模块
包
1.1)就是模块夹,存放一些模块,包下必有__init__.py文件
2)python2中没有__iinit__就报错 python3中可以没有
使用包时import后不能出现点
导入包使用*时在__init__中控制 ,all=[]
模块:
- 自定义模块:一个py文件就是一个自定义的模块
import 导入: 导入多个文件
import xxx as 别名
import 是全部拿过来了
2.from xxx import xx,oo,bb,tt
从xxx模块导入了xx
from xxx import xx as x1,oo as o1,bb as b1,tt as t1
从xxx模块导入了xx
from xxx import * 不推荐使用*
3.all = ['可以被*导入的内容,是一个列表']
- name 在自己本文件中 name 就是'main'
当做模块被调用的时候 name__就是文件名
5.name
1) 在本文件中__name 获取的就是'main',这个时候咱们就可以做一些测试了
2) 这个文件被当做模块导入的时候.name 就这个文件的名字
3) if name == 'main': 启动接口
print('在本文件运行')
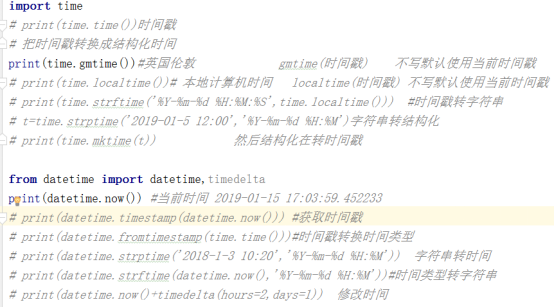
时间模块
三个时间的互相转换,这个图一定要记住


用代码来实现的相互转换
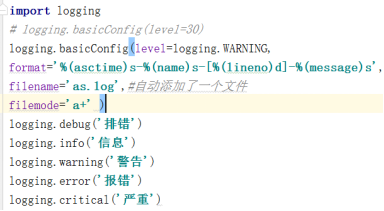
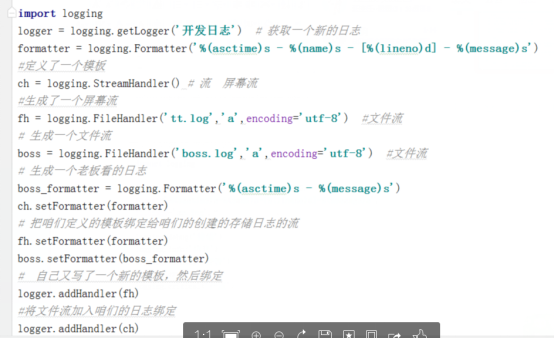
日志模块
手动版的
自动版的,用的时候直接复制粘贴就ok!
warnings模块
警告模块,用于处理警告信息
方法:
-
warnings.filterwarnings(action, message="", category=Warning, module="", lineno=0,append=False):用于控制警告行为
例:warnings.filterwarnings('ignore')
-
warnings.warn(*args,**kwargs): 用于发出警告
json模块
pickle模块
这张图一定要记熟悉

1.Json和pickle的区别
json是字符串通用的;pickle是字节,是pytho自己的
json 和 pickle 的区别
json 序列化之后得到的是字符串,仅支持字典和字符串,应用范围极广,各种编程语言几乎都能支持 json
pickle 序列化之后得到的是字节,支持 Python 中大部分对象,仅被 Python 支持
pickle 序列化不会改变字典键的数据类型;json 序列化,如果键是数字,会转为字符串
2.json中和下面一样,
dump load
import json
f=open('text','w',encoding='utf-8')
lst=[1,2,3]
s=json.dump(lst,f)
import json
f=open('text','r',encoding='utf-8')
s=json.load(f)
print(type(s))
Dumps loads
import pickle
lst=[1,2,5]
s=pickle.dumps(lst)
print(s)
lst=[1,2]
a=pickle.loads(s)
print(type(a))
dump load
import pickle
lst=[2,5,8]
f=open('text','wb')
pickle.dump(lst,f)
f=open('text','rb')
s=pickle.load(f)
print(type(s))
random随机数
chr是字母,可以做随机数
import random
print(chr(random.randrange(65,91)))
print(chr(random.randrange(97,123)))
print(chr(random.randrange(65,91)))
print(chr(random.randrange(65,91)))
小数:
Round(33.254,2) 保留2位
print(random.random()) #0-1之间的小数
print(random.uniform(1,5)) #1-5之间的小数
randint(1,36)随机整数 randrange(1,10,2)范围 随机奇数
choice(lst) 可迭代对象,只拿一个
choices(lst,k=2) 可以出现多个,但是容易重复
sample(lst,k=3) 可以出现多个,不重复
random.shuffle(lst) # 顺序打乱 洗牌
print(lst)
os 模块
操作系统做交互用的
import os
os.listdir('文件路径')列出指定目录下的所有文件和子目录,并以列表方式打印
os.makedirs(‘a/b/c’) 生成多层递归目录
os.removedirs(‘a/b/c’) 直接删除多个目录,有内容则不删除
os.mkdir() 创建单个文件
os.rmdir() 删除单个文件
os.remove() 删除文件
os.rename("oldname","newname") 重命名文件/目录
os.pardir 获取当前目录的父目录字符串名:('..')
os.getcwd() 获取当前工作目录
os.popen(‘dir’).read() 运行shell命令,获取执行结果
os.chdir() 改变当前脚本工作目录
os.environ 获取系统环境变量
os.path.join(r'D:\我的python\day12作业.py','day14') 拼接
os.path.abspath() # 返回所在文件夹的绝对路径
os.path.split(‘路径’) #路径中的内容分两个 返回一个元祖
os.path.dirname() #获取当前文件所在的文件夹路径, 获取的是os.path.split的第一个元素 同下
os.path.basename(r'D:\我的python\day12作业.py') 获取第二个元素day12作业.py
os.path.getsize() #获取文件的大小 坑 文件夹
os.path.isdir() # 判断是不是文件夹 存在目录就显示True,不存在显示false
os.path.isfile() # 判断是不是文件
os.path.isabs() # 判断是不是绝地路径 存在这个文件就显示True,不存在显示false
import os
base = os.path.abspath(__name__)
print(base) #D:\我的python\django\测试目录\ceshi\discover\son\__main__
print(os.path.dirname(base) #D:\我的python\django\测试目录\ceshi\discover\son
discover_dir = os.path.join(aa,'discover') #D:\我的python\django\测试目录\ceshi\discover
例子: 当前路径存放在:D:/我的python/day4/3.py
print(os.path.dirname('D:/我的python/day4/3.py'))
等同于 print(os.path.dirname(__file__)) #结果: D:/我的python/day4
print(os.path.dirname(os.path.dirname(os.path.dirname(__file__)))) #结果: D:/
sys.path.append(os.path.dirname(os.path.dirname(os.path.dirname(__file__)))) # 往系统环境添加路径
sys模块
sys.path python的环境变量
sys.version 查看版本
sys.argv #调用的时候 传参数获取命令行参数
sys.platform # 查看操作系统的信息 #win10
module = sys.modules[__name__]
print(module) #结果: <module '__main__' from 'D:/我的python/day4/3.py'>
例子:nc_info.py nc_disk.py 下边有一个AD类
在nc_disk.py
class AD():
def __init__(self):
pass
def foo(self):
print('asddaf')
在nc_info.py
from hg import AD
module = sys.modules[__name__] #<module '__main__' from 'D:/我的python/day4/nc_info.py'>
res_l = ['AD']
for i in res_l:
if hasattr(module,i):
print(342)
obj = getattr(module,i)()
obj.foo()
version_info的作用
主要用于返回你当前所使用的的python版本号
import sys
python_version = sys.version_info
print(sys.version_info) # sys.version_info(major=3, minor=6, micro=5, releaselevel='final', serial=0)
if python_version.major == 2:
reload(sys)
sys.setdefaultencoding('utf-8')
sys.path.append('c:\day01') 干什么?
把这个'c:\day01' 路径添加sys.path中,sys.path,
将你想直接引用的一个模块(非内置,非当前目录下),你应该将此模块的当前目录添加到sys.path中,可以直接引用了.
hashlib
hashilib是用来加密的 ,文件下载时检验文件一致性
import hashlib
# 单向 内容 -- > 哈希值
md5 = hashlib.md5(‘可以加盐’) # md5('字节')
md5.update('字节'.encode(‘utf-8’))
md5.hexdigest() # 返回一个哈希值 32位
import hashlib
# 单向 内容 -- > 哈希值
md5 = hashlib.sha1() # md5('字节')
md5.update('字节',encode(‘utf-8’))
md5.hexdigest() # 返回一个哈希值 40位
哈希值还有 sha256 sha512, 哈希值越长越安全,越长越慢
collection模块
1.namedtuple
namedtuple 命名元祖

2.counter计数
defaultdict默认字典(不常用)
3.deque
双向队列 使用list存储数据时
1)队列 FIFO 先进先出 2)栈 LOFO 后进先出
from collections import deque
q = deque(['t','a','c'])
q.append('x') #后入
q.appendleft('y') #前入
print(q) #结果 deque(['y', 't', 'a', 'c', 'x'])
2)queque 单向队列 队列 栈
import queue
q = queue.Queue() 队列容器
q.put('a')
q.put('b')
print(q.get())
print(q.get()) 结果:a b
shelve序列化
以字典形式呈现,如果回写不成功早open(writeback=True 或 flag=’r’ )
import shelve
f = shelve.open('ss.log')
f['name'] = 'ss'
print(f['name'])
shutil
高级文件模块 压缩功能
import shutil
shutil.copyfile(r‘源文件’,r’要拷贝到哪’)
1)递归的去拷贝文件夹 copytree(r‘源文件’,r’要拷贝到哪’)
2)递归的删除rmtree()
3)递归的剪切(移动)move()
4)压缩包种类,“zip”, “tar”, “bztar”,“gztar”
打包make_archive(‘压缩的文件名’,’种类’,logger=’’)
confibparser 配置文件
1)文件+字典的操作
2)要对文件操作,先读文件
3)存放开发conf目录下
4)嵌套的字典
import configparser
conf = configparser.ConfigParser() #创建一个对象
f = open('db.ini','w')
conf['DEFAULT'] = {
'session_time_out':60
}
conf['def-2'] = {
'ip':'186.33.12.05',
'port':'3306'
}
conf.write(f)
先读在修改
conf.read('db.ini')
# conf['def-2']['ip']='123' # 内存修改
# conf.write(open('db.ini','w'))
print(conf['186-DB']['ip'])
# print(conf.get('186-DB','ip'))

