pyspark
spark
用于大规模数据处理的统一(适用面广)分析引擎(数据处理)。
RDD:弹性分布式数据集。
rdd是一种分布式内存抽象,能够在大规模集群中做内存运算,并且有一定的容错方式。
spark 特点:
对任意类型的数据进行自定义计算。
spark 可以计算: 结构化,半结构化,非结构化等各种类型的数据结构,同时也支持使用python ,java scala,R以及sql语言去开发应用程序计算数据。
spark和 hadoop 区别
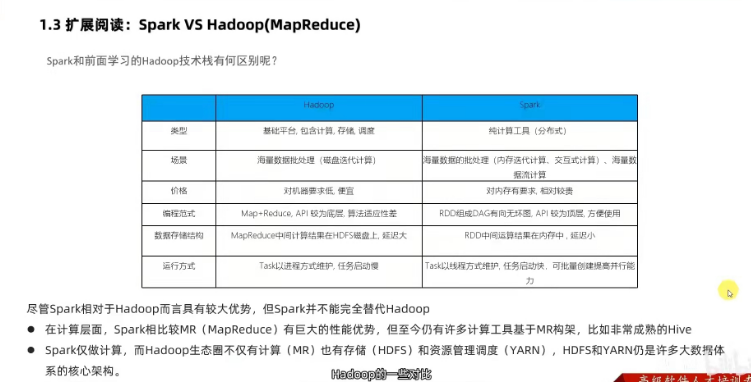
spark做海量数据的计算,可以进行离线批处理,以及实时流处理。
spark四个特性
1)速度快,
spark支持内存计算,并且通过DAG(有向无环图)执行引擎支持无环数据流,其在内存中的运算速度要比mapreduce快100倍,在硬盘中要快10倍。
spark 与mapreduce处理数据对比:
其一,spark处理数据时,可以将中间处理结果数据存储到内存中。
其二,spark提供了非常丰富的算子(Api),可以做到复杂任务在一个spark程序中完成。
2)易于使用
3)通用性强
spark提供了包括dpark sql, dpark streaming, mlib 以及graphx在内的多个工具库。
4)运行方式
包括hadoop和 mesos上,也支持standalone的独立运行方式,也可以运行在云kubernetes上。
spark 运行模式
1)本地模式(单机) local
以一个独立的进程,通过其内部的多个线程来模拟整个spark的运行环境。
2)standalone模式(集群)
各个角色以独立进程的形式存在,组成spark集群环境。
3)kubernetes模式(容器集群),简称k8s集群
各个角色运行在kubernetes的容器内部,组成spark集群环境。
4)云服务模式(运行在云平台上)
后三个用在生产环境。
spark的角色
资源层面:
master角色:集群资源管理
worker角色:单机资源管理
任务运行层面:
driver:单个任务的管理
executor角色:单个任务的计算(woker 干活的)
standalone提交spark应用
命令:bin/spark-submit --master spark://server7077;
4040, 8080, 18080 端口分别是什么?
4040: 是单个程序运行的时候绑定的端口,可供查看本任务运行情况
8080:是standalone下,master角色的端口。
18080:默认是历史服务器的端口。
job, state, task 的关系?
一个spark程序会被分成多个子任务(job)运行,每一个job会分成多个state(阶段)来运行,每一个state内会分出来多个task(线程)来执行具体任务。
spark on yarn
是两种运行模式,一种是cluster模式,一种是client模式,两者的区别在于driver运行的位置。
两种部署模式的区别?

clustet模式: driver运行在yarn容器内部,和applicationmaster在同一个容器内。(生产环境中使用该模式)
1)driver程序在yarn集群中,和集群的通信成本低
2)driver输出结果不能再客户端显示
3)该模式下driver运行applicationmaster这个节点上,由yarn管理,如果出现问题,yarn会重启applicationmaster(driver)
client模式: driver运行在客户端进程中,比如driver运行在spark-submit程序的进程中。(学习测试时使用,生产不推荐,要用也可以,性能,稳定性略低)
1)driver运行在client端,和集群的通信成本高
2)driver输出结果能再客户端显示
为什么spark用yarn
提高资源利用率,在已有的yarn场景下,让spark收到yarn的调度可以更好的管控资源提高利用率并方便管理。
pyspark
是应用程序,客户端程序,提供交互式的Python客户端用于写spark api.
pandas用于:小规模数据集的处理
spark用于:大规模数据集的处理。
spark和pyspark的区别
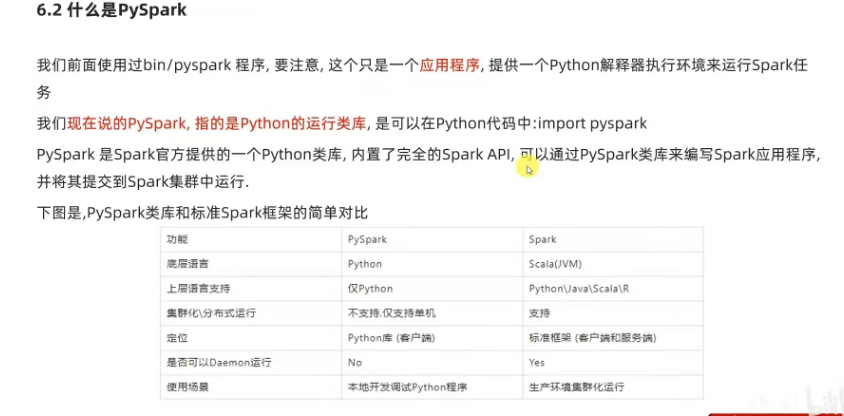
pyspark 用法代码
获取sparkcontext对象,作为执行环境入口
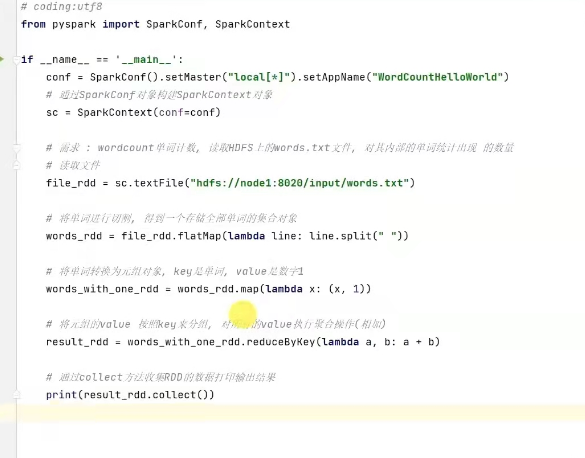
pyspark 执行原理:
driver端由python翻译成jvm,driver端的jvm和executor端的jvm互相通信,通过中转站底层由Pythonexecutor在运行。
rdd
为什么需要rdd:
在分布式框架中,需要有一个统一的数据抽象对象,来实现分布式计算所需功能。
rdd五大特性
-
有分区
rdd分区是rdd数据存储的最小单位, 一份rdd的数据本质上是分割成了多个分区
例子:sc.parallelize([1,2,3,4,5,6,7,8,9],3).glom().collect()
结果是 [[1,2,3],[4,5,6],[7,8,9]]
2). rdd的方法会作用到其所有的分区上
例子
sc.parallelize([1,2,3,4,5,6,7,8,9],3).map(lambda x: x*10).glom().collect()
结果是 [[10,20,30],[40,50,60],[70,80,90]]
3). rdd有依赖关系
4). k-v 型的rdd可以有分区器
默认的分区器:hash分区规则,可以手动设置一个分区器(rdd.partitionby的方法来设置 )。
这个特性是 可能得,不是所有的rdd都是k-v型。
k-v rdd:rdd 存储的是二元元祖。
二元元祖: 只有两个元素的元祖,比如("hadoop",6)
5) rdd分区规划,尽量靠近数据所在的服务器。
因为这样可以走本地读取,避免网络读取。
wordcount结合rdd特性进行执行分析
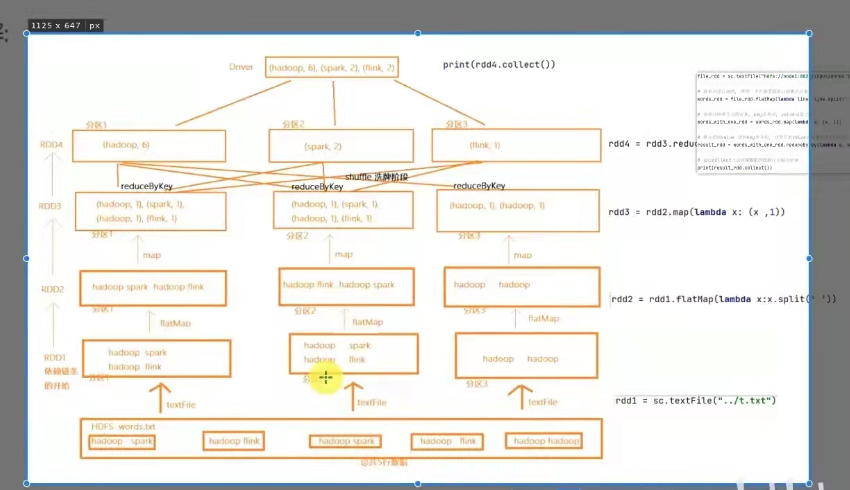
rdd的创建
2种方式:
1.通过并行化集合创建(本地对象 转 分布式rdd);
使用方法:rdd=sparkcontext.parallerize(集合对象,分区数)

2.读取外部数据源(读取文件)
使用方法: sparkcontext.textfile( 文件路径,最小分区数量)
例子
from pyspark import SparkConf, SparkContext
if __name__ == '__main__:
#构建sparkcontext对象
conf = SparkConf().setAppName("test").setMaster(" ocal[*]")
sc = SparkContext(conf=conf)
#通过textFileAPI 读取数据
#读取本地文件数据
file_rdd1 = sc.textFile("../data/input/words.txt")
print("默认读取分区数:",file_rdd1.getNumPartitions())
print("file_rdd1 内容;",file_rdd1.collect())
#最小分区数参数的测试
file_rdd2 = sc.textFile("../data/input/words.txt", 3)
#最小分区数是参考值,spark有自己的判断,你给的太大spark不会理会
file_rdd3 = sc.textFile("../data/input/words.txt",100)
print("file_rdd2 分区数:",file_rdd2.getNumPartitions()
print("file_rdd3 分区数:", file_rdd3.getNumPartitions())
#读取HDFS文件数据测试
hdfs_rdd = sc.textFile("hdfs://node1:8020/input/words.txt")print("hdfs_rdd 内容:",hdfs_rdd.collect())
wholetextfiles
读取小文件比较多时,使用wholetextfiles(文件路径,分区数 )
因为文件的数据很小分区很多,导致shuffle的机率更高,所以尽量少分区读取数据。
from pyspark import SparkConf, SparkContext
if __name__ =='__main.__':
conf = SparkConf() .setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
#读取小文件文件夹
rdd= sc.wholeTextFiles("../data/input/tiny-files")
print(rdd.map(lambda x:x[1]).collect())
rdd算子
算子:分布式集合对象上的api.
方法/函数: 本地对象的api
2). rdd的算子分类
transformation: 转换算子
定义: rdd的算子,返回值仍是一个rdd.
特性: 这类算子是lazy懒加载的,如果没有action 算子,transformation是不工作的。
action:动作(行动)算子。
定义:返回值不是rdd.
transformation算子相当于在构建执行计划,action是一个指令让这个执行计划开始工作。
如果没有transformation,action算子之间的迭代关系,就是一个没有通电的流水线,只有action到来,这个数据处理的流水线才开始工作。
常用的transformation算子
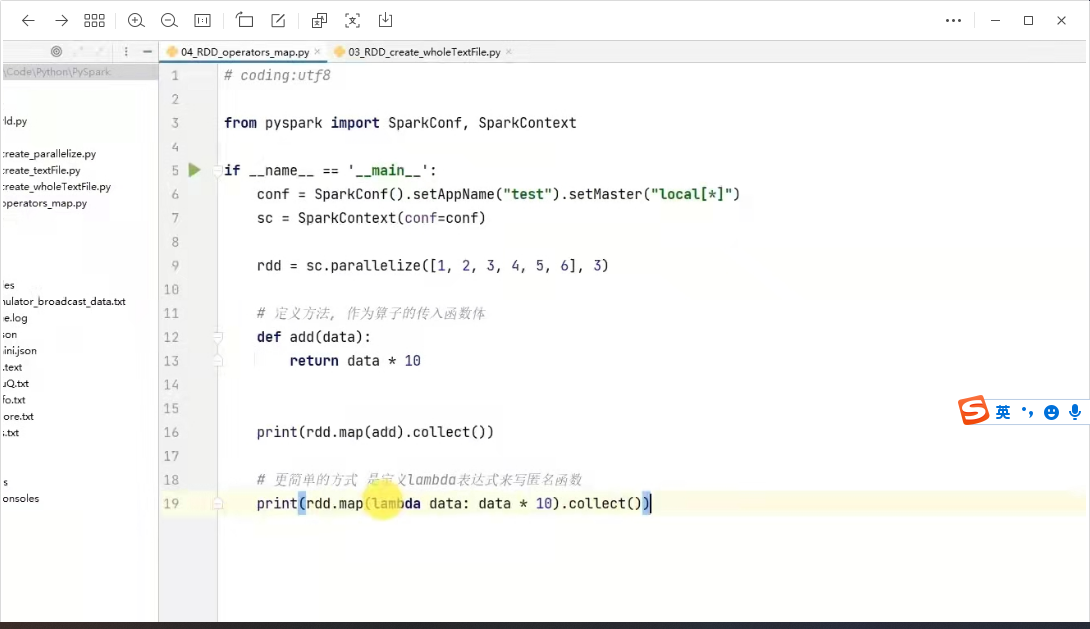
1) map算子
功能:map算子是将rdd的数据一条条处理( 处理的逻辑基于map算子中接收的处理函数 ),返回新的rdd。
语法: rdd.map( func)
例子:
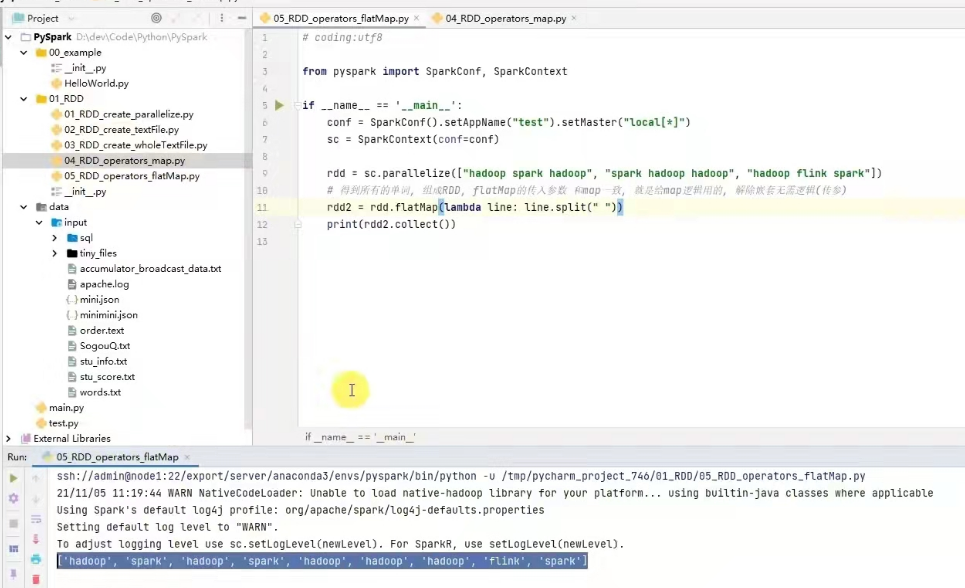
2) flatmap算子
功能:对rdd执行map操作,然后进行解除嵌套操作。(就是将多维数组转为一维数组)
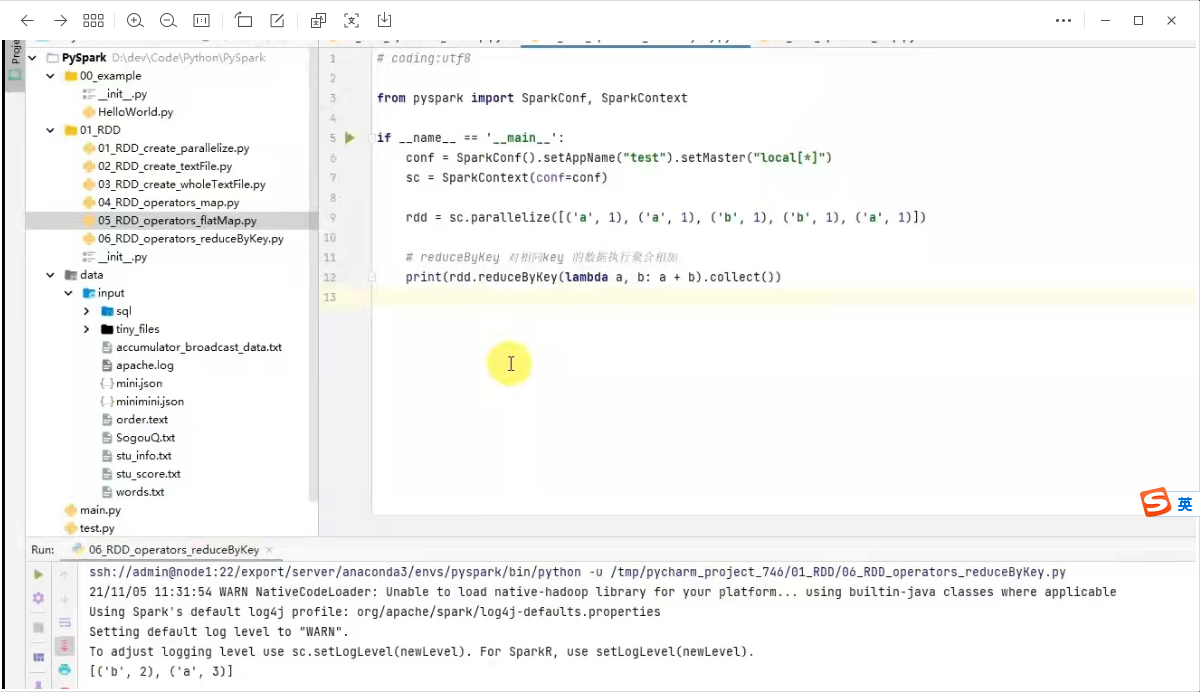
3) reduceBykey算子
功能:针对kv型的rdd,自动按照key分组,然后根据你提供的聚合逻辑,完成组内数据(value)的聚合操作。
语法: rdd.reduceByKey(func)
按照key分组,值累加
4) mapValues 算子
功能:针对二元元祖rdd,对其内部的二元元祖的value执行map操作。
语法:rdd.mapValues(func)
代码:
sc.parallelize([("a",1), ("a",5), ("a",8), ("b",3)] )
#rdd.map(lambda x: x[0] ,x[1] *10 ).collect()
rdd.mapValues(lambda value: value *10 ).collect()
结果是 [("a",10), ("a",50), ("a",80), ("b",30)]
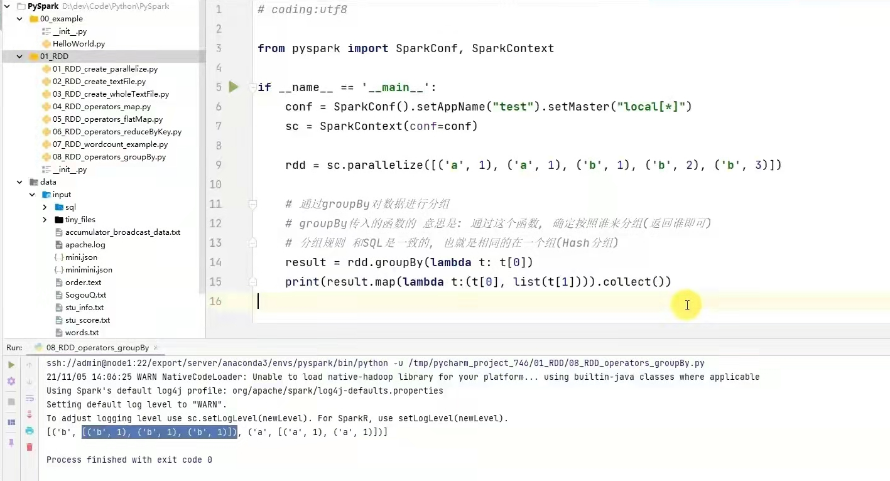
5) groupBy算子
功能:将rdd的数据进行分组
语法:rdd.groupBy(func)
6)filter算子
功能: 过滤想要的数据进行保留。
返回是true的数据被保留,false将被丢弃
例子:
rdd=sc.parallelize([1,2,3,4,5,6])
result=rdd.filter( lambda x: x %2==1)
print(result.collect())
结果是[1,3,5]
7) distinct算子
功能:对rdd数据进行去重,返回新的rdd。
语法:rdd.distincr(参数1) #参数1,去重分区数量,一般不用传
例子:
rdd = sc.parallelize( [1,1,1,2,3])
print(rdd.distinct().collect())
结果是 [1,2,3]
8)union算子
功能:两个rdd合并成一个rdd返回。
注:union 不会去重; rdd的类型不同也可以合并。
例子
rdd1 = sc.parallelize( [1,1,2])
rdd2 = sc.parallelize( ["a","b","a"])
rdd3 = rdd1.union(rdd2)
print(rdd3.collect())
结果是[1,1,2,"a","b","a"]
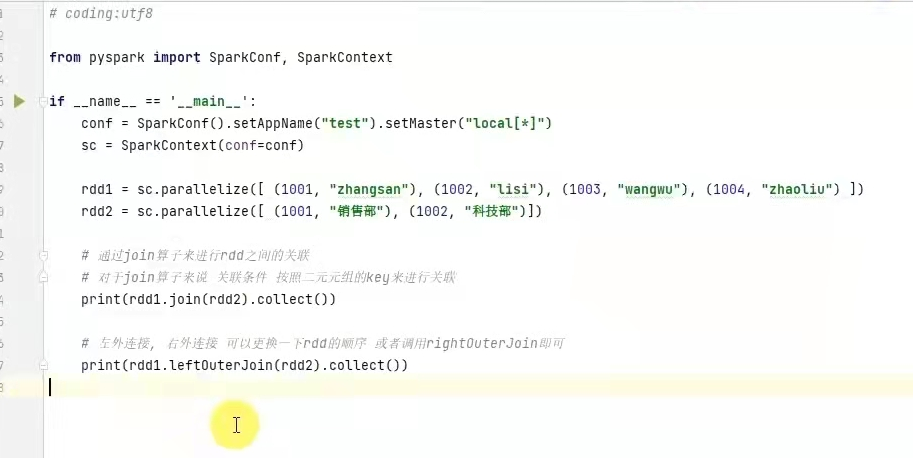
9) join算子
功能:对两个rdd执行join操作(可实现sql的内外连接 )
语法: rdd.join(other_rdd) #内连接
rdd.leftouterjoin(other_rdd) #左外
rdd.rightouterjoin(other_rdd) #右外
10) intersetion算子
功能:求两个rdd的交集,返回一个新的rdd。
例子
rdd1 = sc.parallelize( [("a",1),("b",1])
rdd2=sc.parallelize( [("a",1),("c",1] )
rdd3 = rdd1.intersetion(rdd2).collect()
结果是["a",1]
11) glom算子
功能:将rdd的数据,加上嵌套,这个嵌套按照分区进行。
方法: rdd.glom()
例子:
rdd = sc.parallelize([1,2,3,4,5], 2)
rdd.glom().collect()
结果是[[1,2,3],[4,5]]
12) groupbykey算子
功能:针对kv型rdd,自动按照key分组。
例子
rdd1 = sc.parallelize( [("a",1),("b",1],("a",1),("b",1), ("b",1) )
rdd2 = rdd1.groupbykey()
print( rdd2.map( lambda x : (x[0],list(x[1]) ) ).collect()
结果: [("a",[1,1]),("b",[1,1,1])]
13) sortBy算子
功能: 对rdd数据进行排序
语法:
rdd.sortby(func,ascending =true,numpartition=1)
ascending true升序,false降序
numpartition 用多少分区排序
例子
rdd = sc.parallelize( [("a",1),("b",9],("a",3),("b",2), ("b",6)],3 )
print(rdd.sortby(lambfa x:x[1],ascending=true,numpartition=3 )))#按值排序, x[0]是按key排序
结果 [("a",1),("b",2],("a",3),("b",6), ("b",9)]
14) sortByKey 算子
功能: 针对kv型rdd,按照key排序。
语法: sortbykey( ascending=true,numpartition=3, keyfunc=xxx)
keyfunc: 在排序前对key进行处理。
例子
rdd = sc.parallelize( [("a",1),("f",1],("C",1),("B",1), ("h",1)],3 )
print(rdd.sortbykey(keyfunc=lambda key:str(key).lower(),ascending=true,numpartition=1 ))).collect()
结果是[("a",1),("B",1],("C",1),("f",1), ("h",1)]
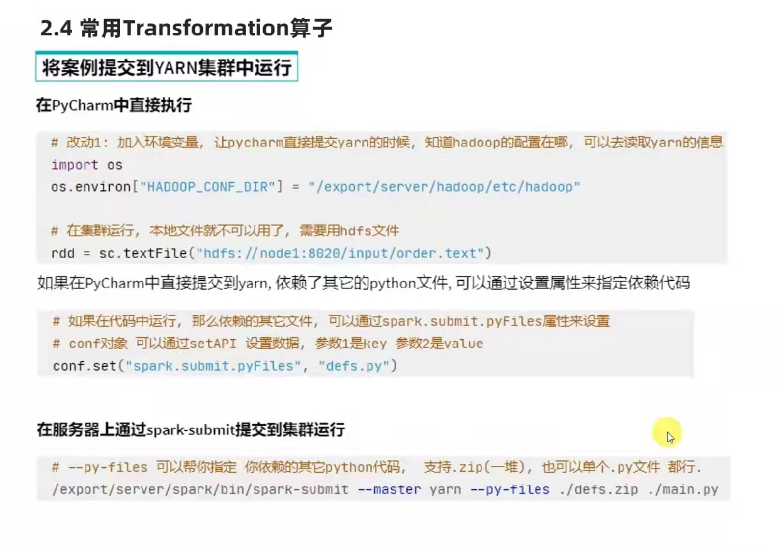
将案例提交到yarn执行
常用的action算子, (其结果不是rdd类型了)
1) countBykey算子
功能:统计key出现的次数,(一般适用于kv型的rdd)
例子
rdd = sc.textfile( ./t.txt)
rdd1 = rdd.flatmap(lambda x: x.split(" ")).map(lambda x :(x,1))
result = rdd1.countBykey()
print(result)
结果 ({"hello": 3, "foo" : 2})
2) collect()
功能:将rdd各个分区内的数据,统一收集到driver中,形成一个list对象。
3)reduce算子
功能: 对rdd数据集按照你传人的逻辑进行聚合。
例子
rdd = sc.parallelize([1,2,3,4])
print(rdd.reduce( lambda a,b : a+ b))
结果 10
4)fold算子
功能:和reduce一样进行聚合,聚合是带有初始值的,这个初始值聚合会作用在: 分区内聚合,分区间聚合。
比如[[1,2,3],[4,5,6],[7,8,9]]
数据分布在三个区,
分区1,123聚合时带上初始值10得到16,
分区2,456聚合时带上初始值10得到25,
分区1,789聚合时带上初始值10得到34
三个分区的结果做聚合带上初始值10,所以结果是10+16+25+34 =85。
例子
rdd = sc.parallelize([1,2,3,4,5,6,7,8,9])
print(rdd.fold(10, lambda a,b:a + b)
5) first()算子
功能:取出rdd的第一个元素。
例子
sc.parallelize([1,2,3,4,5,6,7,8,9]).first()
结果是 1
6) take算子
功能: 取rdd的前N个元素,返回列表
例子
sc.parallelize([1,2,3,4,5,6,7,8,9]).take(5)
结果是[1,2,3,4,5]
7)top算子
功能: 对rdd数据进行降序排序,取前N个。
例子
sc.parallelize([1,2,9,6,8,5]).top(3)
结果是[9,8,6]
8) count算子
功能: 计算rdd有多少条数据
例子
sc.parallelize([1,2,9,6,8,5]).count()
结果是6
9) takeSample算子
功能: 随机抽样rdd数据
用法:
takeSample( true or false,采样数,随机数种子 )
true or false: 是否允许取同一个位置的数据(不是值相同)
采样数: 抽样要几个
随机数种子:随意给一个数,如果传同一个数字,那么取出的结果是一样的,(一般不传,spark会自动给随机数种子)
例子
rdd = sc.parallelize([1,2,9,6,8,5])
print(rdd.takeSample(true,8))
结果是[1,2,5,6,8,2,6,8] 随机取出了8位数
10) takeOrdered 算子
功能:对rdd进行排序取前N个
用法:
rdd.takeOrdered(参数1,参数2)
参数1,要几个数据
参数2,对排序的数据进行更改(不会改原数据本身)
例子
rdd = sc.parallelize([1,2,9,6,8,5])
print(rdd.takeOrderd(3)) # [1,2,5]
print(rdd.takeOrderd(3,lambda x :-x)) #[9,8,6]
11) foreach 算子
功能:对rdd的每一个元素,执行你提供的逻辑操作,没有返回值(直接在executor里返回值,driver就不负责返回值了,减少driver的压力,效率可能会高一点)
用法:rdd.foreach(func)
例子:
rdd = sc.parallelize([1,2,9,6,8,5])
rdd.foreach(lambda x : print(x *10))
#可以把print写到lambda里。
12)saveAsTextFile算子
功能: 将rdd的数据写入到文本文件中,支持本地写出,HDFS等文件系统。
例子
rdd = sc.parallelize([1,2,9,6,8,5],3)
rdd.saveAsTextFile(hdfs://node1:8020/output )
注意: foreach和saveastextfile 算子是分区(executor)直接执行的,跳过driver,由分区所在的executor直接执行; 反之, 其余的action算子都会将结果发送到driver。所以这两个算子性能比较好,不会爆内存。
分区操作算子
1) mapPartitions算子
mappartition一次被传递是一整个分区的数据,作为一个迭代器(一次性list)对象传人过来。
例子
rdd = sc.parallelize([1,2,9,6,8,5],3)
def foo(iter):
result=list()
for i in iter:
result.append(i * 10)
return result
print(rdd.mappartitions( foo ).collect())
结果是[10,20,90,60,80,50]
2) foreachpartition算子
功能:和普通的foreach一致,一次处理的是一整个分区数据。 没有返回值
例子
rdd = sc.parallelize([1,2,9,6,8,5],3)
def foo(iter):
result=list()
for i in iter:
result.append(i * 10)
print(result)
rdd.mappartitions( foo )
#结果是
[10,20]
[90,60]
[80,50]
3) partitionBy 算子
功能: 对rdd进行自定义分区操作。
例子
rdd = sc.parallelize([ ("hadoop",1), ("hadoop",1), ("spark",1) , ("spark",1), ("filnk",1) ,("hello",1) ])
#使用partitionby自定义分区
def foo(k):
if "hadoop" == k or "hello" == k: return 0
if "spark" == k : return 1
return 2
rdd.partitionby(3,foo).glom().collect())
#结果,[[ ("hadoop",1), ("hadoop",1),("hello",1) ], [ ("spark",1), ("spark"",1)],[("filnk",1) ] ]
4) repartition算子
功能:对rdd的分区执行重新分区(仅数量)
用法: rdd.repartition(N)
传入N,决定新的分区数
注:如果改分区: 会影响并行计算(内存迭代的并行管道数量 ); 分区如果增加,极大可能导致 shuffle。
例子
rdd = sc.parallelize([1,2,9,6,8,5],3)
#repartition修改分区
print(rdd.repartition(1 ).getNumPartitions())
print(rdd.repartition(5 ).getNumPartitions())
#coalesce修改分区, 必须有shuffle=True,安全,他是安全阀,避免把5按成50,影响性能
print(rdd.coalesce(1 ).getNumPartitions())
print(rdd.coalesce(5,shuffle=True ).getNumPartitions())
结果是 1 5 1 5
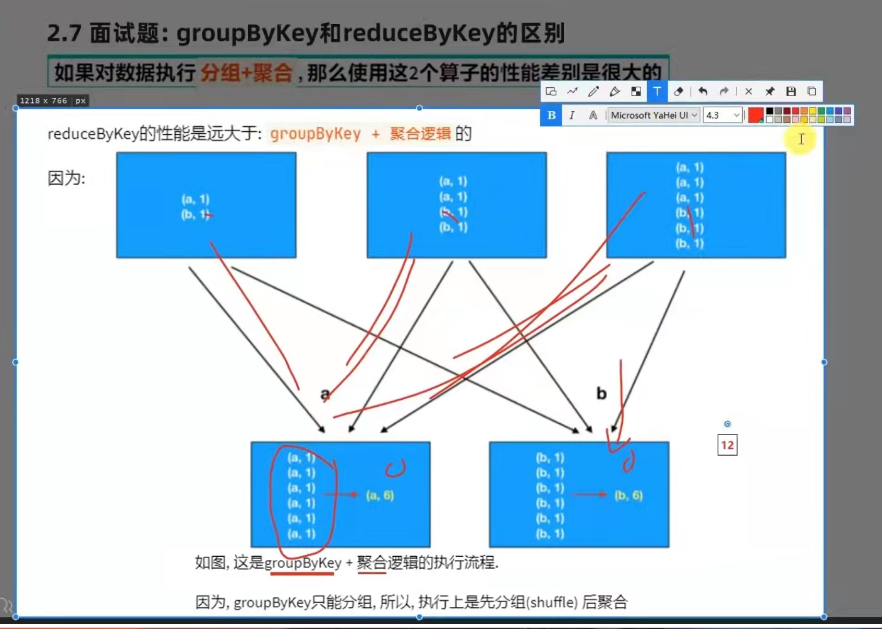
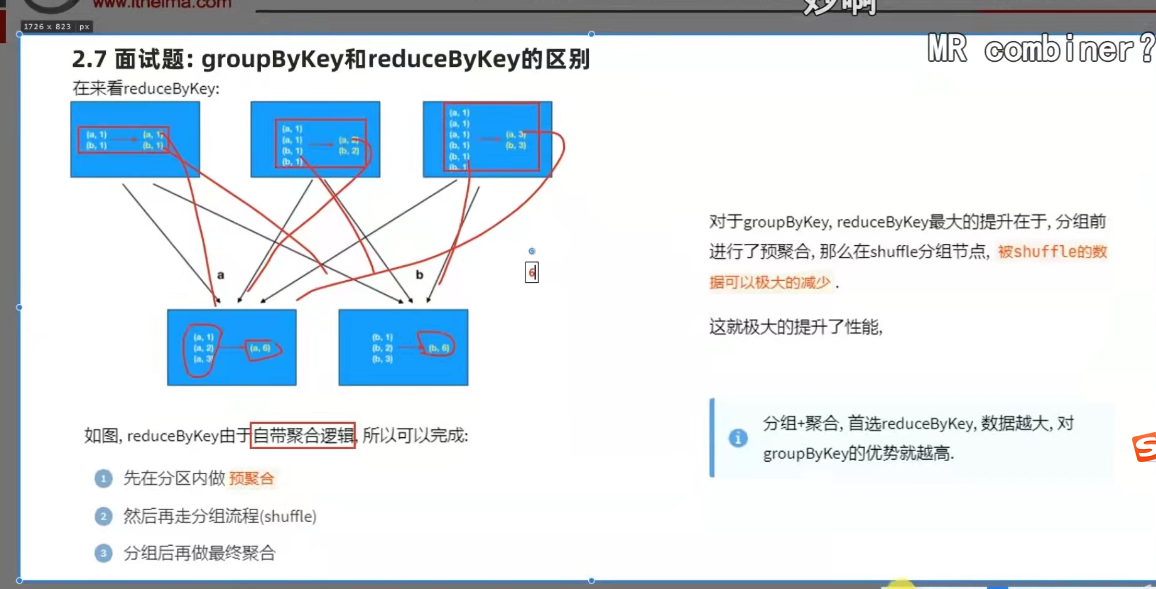
面试题: grouobykey 和 reducebykey 区别?
功能上: grouobykey 仅仅只有分组功能
reducebykey 除了有bykey的分组功能外还有reduce的聚合功能
性能上:reducebykey 的性能远大于grouobykey + 聚合逻辑的。
groupbykey 是先分组后聚合
reducebykey 是先预聚合,在分组,最后再聚和。这样的话网络io的开销是最小的。
问题2: transformation和action的区别?
转换算子的返回值100%是rdd,而action的返回值100%不是rdd,转换算子是懒加载,只有遇到action才会执行,action就是转换算子处理链条的开关。
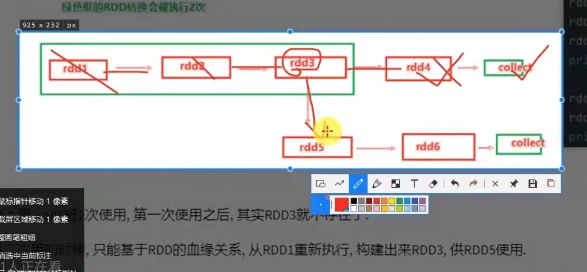
rdd 的数据是过程过程
rdd之间进行相互迭代计算(transformation的转换,当执行开启时,新rdd生成,旧的rdd消失。
特性: 最大化的利用资源,旧的rdd没有了就从内存中清理,给后续的计算腾出空间
rdd缓存
rdd缓存:可以通过调用api,将指定的rdd数据保留在内存或是硬盘上缓存的api。
用法:
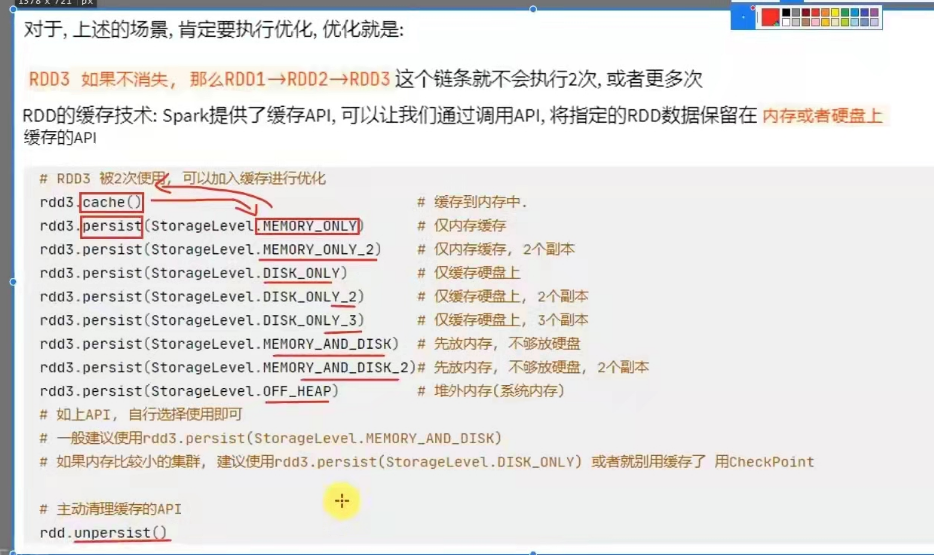
rdd不需要再走之前的链条,重新去计算了,而是直接保存在内存中,想用就去用。
缓存的目的:避免迭代的链条重新计算。
缓存是不安全的,缓存如果丢失?
就要重新计算重新缓存了,缓存必须保留 被缓存rdd的前置血缘关系。
例子
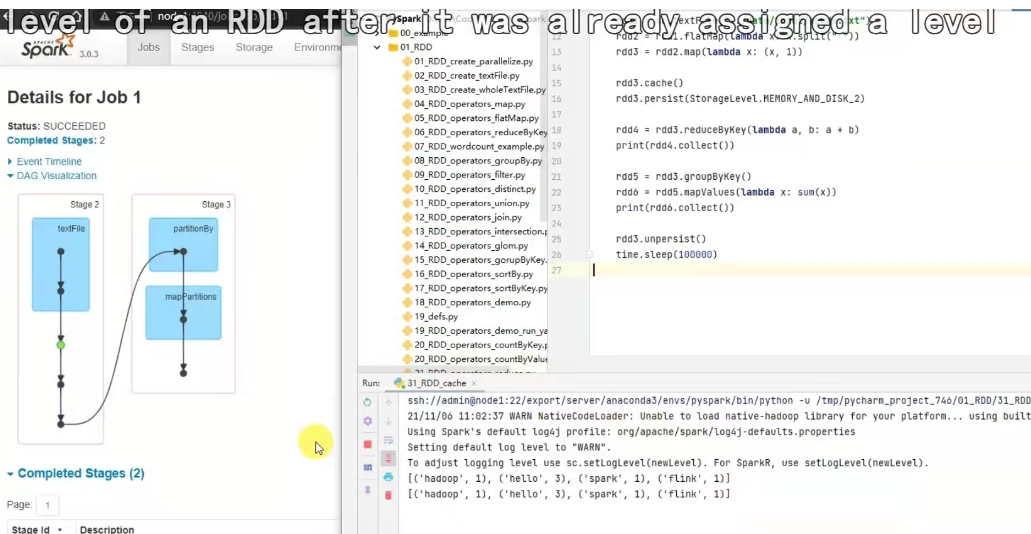
rdd checkPoint
也是将rdd的数据保存起来,但是仅支持硬盘存储。并且被设计认为是安全的(缓存不会丢失),不保留血缘关系(只能重新计算)。
checkPoint是如何保存数据的?
是被保存到hdfs上的,如图,checkpoint存储rdd数据,是集中收集各个分区数据进行存储,而缓存是分散存储。
看截图
缓存 和 checkpoint 对比:
1) checkpoint不管分区数量多少,风险是一样的 ; 缓存分区越多,风险越高。
2) checkpoint 支持写入HDFS ,缓存不行,HDFS是高可靠存储,checkpoint 被认为是安全的。
3) checkpoint 不支持内存,缓存可以,缓存如果写内存,性能比checkpoint要好一些。
4)checkpoint 被设计认为是安全的,所以不保留血缘关系,而缓存因为设计上认为不安全,所以保留。
用法:
sc.setCheckpointDir("hdfs://node1:8020/output/ckp")
#用的时候,直接调用checkpoint算子即可.
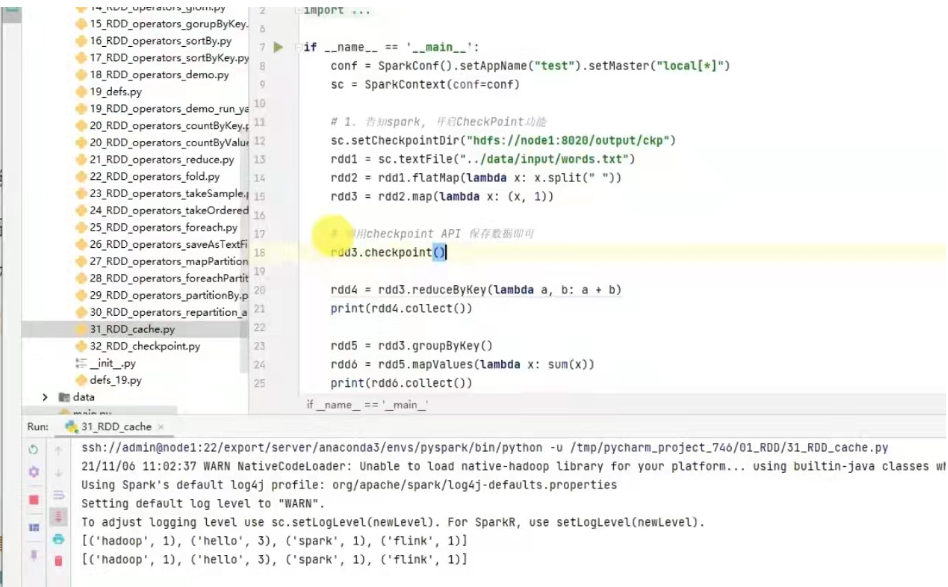
rdd.checkpoint()
例子
spark广播变量
用法:
#1.将本地list 标记成广播变量即可
broadcast = sc.broadcast(stu_info_list)
#2.使用广播变量,从broadcast对象中取出本地List对象即可
value = broadcast(value)
#也就是 先放进去broadcast内部,然后从broadcast内部在取出来用,中间传输的是broadcast这个对象了
#只要中间传输的是broadcast对象,spark就会留意,只会给每个Executor发一份了,而不是傻傻的哪个分区要都给
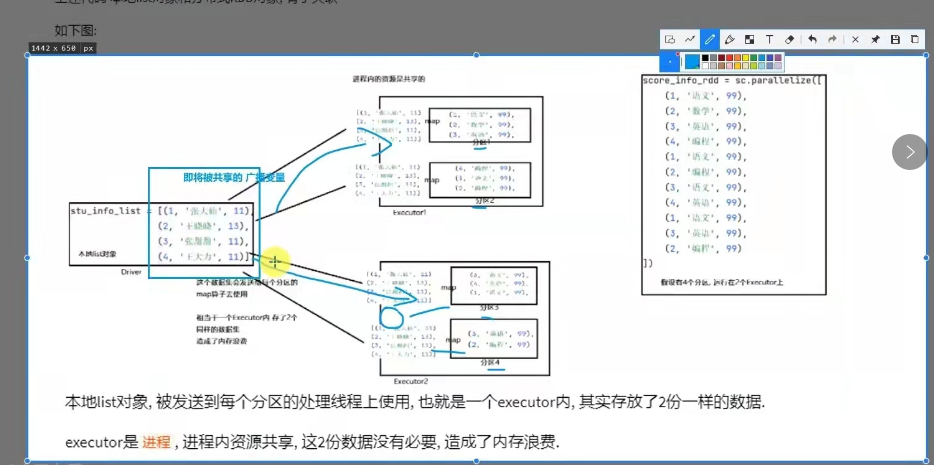
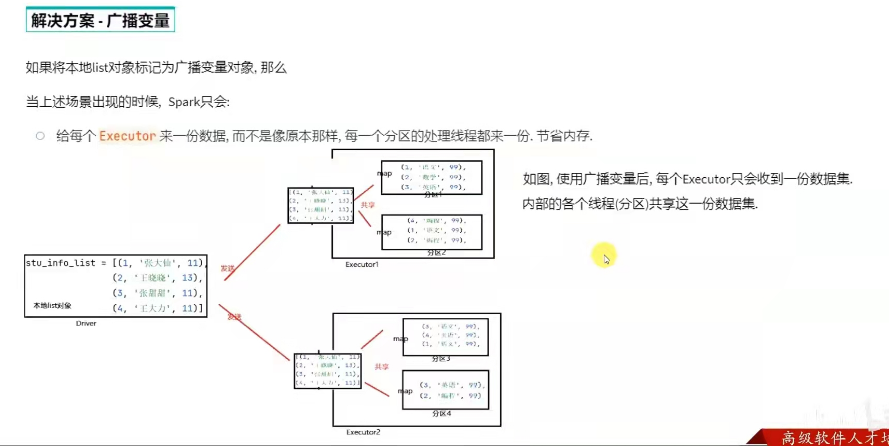
如果将本地list对象标记为广播变量对象,那么spark只会给每个executor来一份数据,而不是像原本数据那样,每一个分区的处理线程都来一份,节省内存。
问题1:为什么不把本地集合写成分布式rdd形式?
数据量不大的时候,使用本地集合是性能提升的一个点,避免了大量的shuffle。
本地集合对象 和 分布式集合对象(rdd)进行关联时,需要将本地集合对象封装成广播变量,可以节省内存:1.网络io的次数,2. executor的内存占用。
例子:
# codinq;utf8
if-_name_- ==__main_':
conf= SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
stu_info_list =[(1,'张大仙',11),
(2,'王晓晓’,13),
(3, '张甜甜”,11)
(4,'王大力',11)]
#1.将本地Python List对象标记为广播变量
broadcast = sc.broadcast(stu_info_list)
score_info_rdd = sc.parallelize([
(1,'语文',99),
(2,'数学',99),
(3,'英语’,99),
(4,'编程',99),
(1,'语文',99),
(2,'编程,99)
(3,'语文',99)
(4,'英语',99)04
(1,'语文',99)
(3,'英语',99)
(2,'编程',99)
])
def map_func(data):
id = data[0]
name = #u
#匹配本地List和分布式rdd中的学生ID 匹配成功后 即可获得当前学生的姓名#2.在使用到本地集会利象时方,从广播变量中取出来用即司
for stu_info in broadcast.value:
stu_id = stu_info[0]
if id == stuid:
name = stu_info[1]
return (name,data[1], data[2])
print(score_info_rdd.map( func).collect())
累加器
想要对map算子计算中的数据,进行技术累加,得到全部数据计算完后的累加结果。
代码:
sc.parallelize([1,2,9,6,8,5],2)
#spark提供的累加器变量,参数是初始值
acmlt = sc.accumulater(0)
def map_func(data )
global acmlt
acmlt += 1
print(acmlt) # 1 2 3 1 2 3
rdd.map(map_func).collect()
print( acmlt ) # 6
DAG
- DAG: 有向无环图,有方向没有形成闭环的一个执行流程图。
2)作用:
是协助DAG调度器构建task分配用以做任务管理。
job 和 action
1个action会产生一个DAG,如果代码中有3个action,就产生3个DAG,1个action产生的一个DAG会在程序运行中产生一个job。
所以1个action = 1个job = 1个 DAG.
1个代码运行起来,在spark中称之为 application。
层级关系:
1个application中可以有多个job,每一个job内含一个DAG, 同时每一个job都是由一个action产生。
2.DAG和 分区
带有分区的DAG
3.DAG的宽窄依赖和阶段划分。
窄依赖: 父rdd的一个分区,全部将数据发给子rdd的一个分区。
宽依赖: 父rdd的一个分区,将数据发给子rdd的多个分区。
宽依赖还有一个别名:shuffle。
4。阶段划分
对于spark来说,会根据DAG,按照宽依赖,划分不同的DAG阶段。
**划分依据: ** 从后向前,遇到宽依赖就划分出一个阶段,称之为stage。
在stage内部一定都是: 窄依赖。
内存迭代计算
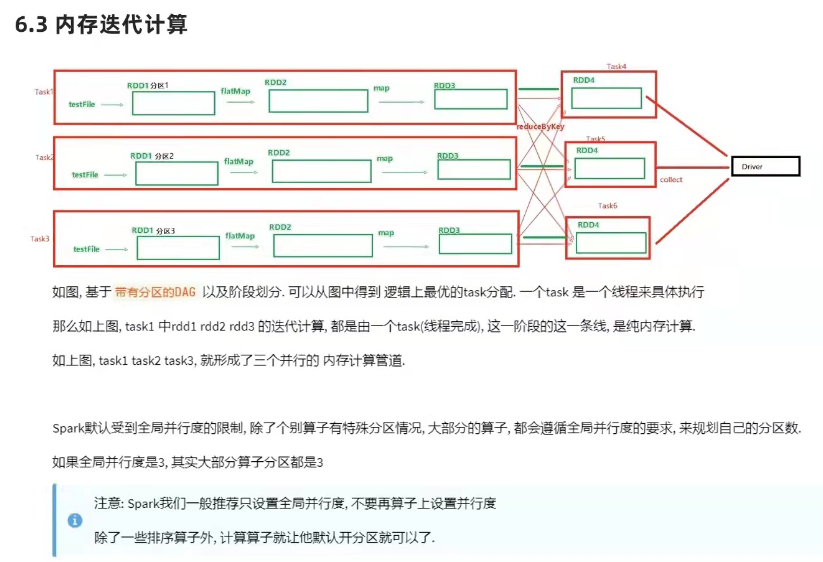
面试题1. spark是怎么做内存计算的? DAG的作用? stage阶段划分的作用?

面试题2. spark为什么比mapreduce快

spark并行度
先有并行度,才有分区规划。
spark的并行: 在同一时间内,有多少个task在同时运行。
并行度:并行能力的设置
比如设置并行度6,其实就是要6个task并行在跑。
在有了6个task并行的前提下,rdd的分区就被规划成6个分区了。
2) 如何设置并行度
优先级从高到低:
代码中
conf = SparkConf()
conf.set( "spark.default.parallelize" ,"100" )
客户端提交参数中
b8n/spark-submint --conf "spark.default.parallelize=100"
配置文件中
conf/spark-defaults.conf 中设置
spark.default.parallelize 100
默认(1,但是不会全部以1来跑,多数时候基于读取文件的分片数量 来作为默认并行度)
全局并行度配置的参数: spark.default.parallelize
注意:全局并行度是推荐设置,不要针对rdd该分区,可能会影响内存迭代管道的构建,或者会产生额外的shuffle。
spark任务调度
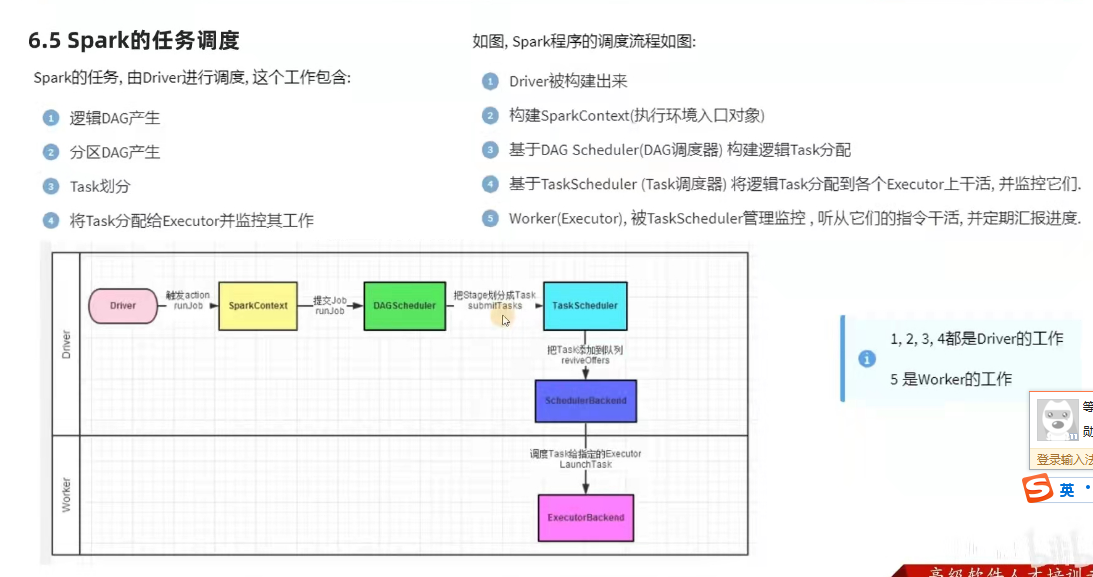
driver内的两个组件
1)DAG调度器
工作内容:将逻辑的DAG图进行处理,最终得到逻辑上的task划分。
2)task调度器
工作内容: 基于DAG scheduler 的产出,来规划这些逻辑的task,应该在哪些物理的executor上运行,以及监控管理他们的运行。
spark运行的层级关系

.sparkSQL
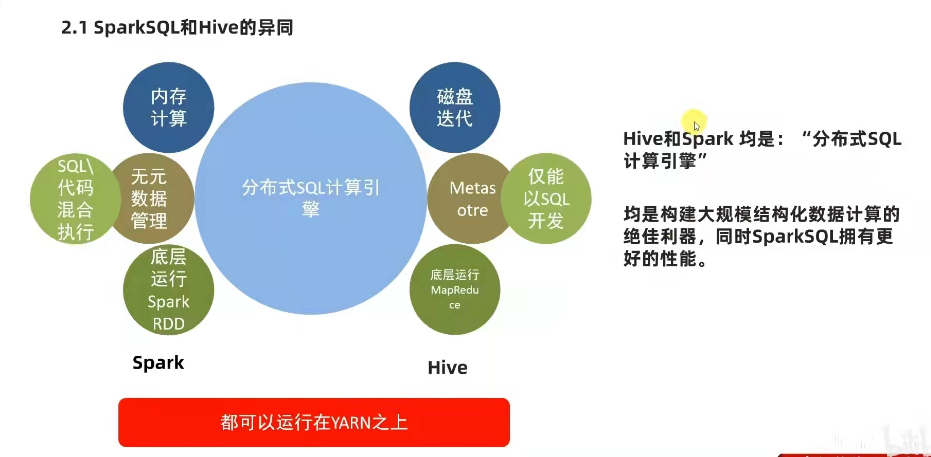
**分布式SQL计算引擎: ** sparksql ,hive, impala, presto。
sparksql是spark的一个模块,用于处理海量结构化数据。
sparksql支持SQL语言,性能强,可以自动优化,api简单,兼容hive等等。
sparksql处理业务数据: 离线开发,数仓搭建,科学计算,数据分析。
1)特点:
融合性:sql可以无缝集成在代码中,随时用SQL处理数据。
统一数据访问: 一套标注api可读写不同数据源。
hive兼容: 可以使用sparksql直接计算并生成hive表。
标准化链接: 支持标准化JDBC/ODBC链接,方便和各种数据库进行数据交互。
2). sparksql 和 hive的异同
3) .sparksql的数据抽象
有三种: SchemaRDD(废弃),dataFrame(python,java,scala ,R ), DataSet(scala ,java)
dataframe 和 dataset对比,基本相同,不同的是dataset 仅支持泛型特性,可以让Java,scala语言更好的利用到。

28.sparksession对象
在rdd阶段,程序的执行入口对象是:sparkcontext,在spark2.0之后,推出了sparksession 对象作为spark编码的统一入口对象。所以 后续的代码执行环境入口对象,统一变更为sparksession对象。
用法:
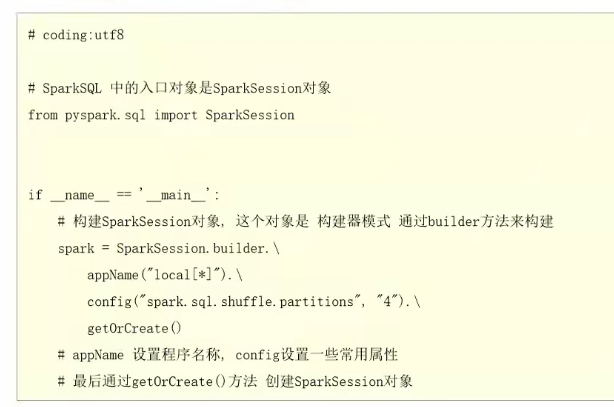
代码例子
datafram是按照二维表格的形式存储数据
rdd是存储对象本身(字符串,list,dict等形式).
datafram更适合SQL进行处理。
dataframe 组成结构:
structType对象描述整个dataframe 的表结构
Structfield 对象描述的是一个列的信息
row对象记录一行数据
Column 对象记录一列数据并包含列的信息
dataframe代码构建
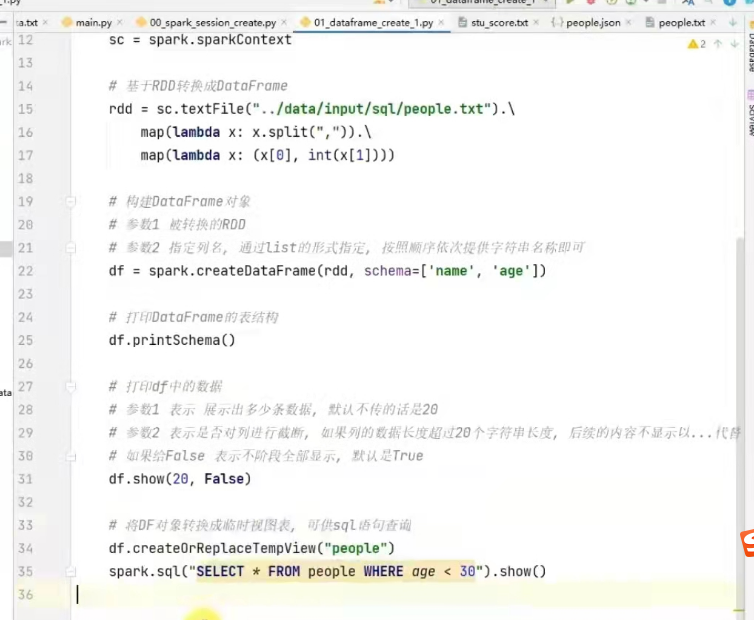
将rdd转成dataframe
1)spark.createDataFrame( rdd,schema=["name","age"] )
代码如下:
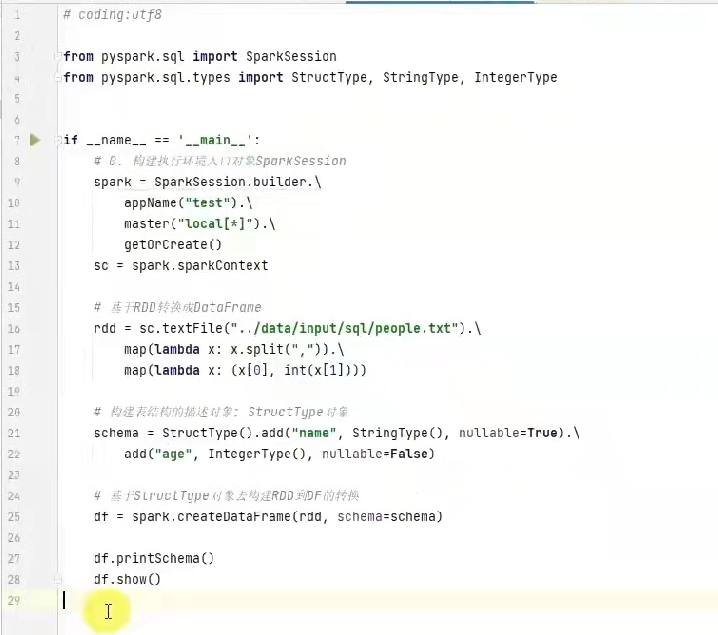
2) 通过structype对象来定义dataframe的表结构
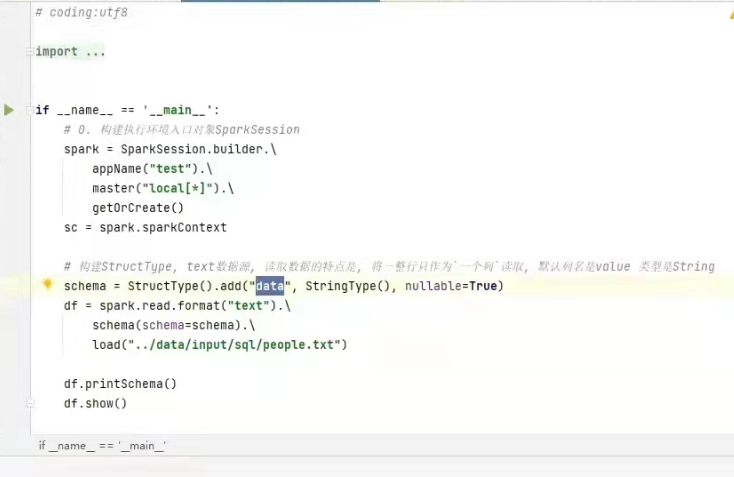
schema= StructType().add(列名,列类型,是否允许为空)
例子
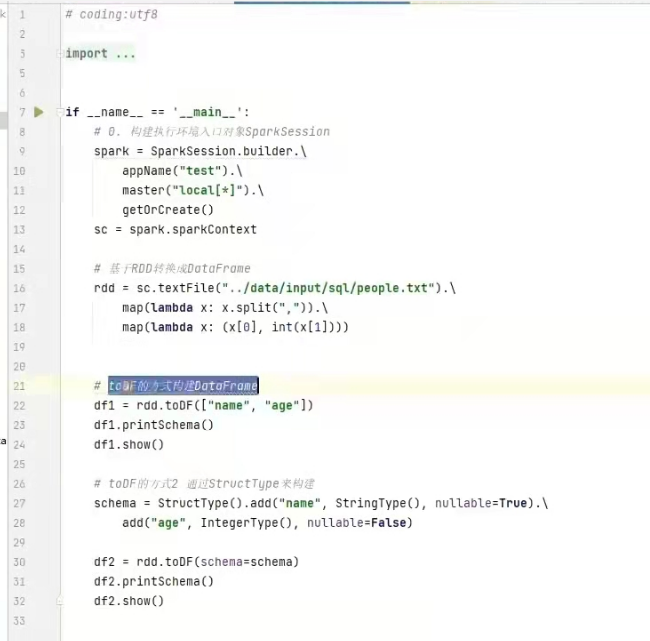
3) 使用rdd的toDF转换rdd。
例子
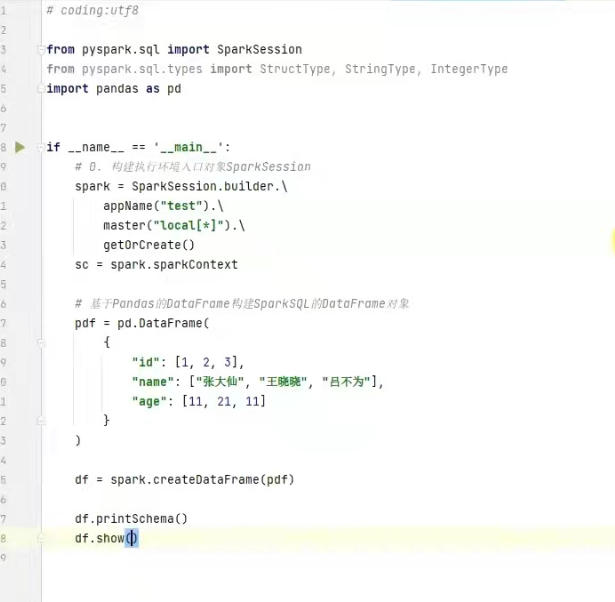
4)将pandas的dataframe转换成分布式的sparksql dataframe对象
例子
通过spark SQL的统一api进行数据读取构建dataframe。
1)读取TXT文件
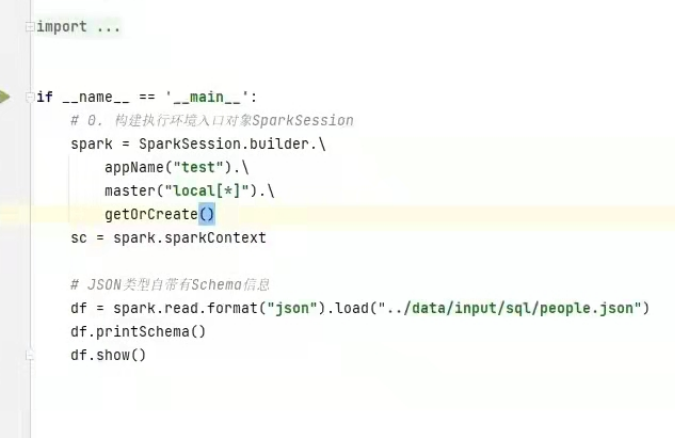
2)dataframe读取json数据
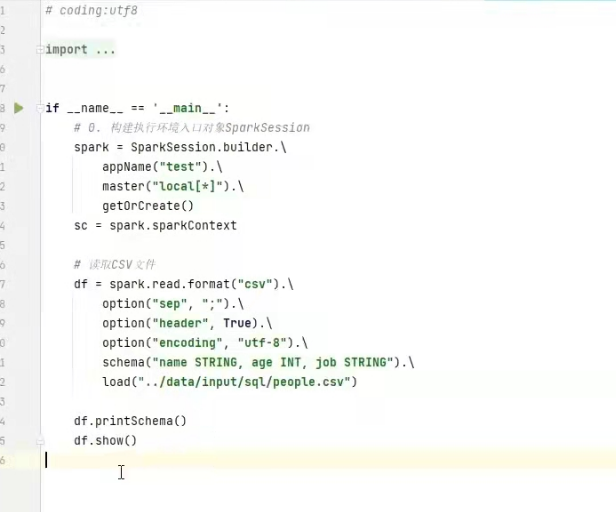
3)读取csv数据源
4)读取parquet数据源
parquet:是spark中常用的一种列式存储文件格式。
parquet跟普通文件对比:
parquet内置schema(列名/列类型,是否为空);
存储是以列作为存储格式;
存储是序列化存储在文件中(有压缩属性体积小)
示例:
df = spark.read.format( "parquet" ).load("./xx.parquet")
df.printschema()
df.show()
dataframe的两种分格
DSL风格:比如,df.where().limit()
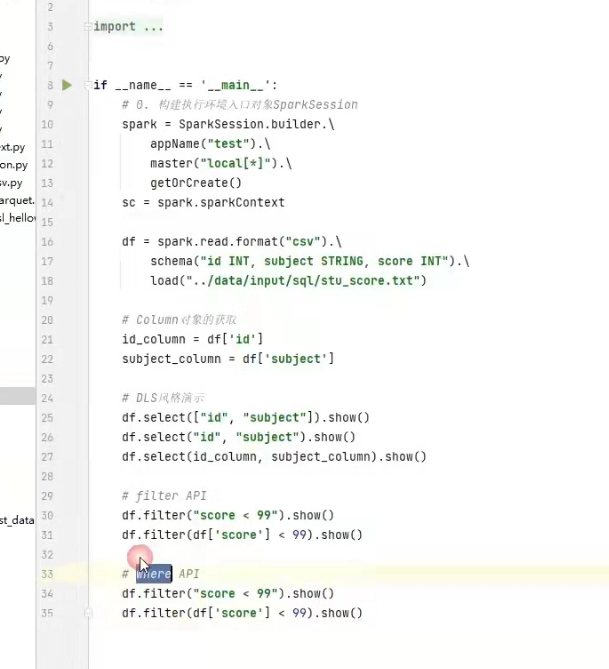
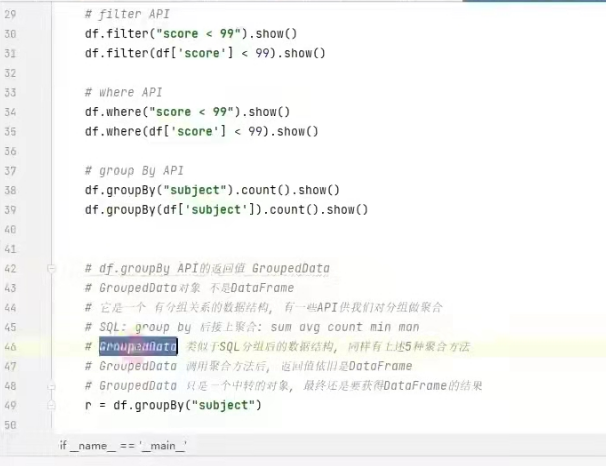
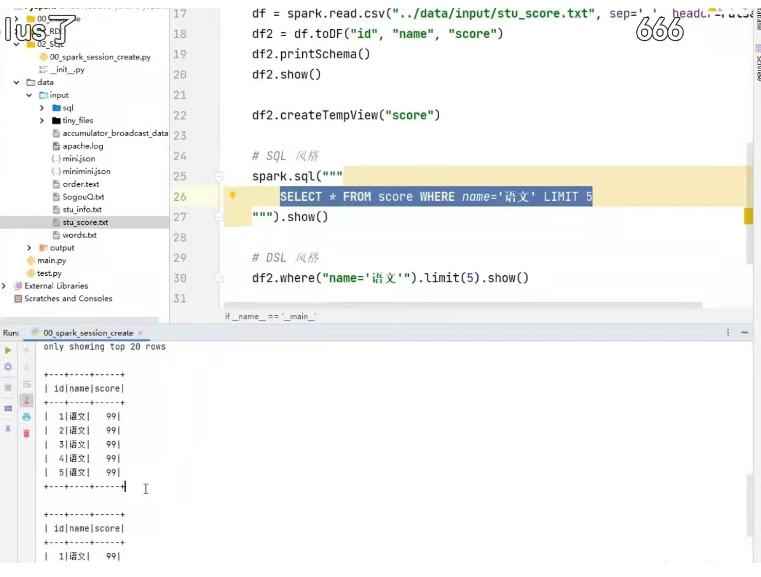
sql风格:比如,spark.sql(select * from xxx)
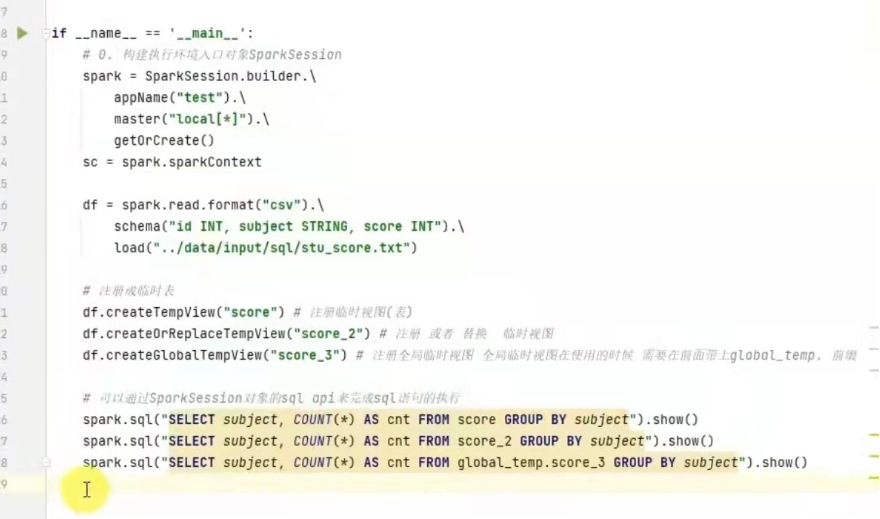
使用sql风格的语法,需要将dataframe注册成表。
df.createTempView("score" )#注册一个临时表
df.createOrReplaceTempView("score" )#注册一个临时表,如果存在进行替换。
df.createGlobalTempView("score" )#注册一个全局表
全局表:跨sparksessi9n对象使用,在一个程序内的多个sparksession 中均可调用,查询前带上前缀,global_temp.
临时表:只在当前sparksession中使用。
代码
DSL - printSchema
功能: 打印输出df的schema信息
语法: df.printShema()
pyspark.sql.functions包
这个包里面提供了一系列的计算函数供sparksql使用。
使用:
导包 from pyspark.sql import functions as F
F.split(被切分的列,切分字符串)
F.explode(被转换的列 )
这些功能函数,返回值多数都是column对象。
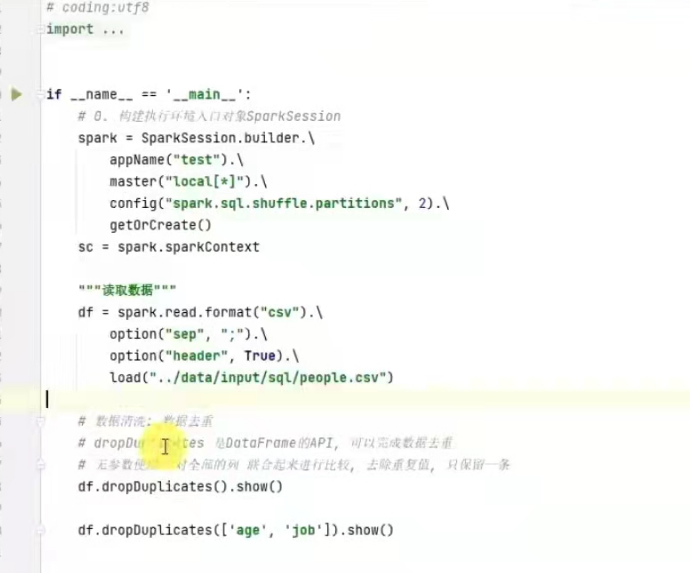
sparksql 数据清洗api
去重方法 dropDuplicates
用法:
df.dropDuplicates().show() #无参数是对数据整体去重
df.dropDuplicates(["name","age"]).show()#针对字段去重
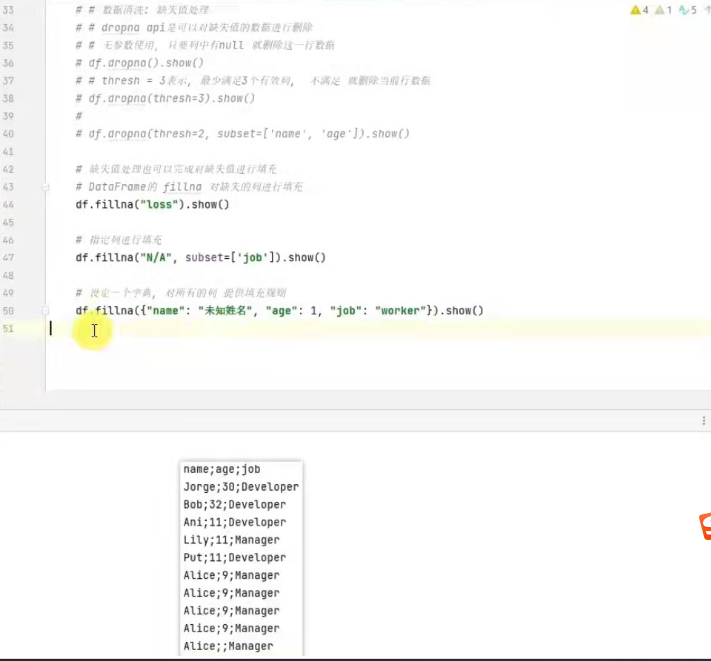
dropna 删除空行
fillna 填充
例子
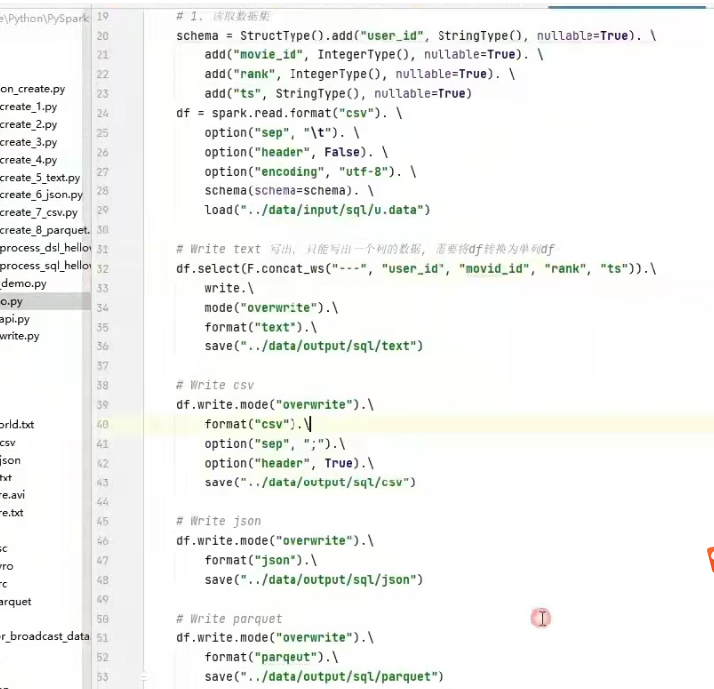
dataframe数据写出
统一api语法:
df.write.mode().format().option(k,v).save(path)
mide:append 追加,overwrite 覆盖,ignore 忽略 ,error 重复就报异常(默认的)
option: 设置属性
save 写出的路径
例子
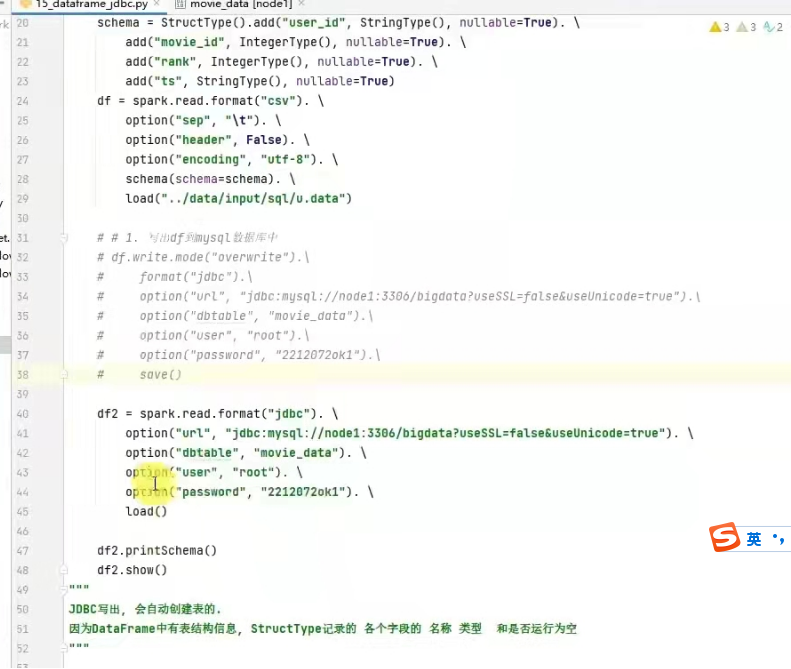
dataframe通过JDBC读写数据库
需要安装MySQL驱动包才行
代码
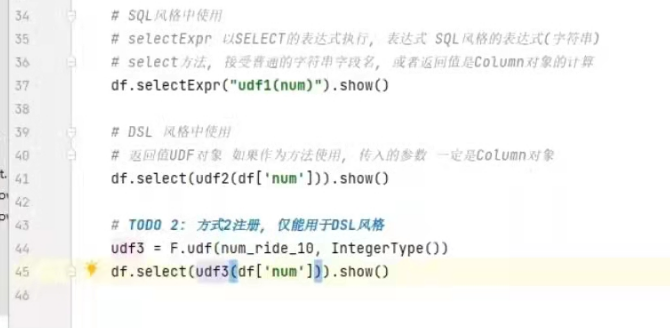
sparksql定义UDF函数
UDF:一对一的关系,输入一个值输出一个值。
定义方式有2种:
- sparksession.udf.register()
注册的udf可以用于DSL和sql,返回值用于DSL风格,传参内的名字可用于sql风格。
2).pyspark.sql.functions.udf
仅用于DSL风格