Flask
优势:
- 相对主流框架,功能组件全
- 教科书式框架
劣势:
- 服务资源浪费
- 开发繁琐
重量级的web框架,开发效率高,MTV框架,自带ORM,admin后台管理,自带的sqlite数据库和开发测试用的服务器,模板引擎,支持jinja模板引擎,适合做企业级的网站开发
Flask
优势:
- 节省资源 轻量级框架
- 开发简便 速度快
劣势:
组件极少 Session
- 第三方组件 非常全 Flask-Session
- Flask 更新 组件第三方的 稳定性相对较差
轻量级web框架,默认依赖两个外部库:jinja2和Werkzeug WSGI工具
适用于做小型网站以及web服务的API,开发大型网站无压力,但架构需要自己设计
与关系型数据库的结合不弱于Django
pc,pyo,pyc,pyd区别
py是源文件,
pyc是源文件编译后的文件
pyo是源文件优化编译后的文件
pyd是其他语言写的python库
Flask
flask是一个典型的MVC框架
Flask框架依赖组件?
Route(路由)
templates(模板)
Models(orm模型)
blueprint(蓝图)
Jinja2模板引擎
什么是g
在flask,g对象是专门用来存储用户数据的,它是global的缩写,g是全局变量,在整个request生命周期内生效。
Response
1."HW"
2.render_template("he.html")
3.redirect("/url")
4.jsonify() # 返回标准JSON格式数据 在响应头中 Content-Type:application/json
5.send_file() # 打开并返回文件 自动识别文件类型 Content-Type:文件类型
@app.route('/get_file')
def get_file():
return send_file("3.mpa")
Request
1.args 保存URL中传递的参数数据 to_dict() 字典形式取值 ImmutableMultiDict([('name', 'as')])
print(request.args.to_dict()) #{'name': 'asd'}
2.form 获取FormData中的数据 to_dict() 字典形式取值
3.method 判断请求方式
4.*path 路由地址 /post_data 就是@app.route('/post_data',methods=['GET','POST'])
5.*url 访问地址 http://127.0.0.1:5000/post_data
6.*host 主机地址 127.0.0.1:5000
7.*host_url 主机访问地址 http://127.0.0.1:5000/
8.files 获取所有数据中的文件数据 (图片,文件等)
9.data b"" 获取原始请求体中的数据 Content-Type 不包含 form-data的数据,b’’里边就有值
10.json 获取当请求头中带有 Content-Type:application/json 请求体中的数据 None Content-Type:application/json -> dict()
<input type="file" name="my_file">
<input type="submit" value="提交">
aa = request.files.get('my_file')
aa.save(aa.filename)
例子:
from flask import Flask, render_template, jsonify, request
import time
import os
import base64
app = Flask(__name__)
UPLOAD_FOLDER = 'upload'
app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER #上传文件夹
basedir = os.path.abspath(os.path.dirname(__file__))
ALLOWED_EXTENSIONS = set(['txt', 'png', 'jpg', 'xls', 'JPG', 'PNG', 'xlsx', 'gif', 'GIF'])
# 用于判断文件后缀
def allowed_file(filename):
# print(1111,'.' in filename and filename.rsplit('.', 1)[1] in ALLOWED_EXTENSIONS)
return '.' in filename and filename.rsplit('.', 1)[1] in ALLOWED_EXTENSIONS
# 用于测试上传,稍后用到
@app.route('/test/upload')
def upload_test():
return render_template('upload.html')
from flask import send_file
# 上传文件
@app.route('/api/upload', methods=['POST'], strict_slashes=False)
def api_upload():
file_dir = os.path.join(basedir, app.config['UPLOAD_FOLDER'])
print(file_dir)
if not os.path.exists(file_dir):
os.makedirs(file_dir)
f = request.files['myfile'] # 从表单的file字段获取文件,myfile为该表单的name值
print(11,f,f.filename)
if f and allowed_file(f.filename): # 判断是否是允许上传的文件类型
fname = f.filename #上传文件的名字
print(22,fname)
ext = fname.rsplit('.', 1)[1] # 获取文件后缀
unix_time = int(time.time())
new_filename = str(unix_time) + '.' + ext # 修改了上传的文件名
print(4,new_filename)
f.save(os.path.join(file_dir, new_filename)) # 保存文件到upload目录
token = base64.b64encode(b'new_filename')
return jsonify({"errno": 0, "errmsg": "上传成功", "token": token})
else:
return jsonify({"errno": 1001, "errmsg": "上传失败"})
from flask import request, jsonify, send_from_directory, abort
import os
# 下载
@app.route('/download/<filename>')
def download(filename):
if request.method == "GET":
if os.path.isfile(os.path.join('upload', filename)):
# as_attachment=True 表示文件作为附件下载
return send_from_directory('upload', filename, as_attachment=True) #用send_file也可以,
#send_file:为了直接实现用户访问某一个 URL 时就可以下载到文件,我们就使用 send_file 来实现。
abort(404)
if __name__ == '__main__':
app.run(debug=True)
# pass
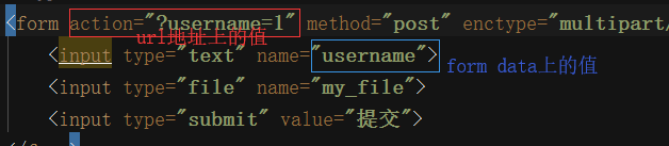
values 保存 URL + FormData 坑!
两个key一样,先获取form的值,后获取url地址的值,最后url覆盖form的值。
print(4,request.values.to_dict())
结果{'username': '1'}
jinjia2:
{{ }} :执行 和调用 引用 {% %}: 所有逻辑代码 可以使用()【】
Markup :不需要转义
def index():
input_str=Markup("<input type='text' name='username'>")
return render_template('my_func.html',input_str=input_str)
装饰器
给多个函数加装饰器有两种:
1)导入 from functools import wraps,在装饰器里写上@wraps(func)
查看原视图函数的名称 : 视图名称.name
def war(func):
@wraps(func) #装饰多个函数,为防止所有函数名都变成inner
def inner(*args,**kwargs):
if session.get('username'):
ret = func(*args,**kwargs)
return ret
else:
return redirect('/login')
return inner
2)在app.route里添加endpoint=‘xxx’
@app.route('/index',endpoint='index')
特殊装饰器
1.@app.before_request 请求进入视图函数之前处理
2.@app.after_request 响应返回客户端之前
执行顺序 :正常 be1 - be2 – vf(视图函数) - af2 - af1
异常 be1 - af2 - af1 (只要有响应,有返回值,after全部倒序执行)
3.@app.errorhandler(404) 重定义错误返回信息
1.methods 当前视图函数允许的请求方式 methods=[‘get’,’post’] 是修改不是追加
2.endpoint URL视图映射 路由对照表重要的Key 唯一值
-
url_for(endpoint) 反向生成URL地址
@app.route('/index',endpoint='asd ‘)
print(url_for('asd')) 结果是/indexs
endpoint说明:每个app中都存在一个url_map,这个url_map 中包含了url到endpoint的映射
endpoint作用: 当request请求传来一个url的时候,会在url_map中先通过rule找到endpoint,然后再在view_functions 中根据endpoint 再找到对应的视图函数 view_func. endpoint默认是视图函数的名称。
例子:
from flask import Flask,Response
app = Flask(__name__)
@app.route('/test')
def test():
return 'test'
@app.route('/hello',endpoint='out_set')
def hello_world():
print(app.view_functions)
print(app.url_map)
return 'hello world'
if __name__ == '__main__':
app.run()
可以通过view_functions查看当前endpoint与视图函数的对应情况
可以通过url_map查看当前url与endpoint的绑定情况
结果如下:
{'static': <bound method _PackageBoundObject.send_static_file of <Flask 'app'>>, 'test': <function test at 0x000001810DE5A0D0>, 'out_set': <function hello_world at 0x000001810DE44E18>}
Map([<Rule '/hello' (HEAD, GET, OPTIONS) -> out_set>,
<Rule '/test' (HEAD, GET, OPTIONS) -> test>,
<Rule '/static/<filename>' (HEAD, GET, OPTIONS) -> static>])
- url_for实现反转
静态文件引入: url_for("static",filename='文件路径')
定义路由: url_for("模块名.视图名",变量=参数)
-
app.add_url_rule(rule,endpoint=None,view_funv=None)
view_func:指定视图函数的名称
例子:def my_test():
return 'my_test'
app.add_url_rule(rule='/test',view_func=my_test,endpoint='test')
3.strict_slashes 是否严格遵循路由地址规范
4.redirect_to=’/index1’ 永久重定向 301/308 (就是输入index,就跳转到index1),节省内存
5.动态参数路由:
/index/<int:page>
/index/<string:page>
/index/<page> #默认是string
/index/<path>/<file_name>
例:
@app.route('/index1/<path>/<file_name>',methods=['GET','POsT'], endpoint='asda' )
def index(file_name,path):
aa = os.path.join(path,file_name)
return send_file(aa)
Flask中的参数配置
1.Flask实例化配置
app = Flask(__name__,
template_folder #模板文件存储的文件夹
static_folder #静态文件存储的文件夹
static_url_path #静态文件访问路径 默认情况几下 /+static_folder
*static_host="http://222.222.222.222:2222", # 静态文件服务器
*host_matching=False, # app.config["SERVER_NAME"] 127.0.0.1:5000
*subdomain_matching=False, # app.config["SERVER_NAME"]
**instance_path=None, # 指向实例
)
2.Flask对象配置
app.default_config 参考Flask配置项 (所有的配置都在这里,忘记的,点他就行)
1)新建一个setting配置文件:
class DebugSetting(object): debug阶段
DEBUG = True
SECRET_KEY = "ABCDEFGHI"
SESSION_COOKIE_NAME = "I am Not Session" #给session起个假名
PERMANENT_SESSION_LIFETIME = 1 #1天
class TestSetting(object): 测试阶段
TESTING = True
SECRET_KEY = "@#$%^&*$%&^&**&^&$%*^T&Y*%^&&$%&&*(J"
SESSION_COOKIE_NAME = "!@#%$^&()"
PERMANENT_SESSION_LIFETIME = 7
2)在一个py文件导入
from setting import DebugSetting
from setting import TestSetting
app.config.from_object(DebugSetting) # 快速进行OBJ配置
app.config.from_object(TestSetting)
Blueprint
把蓝图当做不能够被run的Flask实例, 也没有config, 只有执行run才有config
功能代码隔离
用法:
Flask.register_blueprint
url_prefix='/my_bp' 是url前缀,就是在访问bpindex时访问不到,必须/my_bp/bpindex才行。
例:
s4_bp.py文件
from flask import Blueprint
bp = Blueprint('bp',__name__,url_prefix='/my_bp') #必须传两个参数
@bp.route('/bpindex')
def bpindex():
return ' i am bpindex'
S4.py文件
from flask import Flask
from s4_bp import bp 导入的是等号左边的bp
app = Flask(__name__)
app.debug=True
app.register_blueprint(bp) 注册上bp
if __name__ == '__main__':
app.run()
** 作用:**
将不同的功能模块化
构建大型应用
优化项目结构
增强可读性,易于维护(跟Django的view功能相似)
Flask中多app应用是怎么完成?
请求进来时,可以根据URL的不同,交给不同的APP处理
Session 会话
当前的Session是个公共对象,可能会涉及到被改写的情况 FLask的实现机制是 请求上下文机制
交由客户端保管机制 Cookie
使用到Flask中的session ,使用session必须有secret_key
app.secret_key = "!@#\(%^&U*\)%^&*()"
如何在Flask中访问会话?
会话(seesion)会话数据存储在服务器上.会话是客户端登录到服务器并注销的时间间隔.需要在此会话中进行的数据存储在服务器上的临时目录中.
from flask import session 导入会话对象
session['name'] = 'admin' 给会话添加变量
session.pop('username', None) 删除会话的变量
**Flask-Session **
使用session时不用再写app.secret_key='$#%#4',导入redis就行
from redis import Redis
from flask_session import Session
from flask import session
app = Flask(__name__)
app.config["SESSION_TYPE"] = "redis"
app.config["SESSION_REDIS"] = Redis("127.0.0.1",6379)
Session(app)
@app.route('/index',methods=['GET','POST'])
def index():
session['username']='alexss'
return jsonify({'name':666})
浏览器 cookie = {"session":"2b89a941-1fa2-4da9-941b-11b6ca7ffae3"}
app.session_cookie_name + sid
在终端redis-cli get "session:2b89a941-1fa2-4da9-941b-11b6ca7ffae3"
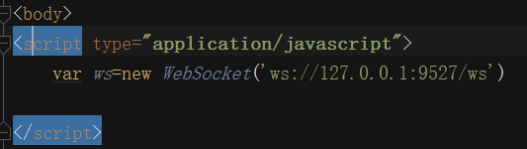
websocket
@app.route('/ws')
def my_ws():
# print(request.environ)
user_socket=request.environ.get('wsgi.websocket')
print(user_socket)
return '200 ko'
if __name__ == '__main__':
server=WSGIServer(('0.0.0.0',9527),app,handler_class=WebSocketHandler)
server.serve_forever()
列举使用过的Flask第三方组件?
flask_bootstrap
flask-WTF
flask_sqlalchemy
wtforms组件的作用?
WTForms是一个支持多个web框架的form组件,主要用于对用户请求数据进行验证
Flask中多app应用是怎么完成?
请求进来时,可以根据URL的不同,交给不同的APP处理
Flask框架默认session处理机制?
Flask的默认session利用了Werkzeug的SecureCookie,把信息做序列化(pickle)后编码(base64),放到cookie里了.
过期时间是通过cookie的过期时间实现的.
为了防止cookie内容被篡改,session会自动打上一个叫session的hash串,这个串是经过session内容、SECRET_KEY计算出来的,看得出,这种设计虽然不能保证session里的内容不泄露,但至少防止了不被篡改.
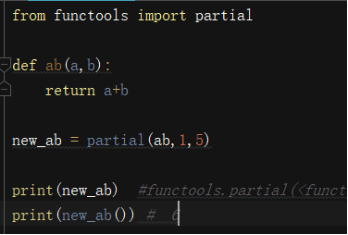
偏函数
线程安全
既保证速度又保证安全
import time
from flask import Flask
from threading import Thread,local
class Foo(local):
# class Foo(object):
num = 0
foo = Foo()
def add(i):
foo.num+=i
# time.sleep(0.5)#
print(foo.num) # 1.3 6.10,......190
if __name__ == '__main__':
for i in range(20):
# add(i)
task = Thread(target=add,args=(i,))
task.start()
正确结果: 0,1,2....19
捕获异常
-
http主动跑出异常
abort方法: 抛出一个给定状态代码的http exception 或者指定响应。例如,想要用一个页面为找到异常来终止请求,可以调用abort(404) -
捕获错误
errorhandle装饰器:注册一个错误程序,当程序抛出指定错误状态码时,就会调用该装饰器所装饰的方法
例子:统一处理状态码为500的错误给用户友好的提示处理所有500类型的异常
@app.errorhandler(500)
def internal_server_error(e):
return '服务器搬家了'处理特定的异常项
@app.errorhandler(ZeroDivisionError)
def zero_division_error(e):
return '除数不能为0'
上下文管理流程:
1、'请求刚进来':
将request,session封装在RequestContext类中
app,g封装在AppContext类中
并通过LocalStack将requestcontext和appcontext放入Local类中
LocalStack = {
_local :{
__storage__:{9527:{'stack':[ctx.r.s]}}
__ident_func__:get_ident 获取线程协成id
}
}
2、'视图函数中':
通过localproxy--->执行偏函数--->localstack--->local取值
3、'请求响应时':
先执行save.session()再各自执行pop(),将local中的g数据清除
为什么要Flask把Local对象中的值stack维护程一个列表
因为通过维护成列表,可以实现一个栈的数据结构,进栈出栈时只取一个数据,巧妙的简化了问题。
还有,在多app应用时,可以实现数据隔离;列表里不会加数据,而是会生成一个新的列表
local是一个字典,字典里key(stack)是唯一标识,value是一个列表
人工智能
1.语音合成 嘴巴 tts 把字转换成语音
2.语音识别 耳朵 asr 把音频转成汉字
3.nlp自然语言处理
4.Tuling 智能对话
音频文件转码
ffmpeg -y -i 16k.wav -acodec pcm_s16le -f s16le -ac 1 -ar 16000 16k.pcm
ffmpeg –i 1.amv 1.mp3
4.图灵网址
tuling123.com
https://www.kancloud.cn/turing/www-tuling123-com/718227
websocket原理
首先websocket建立客户端连接,就是往web服务器上发了一个http请求
在使用new websocket那一刹那,就发起一个http请求,
http里边带着一个upgrade=websocket,wsji发现upgrade不是http时,需要交给另一人取处理,WebSocketHandler在里边找到一个字符串(秘钥),要跟公钥进行拼接,sha1被base64重新加密,然后客户端给我发的私钥,我就给客户端发去我的私钥,websockethandler不会主动断开,把链接存到一个位置上,断不断开由客户端决定,客户端拿accept校验两边的是不是一样,不一样连接断开,一样就不断开,比对成功之后,就可以互相通信了。
MongoDB
使用nosql 选中代码,按ctrl+enter
MongoDB缺陷-牺牲掉大部分磁盘空间
1.概念
MongoDB - NoSql 非关系型数据库
使用了不存在的对象即创建改对象
补充怎么启动MongoDB
-
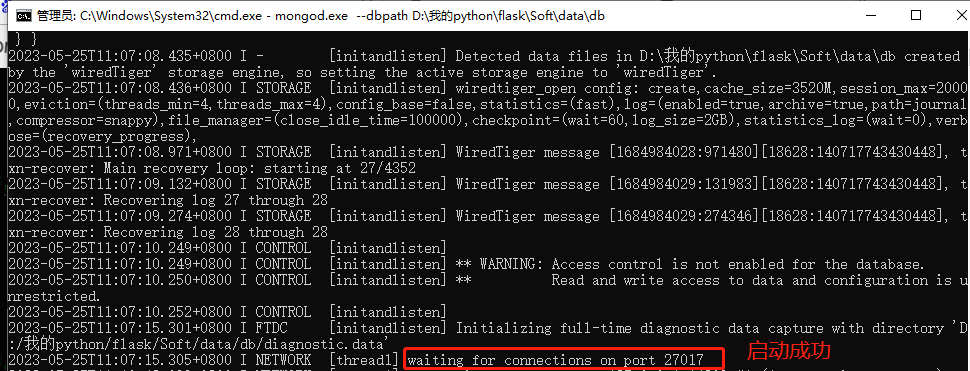
打开MongoDB下载的路径,cmd进入到D:\我的python\flask\Soft\mongoDB\bin
2.任意位置新建名为data的文件夹,在data文件夹下新建db文件夹,db文件夹用于存储MongoDB数据。(我的在D:\我的python\flask\Soft\data\db)
3.启动命令:mongod.exe --dbpath D:\我的python\flask\Soft\data\db
-
不关闭这个窗口,在bin文件夹先在重新启动一个窗口,启动命令: mongo ,此时就OK了。
2.命令1.mongod 启动MongoDB服务
- -dbpath = D:\我的python\flask\Soft\data\db("数据库存放路径")
2.mongo 开启mongoDB控制台客户端
点save&connection,就可以使用nosql了
3.show databases 查看当前服务器磁盘上的数据库
4.use dbname 在内存中创建数据库或使用磁盘上的数据库
5.show tables 查看当前数据库磁盘中的数据表
6.db.tabalename 在内存中创建数据表 或使用磁盘中的数据表
当dbname 存在时切换
当dbname 不存在时在内存中创建数据库
7. db 代指当前使用的数据库 查询当前使用的数据库名
**3. MongoDB的增删改查 **
from bson import ObjectId
1.增 db.tabalename.insert({name:1})
2.查db.tabalename.find({查询条件))
查询条件-db.tabalename.find({name:888,age:16})
3.删 db.tabalename.remove(删除条件) 所有符合条件的数据(不写条件是删除所有)
db.users.remove({'name':'alex'})
4.改 db.tabalename.update({查询条件},{$修改器:{修改内容}}) #没有就是创建,有就是修改
$set: 用来强制修改某值,符合不存在即创建的逻辑
db.tabalename.update({}, {$set:{name:"亚历山大"}})
**在mongodb 查询 **
例:查询事件在12月20号,并且du_title 包含 疾控 的词语
#使用正则 模糊查询
db.a617a540880582c3aaca1e68bs.find({'create_time':{'$gte':'2021-12-20T00:00:00.000Z'},'du_title':/^.*疾病.*$/}).count()
#或者
db.a617a540880582c3aaca1e68bs.find({'create_time':{'$gte':'2021-12-20T00:00:00.000Z'},'du_title':{'$regex':/^.*疾病.*$/}}).count()
#按pv升序,查找时间在2022-01-07间的
db.a617a540880582c3aaca1e68bs.find({'create_time':{'$regex':"^2022-01-07"}}).sort({"pv":-1})
在 pymongo 例查询
#使用正则 模糊查询
result =self.kefudata_resource.find({'create_time': {'$gte': '2021-12-20T00:00:00.000Z'}, 'du_title': re.compile('疾控')}) # 包含关 系
for i in result:
print(i)
#不包含某个字段为 '' 空的 值
result = self.kefudata_resource.find({'create_time':{ "$regex": "^2021-11-19"},'du_scrid':{"$nin":['']}}).limit(1000)
按pv升序,查找时间在2022-01-07间的
db.a617a540880582c3aaca1e68bs.find({'create_time':{'$regex':"^2022-01-07"}}).sort([('pv',-1)])})
<b>sort 字段,在python中只能使用列表进行排序,不能使用字典</b>
在 pymongo 新增或更改数据
def save_resource(self):
count=0
for line in fileinput.input('ph_1.txt'):
linestd=line.strip()
linearr=linestd.split('\t')
# print len(linearr)
# print linearr
name=linearr[2]
address = linearr[3]
phone = linearr[4].split('\n')[0]
prov = linearr[0]
city = linearr[1]
district=""
print(address)
print (name)
if len(linearr)==6:
district=linearr[5]
query = {"title": name + '热线电话',"phone_list.phone":phone}
response_1 = self.kefudata_resource.find_one(query)
if response_1:
print( str(name) )
else:
data={
"phone_list": [
{
"phone": phone,
"order_weight": 0,
"name": "联系电话 "
}
],
"key": name + '客服',
"title": name+"热线电话",
"url": "https://haoma.baidu.com/",
"showurl": "https://haoma.baidu.com/",
"key_list": name,
"source": "hm_public",
"create_time": "2021-11-19T12:12:00.000Z",
"update_time": (datetime.now() - timedelta(hours=8)).strftime(
"%Y-%m-%d{}%H:%M:%S{}".format('T', '.000Z')),
"card_pctext": {
"d_name" : "企业官方号码",
"t_name" : "",
"d_color" : "",
"d_prefix" : "",
"t_prefix" : "",
"t_color" : "",
"d_type" : "tag",
"t_type" : "text"
},
"card_wisetext": {
"d_name" : "企业官方号码",
"t_name" : "",
"d_color" : "",
"d_prefix" : "以下号码为",
"t_prefix" : "类型:",
"t_color" : "",
"d_type" : "tag",
"t_type" : "text"
},
"page_pctext": {
"d_name" : "企业官方号码",
"t_name" : "",
"d_color" : "",
"d_prefix" : "",
"t_prefix" : "",
"t_color" : "",
"d_type" : "tag",
"t_type" : "text"
},
"page_wisetext": {
"d_name" : "企业官方号码",
"t_name" : "",
"d_color" : "",
"d_prefix" : "以下号码为",
"t_prefix" : "类型:",
"t_color" : "",
"d_type" : "tag",
"t_type" : "text"
},
"bg_peak": {
"bgHeight" : "1.01",
"gradientPoint" : "0,0,1,1",
"endColor" : "#4E6EF2",
"bgColor" : "#4E6EF2",
"startColor" : "#4E6EF2",
"type" : "1"
},
"is_out": 1,
"is_pay": 0,
"is_sort": "0",
"longitude": "0",
"latitude": "0",
"iscicaopay": "0",
"create_at": datetime.now(),
"update_at": datetime.now(),
"__v": 0,
"url_error": "1",
"word_audit": "1",
"status": "0",
"address":address,
"key_items": {
"phone_type": phone.replace('-',''),
"area": " ",
"brand": "住房公积金管理中心"
},
"arealoc": {
"prov": prov,
"city": city,
"district":district,
"town":""
}
}
print (data)
count+=1
self.kefudata_resource.save(data)
print(count)
# 更改字段
# def update_resource(self):
# count=0
# l = ['国网','电网','电力服务','国家电网']
# for line in fileinput.input('ph_1.txt'):
# linestd=line.strip()
# linearr=linestd.split('\t')
# # print len(linearr)
# # print linearr
# name=linearr[2]
# address = linearr[3]
# phone = linearr[4].split('\n')[0]
# prov = linearr[0]
# city = linearr[1]
# district=""
# print(address)
# print (name)
# query = {"title": name + '热线电话', "phone_list.phone": phone}
# result_list = self.kefudata_resource.find(query)
# if result_list:
# for kefu_data in result_list:
#
# kefu_data["key_items"]["brand"] ='国网,'+'电网,'+'电力服务,'+'国家电网'
#
# kefu_data["update_time"] = (datetime.now() - timedelta(hours=8)).strftime(
# "%Y-%m-%d{}%H:%M:%S{}".format('T', '.000Z'))
#
# count+=1
# self.kefudata_resource.save(kefu_data)
# print(result_list)
# # print (count )
补充: 3.2版本推荐写法
查: db.users.find({}) db.users.findOne({})只显示第一条
增: insertOne({})只插入一条 insertMany({},{})插入多条 insert 官方不推荐了
·Inserted_id inserted_ids
改: updateOne({},{$修改器:{预修改值}})只更新第一条符合条件的 updateMany({},{$修改器:{预修改值})更新所有符合条件的数据 update({})官方不推荐写法
删: deleteOne({}) 只删除第一条符合条件的 deleteMany({})删除所有符合条件的 remove({}) //官方不推荐 没有delete
数据类型
在MongoDB中dict叫object,列表叫Arrays数组
首先我们要先了解一下MongoDB中有什么样的数据类型:
Object ID :Documents 自生成的 _id #不能被json
String: 字符串,必须是utf-8
Boolean:布尔值,true 或者false (这里有坑哦~在我们大Python中 True False 首字母大写)
Integer:整数 (Int32 Int64 你们就知道有个Int就行了,一般我们用Int32)
Double:浮点数 (没有float类型,所有小数都是Double)
Arrays:数组或者列表,多个值存储到一个键 (list哦,大Python中的List哦)
Object:如果你学过Python的话,那么这个概念特别好理解,就是Python中的字典,这个数据类型就是字典
Null:空数据类型 , 一个特殊的概念,在python中是None,其他的都是 Null
Timestamp:时间戳
Date:存储当前日期或时间unix时间格式 (我们一般不用这个Date类型,时间戳可以秒杀一切时间类型) db.users.insert({time:ISODate()})
$数学比较符-
$lt 小于 db.users.find({age:{$lt:50}})
$lte 小于等于 db.users.find({age:{$lte:50}})
$gt 大于 db.users.find({age:{$gt:50}})
$gte 大于等于 db.users.find({age:{$gte:50}})
$eq 等于 db.users.find({age:{$eq:24}})
$ne 不等于 db.users.find({age:{$ne:24}}) #age不等于24和连age字段都没有的,也都查出来
$关键字
保存符合条件元素的下标索引 - Array
只能存储第一层Array的下标
db.users.update({'user_info.hobby':'aa'},{'$set':{'user_info.hobby.$':'132456'}})
$修改器
$set:强制修改器 $set:{"name":123}
db.users.update({'user_info.hobby':'aa'},{'$set':{'user_info.hobby.$':'132456'}})
$unset:强制删除字段 $unset:{"name":1} 整数代表删除
db.users.update({age:45}, {$unset:{age:1}})
$inc:引用增加 $inc:{"age":1} 只能加不能减
db.users.update({'user_info.name':'dd'},{$inc:{'user_info.age':5}}) 5是加5,-5是减5
array:
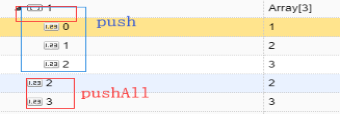
$push 对array数据类型追加数据
db.users.update({name:999},{$push:{li:8}})
$pushAll 打散Array逐一添加
db.users.update({name:999},{$pushAll:{li:[0,9,10,11,12]}})
$pull 对array数据类型减少数据
db.users.update({name:999},{$pull: {li:12}})
\(pullAll 在 Array 中删除多个符合条件的元素 \)pop 删除Array中的最后一个(正数)或者是第一个(负数)数据
db.users.update({name:999},{$pop: {li:-1}})
$查询关键字
$in 或条件查询 在相同字段之间的or查询
db.users.find({name:{$in:[777,999]}}) #意思是(name是777或者999的)
$all 子集查询
db.users.find({li:{$all:[8,2,5]}}) #8,5,2是Array里的数,不是索引,有一个不存在就找不到
$or 或条件查询 在不同字段之间的or查询
db.users.find({$or:[{name:999},{age:17}]})
//db.tablename.find({$or:[{age:6},{age:10}]})
意思是符合{name:999}或者符合{age:17}的
$and 与逗号 与条件查询
db.users.find({$and:[{name:777},{age:17}]})
组合条件查询
db.users.find({$or:[{name:999},{name:888,age:24}]}
在MongoDB里边使用
1. 查询条件
这节来说说mongodb条件操作符,"\(lt", "\)lte", "\(gt", "\)gte", "$ne"就是全部的比较操作符,对应于"<", "<=", ">", ">=","!="。
原子操作符:"\(and“, "\)or“, "$nor“。
or查询有两种方式:一种是用\(in来查询一个键的多个值,另一种是用\)or来完成多个键值的任意给定值。$in相当于SQL语句的in操作。
$nin不属于。
$not与正则表达式联合使用时候极其有用,用来查询哪些与特定模式不匹配的文档。
$slice相当于数组函数的切片,检索一个数组文档并获取数组的一部分。限制集合中大量元素节省带宽。理论上可以通过 limit() 和 skip() 函数来实现,但是,对于数组就无能为力了。 $slice可以指定两个参数。第一个参数表示要返回的元素总数。第二个参数是可选的。如果使用的话,第一个参数定义的是偏移量,而第二个参数是限定的个数。第二个参数还可以指定一个负数。
$mod取摸操作。
$size操作符允许对结果进行筛选,匹配指定的元素数的数组。
\(exists操作符允许返回一个特定的对象。注意:当前版本\)exists是无法使用索引的,因此,使用它需要全表扫描。
$type操作符允许基于BSON类型来匹配结果
1)sort 排序 1 正序 -1倒序 字典{}
db.users.find({}).sort({ _id:-1 })
2)limit 限制选取
db.users.find({}).limit(5)
db.users.find({}).limit(5).sort({ _id:-1 }) //选取排序逻辑顺序 , 先排序 再选取
3).skip 跳过
db.users.find({}).skip(9) // 跳过 ,从第10个开始
db.users.find({}).skip(2).sort({ _id:-1 }) // 跳过排序逻辑熟悉怒 先排序 后跳过
4)混合用法
db.users.find({}).limit(5).skip(5) // 逻辑顺序 先跳过再选取
db.users.find({}).limit(5).skip(5).sort({ _id:-1 }) // 排序跳过选取,逻辑顺序 1.先排序 2.跳过 3.选取
在pymongo里边(pycham) find查询写上list才显示数据
1)sort 排序 元祖(,)
不写p/ymongo.ASCENDING默认是升序,pymongo.ASCENDING是降序 1 或是-1 也行
import pymongo
res=db.users.find({}).sort('_id',pymongo.ASCENDING)
print(res)
2)limit
res = db.users.find({}).limit(5)
res_list=list(res)
# print(list(res),len(res)) 求长度不能这样写,他是生成器
print(res_list,len(list(res_list)))
3)skip
res = db.users.find({}).skip(5)
res_list=list(res)
# print(list(res),len(res)) 求长度不能这样写,他是生成器
print(res_list,len(list(res_list)))
4)分页
res = db.users.find({}).limit(2).sort('_id',-1).skip(0)
print(list(res))

规律
Num (page-1) num
2 (1-1)2
2 (2-1)2
2 (3-1)2
查
Db.users.find({}) // <pymongo.cursor
list(Db.users.find({})) // {'_id': ObjectId('5cfdf1a89d500620c47e605e'),
增
res= db.users.insert_one/insert_many
res. Inserted_id inserted_ids
删
db.users.delete_one({})
db.users.delete_many({})
改
res = db.users.update({'name':'2','hobby':'11'},{'$set':{'hobby.$':'吃'}})
print(res)
for index,item in enumerate(res.get('hobby')):
print(index,item)
if item == '吃':
res['hobby'][index]='吃饭'
print(res)
db.users.update_one({'name':'2'},{'$set':res}) #把修改的数据放到数据库
MUI
使用Mui进行app开发
MUI是一个面向对象的图形用户界面来创建和维护系统
Mui代码块搭建页面
Mui + Html5 PLUS = 移动端App(JS)
手机+pad 移动端App开发
J2ME 移动端应用
J2EE web应用
J2SE 桌面应用
开发工具 - HBuilder or HBuilder X
夜声模拟器 62001
**html5 plus是什么? **
它是增强版的手机浏览器引擎, 让HTML5达到原生水平, 它提供WebApp的规范.
它结合MUI(前端框架) + HBuilder(开发工具) 即可迅速实现开发一个app.
代码块激活字符:
Md 重新构建HTML
mhe 带返回箭头的header
mbo :div标签
msl轮播图
mg九宫格
mli 图片居左
mta : mb button按钮
ming :mui.init({})
Dga: document.getElementById('login').addEventListener('tap',function () {
Mdt: mui.toast('123') 打印的意思
mui 会屏蔽掉onclink 事件
dga : document.getElementById('pl').addEventListener('tap',function () {})
//点击pl跳转到user_info的页面
#打开新窗口
mui.openWindow({
url:'user_info.html',
id:'user_info.html'
})
Html5plus webview
1.mui.plusReady(function(){当html5plus加载完成后立即触发的事件})//在mui代码中加在HTML5plus
2.ajaxpost请求提交数据
mui.post(‘url’,{data},SCB,’json’) 只支持form表单
mui.post('http://192.168.43.216:9527/login',{
username:u,
password:p
},function(data){
mui.toast(data.msg)
},'json'
);
mui的自定义事件
Fire
Mui.fire(targetWebview,’事件名称’,{数据})
例:
Var player=null
player=plus.webview.getWebviewById('player.html')
document.getElementById('stop').addEventListener('tap',function () {
mui.fire(player,'callplayer',{'action':'stop'});
})
Targetwebview;
Document.addEventListener(‘事件名称’,function(event){
Event.detail—数据})
例:
window.addEventListener('callplayer',function(event){
if (event.detail.action=='play'){
p.play();
}else{
p.stop();
}
})
Html5plus
plusaudio 通过plusaudio实现音频播放
创建一个对象:Plusaudio.createPlaer(“url”)
返回值:audioPlayer
Audioplayer.play()
Audioplayer.pause()
Audioplayer.resume()
例:
var p=null;
mui.plusReady(function () {
p=plus.audio.createPlayer('http://192.168.43.216:9527/get_music')
});
document.getElementById('play').addEventListener('tap',function () {
p.play(); //播放
});
document.getElementById('pause').addEventListener('tap',function () {
p.pause();//暂停
});
document.getElementById('resume').addEventListener('tap',function () {
p.resume();//继续
})
plusuploader : 从本地上传文件到服务器
plus.audio.getRecorder();创建录音管理对象
plus.audio.getRecorder();创建音频管理对象
plus.uploader.createupload();上传任务管理对象
uploader用法 文件上传
例:1)
document.getElementById('reco').addEventListener('hold',function () {
console.log('按住了');
reco.record( {filename:"_doc/audio/",format:"amr"}, function (recordFile) {
console.log(recordFile);//此处可以执行上传任务
startUpload(recordFile); //上传文件
});
2)
function startUpload(filename){
Varuptask=plus.uploader.createUpload('http://192.168.43.216:9527/uploader',{},function(upload,status){
console.log(upload);
console.log(status);
console.log(JSON.stringify(upload));
console.log(JSON.parse(upload.responseText).msg);
})
uptask.addFile(filename,{key:'my_record'});
uptask.addData('k1','v1');
uptask.start();
}
3)
@app.route('/uploader')
def uploader():
print(request.form)
print(request.form)
file = request.files.get('my_record')
file.save(file.filename)
return jsonify({'code':0,'msg':'上传成功'})
机器学习:
1.jieba 模块 中文分词
将 | 一句话 | 拆分 | 成 | 词语
jieba.cut()
['太上皇', '打天下', '到', '一半儿', '挂', '了']
将 | 一 | 句 | 话 | 拆分 | 成 | 词语
将 | 一句话 | 一 | 句 | 话 | 拆分 | 成 | 词语
打 | 天下 | 打天下 |
jieba.cut_for_search(a)
['太上', '太上皇', '天下', '打天下', '到', '一半', '半儿', '一半儿', '挂', '了']
2.pypinyin 模块 将汉语转换为汉语拼音
**3.Gensim 机器学习综合模块 **
语料库-概念 问题库
词袋 - 中文词语或者是字 转化为数字
向量 - 概念
稀疏矩阵相似度算法 - 两组词语或句子相似度得分
# nlp_simnet()
Sqlalchemy
https://blog.csdn.net/wly55690/article/details/131683846
使用ORM操作数据库
优势 :代码易读 忽略原生SQL
劣势 :执行效率低 - 将方法转换为原生SQL 原生SQL还不一定是最优的
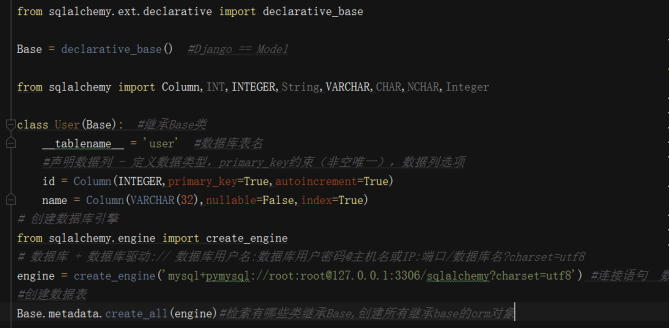
Base = declarative_base() #相当于Django的models.model
class User(Base): #继承Base类
__tablename__ = 'user' #数据库表名
Id=column()声明数据列
数据类型:
INT,INTEGER,String,VARCHAR,CHAR,NCHAR,Integer
primary_key=True
autoincrement=True
nullable=False:不为空
index=True #创建索引
创建数据库引擎
from sqlalchemy.engine import create_engine
数据库 + 数据库驱动:// 数据库用户名:数据库用户密码@主机名或IP:端口/数据库名?charset=utf8
engine = create_engine('mysql+pymysql://root:root@127.0.0.1:3306/')#数据库连接语句(字符串)
from sqlalchemy.orm import sessionmaker
from create_table import engine
Session = sessionmaker(engine) #锁定创建会话窗口的数据库引擎
db_session = Session() #db_session 就是查询窗口
from create_table import User
1.增加数据
单条
user = User(name='alex') # insert into
db_session.add(user) # 将 insert into 写入到 db_session 窗口中
db_session.commit() # 执行语句
db_session.close() # 关闭查询窗口 db_session
多条操作
user_list = [
User(name='JWB'),User(name='DragonFire')
]
# for i in user_list:
# db_session.add(i)
db_session.add_all(user_list)
db_session.commit()
2.查询
res = db_session.query(User).first()#查单条
print(res.id,res.name)
res = db_session.query(User).all() #查多条
for i in res:
print(i.id,i.name)
条件查询
res = db_session.query(User).filter(User.id == 1).all() #是个列表
for i in res:
print(i.id,i.name)
res = db_session.query(User).filter(User.id == 1).first() 查询第一条
print(res.name)
3.修改
res = db_session.query(User).filter(User.id ==1).update({'name':'alexdsb'})
db_session.commit()
4.删除
db_session.query(User).filter(User.id == 1).delete()
db_session.commit()
高级查询
from sqlalchemy import or_,and_
res = db_session.query(User).filter(
or_(User.id==3,User.name == 'JWD'),
and_(User.id==3,User.name=='DragonFire')
).all()
for i in res:
print(i.name)
排序 desc()降序
res = db_session.query(User).order_by(User.id.desc()).all()
for i in res:
print(i.id)
范围取值
# res = db_session.query(User).filter(User.id.between(1,2)).all()
# for i in res:
# print(i.name)
res = db_session.query(User).filter(User.id.in_([1,2])).all()
for i in res:
print(i.name)
SQLAlchemy如何执行原生SQL?
使用execute方法直接操作SQL语句(导入create_engin、sessionmaker)
engine=create_engine('mysql://root:pwd@127.0.0.1/database?charset=utf8')
DB_Session = sessionmaker(bind=engine)
session = DB_Session()
session.execute('select * from table...;')

