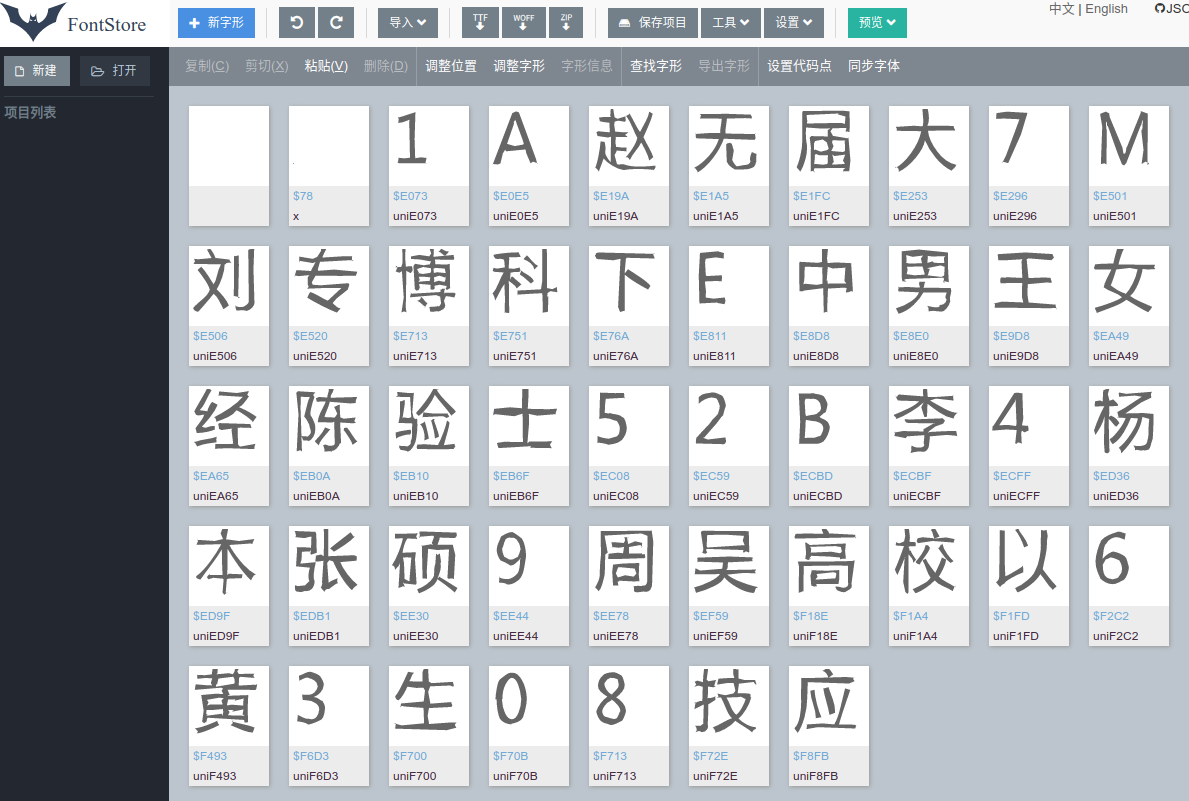
2. 找到字体文件开始分析
由于woff文件是二进制文件,并不能直接进行分析,为了方便分析需要借助fontTools模块中的TTFont将woff转化成XML进行分析,转化代码如下:
from fontTools.ttLib import TTFont
TTFont('58.woff').saveXML('58.xml')
转化后文件如下:
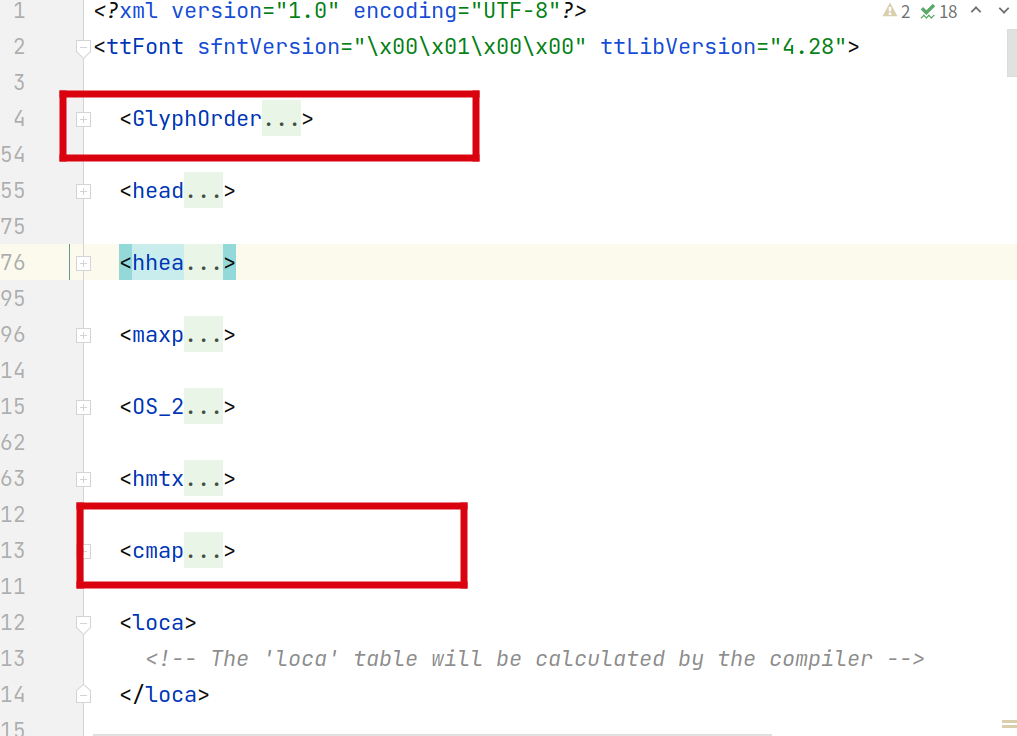
需要结合woff文件及XML文件中圈出的部分进行分析,经过多次分析,未分析出规律,转换思路,通过对字体文件转化成图片,调用OCR进行识别进行破解。woff文件转化成图片代码如下:
from fontTools.ttLib import TTFont
from fontTools.pens.basePen import BasePen
from reportlab.graphics.shapes import Path
from reportlab.lib import colors
from reportlab.graphics import renderPM
from reportlab.graphics.shapes import Group, Drawing
class ReportLabPen(BasePen):
def __init__(self, glyphSet, path=None):
BasePen.__init__(self, glyphSet)
if path is None:
path = Path()
self.path = path
def _moveTo(self, p):
(x, y) = p
self.path.moveTo(x, y)
def _lineTo(self, p):
(x, y) = p
self.path.lineTo(x, y)
def _curveToOne(self, p1, p2, p3):
(x1, y1) = p1
(x2, y2) = p2
(x3, y3) = p3
self.path.curveTo(x1, y1, x2, y2, x3, y3)
def _closePath(self):
self.path.closePath()
def font_to_image(font_file_name, img_files_dir="temp", fmt="png"):
"""
将woff文件或者ttf文件处理成图片
:param font_file_name: 要处理的文件名 或 BytesIO对象
:param img_files_dir: 保存的图片的文件路径
:param fmt: 保存的文件格式
:return: List
"""
image_files = []
if not os.path.exists(img_files_dir):
os.makedirs(img_files_dir)
else:
shutil.rmtree(img_files_dir)
os.makedirs(img_files_dir)
font = TTFont(font_file_name)
gs = font.getGlyphSet()
# 获取到GlyphOrder下的所有的name属性
glyph_names = font.getGlyphNames()
for glyph_name in glyph_names:
if glyph_name[0] == '.': # 跳过'.notdef', '.null'
continue
g = gs[glyph_name]
pen = ReportLabPen(gs, Path(fillColor=colors.black, strokeWidth=1))
g.draw(pen)
w, h = g.width, g.height or g.width * 3
g = Group(pen.path)
g.translate(0, 200)
d = Drawing(w, h)
d.add(g)
image_file = os.path.join(img_files_dir, "{}.{}".format(glyph_name, fmt))
renderPM.drawToFile(d, image_file, fmt)
image_files.append(image_file)
return image_files
项目完整代码如下:
import os
import re
import base64
import shutil
from io import BytesIO
import requests
from fontTools.ttLib import TTFont
from fontTools.pens.basePen import BasePen
from reportlab.graphics.shapes import Path
from reportlab.lib import colors
from reportlab.graphics import renderPM
from reportlab.graphics.shapes import Group, Drawing
access_token = "此处为百度智能云的TOKEN"
IMG_FILES_PATH = 'temp'
class ReportLabPen(BasePen):
def __init__(self, glyphSet, path=None):
BasePen.__init__(self, glyphSet)
if path is None:
path = Path()
self.path = path
def _moveTo(self, p):
(x, y) = p
self.path.moveTo(x, y)
def _lineTo(self, p):
(x, y) = p
self.path.lineTo(x, y)
def _curveToOne(self, p1, p2, p3):
(x1, y1) = p1
(x2, y2) = p2
(x3, y3) = p3
self.path.curveTo(x1, y1, x2, y2, x3, y3)
def _closePath(self):
self.path.closePath()
def font_to_image(font_file_name, img_files_dir="temp", fmt="png"):
"""
将woff文件或者ttf文件处理成图片
:param font_file_name: 要处理的文件名 或 BytesIO对象
:param img_files_dir: 保存的图片的文件路径
:param fmt: 保存的文件格式
:return: List
"""
image_files = []
if not os.path.exists(img_files_dir):
os.makedirs(img_files_dir)
else:
shutil.rmtree(img_files_dir)
os.makedirs(img_files_dir)
font = TTFont(font_file_name)
gs = font.getGlyphSet()
# 获取到GlyphOrder下的所有的name属性
glyph_names = font.getGlyphNames()
for glyph_name in glyph_names:
if glyph_name[0] == '.': # 跳过'.notdef', '.null'
continue
g = gs[glyph_name]
pen = ReportLabPen(gs, Path(fillColor=colors.black, strokeWidth=1))
g.draw(pen)
w, h = g.width, g.height or g.width * 2
g = Group(pen.path)
g.translate(0, 200)
d = Drawing(w, h)
d.add(g)
image_file = os.path.join(img_files_dir, "{}.{}".format(glyph_name, fmt))
renderPM.drawToFile(d, image_file, fmt)
image_files.append(image_file)
return image_files
def baidu_ocr(file_path):
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/handwriting"
with open(file_path, "rb") as f:
image = base64.b64encode(f.read())
body = {
"image": image,
}
headers = {"Content-Type": "application/x-www-form-urlencoded"}
request_url = f"{request_url}?access_token={access_token}"
response = requests.post(request_url, headers=headers, data=body)
content = response.content.decode("UTF-8")
try:
content = eval(content).get('words_result', [])
if len(content) == 0:
content = [{}]
return content[0].get('words', '')
except Exception:
return ''
def main():
url = 'https://sz.58.com/searchjob/?pts=1641212057373'
headers = {
"cookie": 'PPU="UID=78153680881173&UN=h68s69wp0&TT=6bccb10df57fb938500a589cd90c4329&PBODY=bwiLti_c_Pqb1432wbdadP2lTlPGZptJZdfMfhdQdDbNIMpgAgUwNGF32__rz_VU2eKPhZES4jR2QO7b2fFmjbmX4My3ckD2YS5AseLV4b4TVYSiKX2kcM-WZEEREbhrW_jDTGHwck8LqMXSraqSYCLxnymtDuCt3ricY8oQj5o&VER=1&CUID=orzl7ykvSExgUPdZh72bQg"',
"user-agent": 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
html = response.content.decode(response.encoding)
bs64 = re.findall('base64,(.*?)\).*format\("woff"\)', html, re.S)
if len(bs64) >= 1:
BS = base64.b64decode(bs64[0].strip())
# 保存字体库文件
with open('a.woff', mode='wb') as fp:
fp.write(BS)
# # 通过fondTools.ttLib中的TTfond将woff文件转换成xml文件
# font = TTFont('a.woff')
# font.saveXML('woff2.xml')
# 通过BytesIO免保存文件
img_files = font_to_image(BytesIO(BS), img_files_dir=IMG_FILES_PATH)
else:
img_files = []
map_dic = {}
for img_file in img_files:
# 调用标度ocr文件识别
res = baidu_ocr(img_file)
img_file_name = os.path.basename(img_file).split('.')[0].strip(' ')
woff_str = (img_file_name.replace('uni', '&#x') + ';').lower()
# 此处判断目的是为了解决识别不出来替换成空的情况,识别不出来就不识别。
if res == "":
res = woff_str
map_dic[img_file_name] = res
html = html.replace(woff_str, res)
print(woff_str, res, '替换完成')
print(html)
print(map_dic)
if __name__ == '__main__':
main()
总结
在进行字体加加密逆向的时候,比较通用的方法是通过分析多个XML文件,总结规律,得出一个通用的映射关系,然后通过这一个映射关系进行替换,如果对于无规律可寻字体的加密,其最简单的就是通过OCR进行识别然后进行转化(调用OCR是一定要调用手写的接口,结果测试45个字,调用手写ORC识别接口只有1~2个字无法识别,而调用普通OCR及高精度OCR接口识别不出来,对于有能力的可以自己训练OCR)
逆向的方法不唯一,不要从一条路上死磕,多换换角度思考学好逆向其实很简单。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号