

1.大数据概述
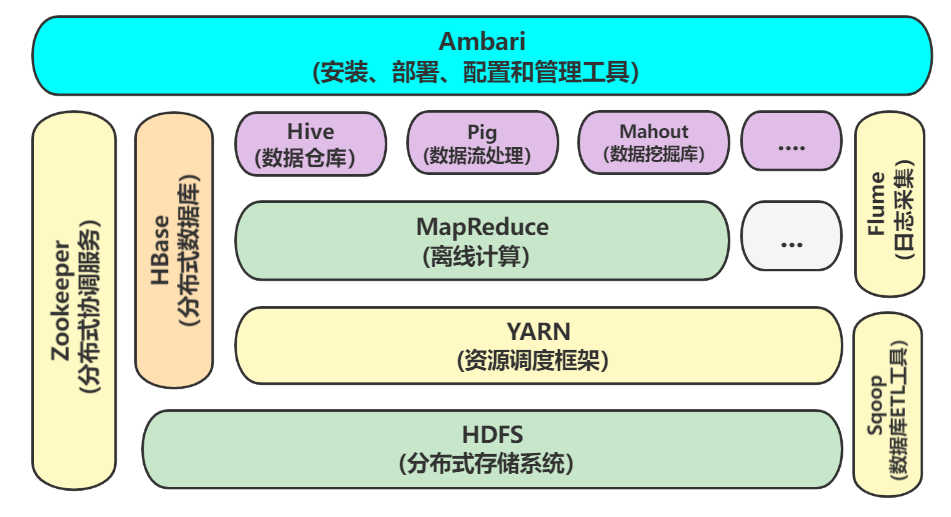
1.HDFS
Hadoop分布式文件系统HDFS是针对谷歌分布式文件系统的开源实现,两大核心组成部分之一,在廉价服务器集群中可以提供大规模分布式文件存储的能力。
并且其拥有容错能力,兼容廉价的硬件设备可以以较低的成本实现大流量和大数据量的读写。
HDFS集群包括一个名称节点和若干个数据节点。负责管理文件系统的命名空间及客户端对文件的访问、处理文件系统客户端的读/写请求。
2.hive:
一个基于Hadoop的数据仓库工具,可以用于对存储在Hadoop文件中的数据集进行数据整理、特殊查询和分析处理。让hadoop集群拥有关系型数据库的sql体验,在一台电脑安装就够用。
3.hbase:
HBase 是针对谷歌 BigTable 的开源实现,是一个高可靠、高性能、面向列、可伸缩的分布式数据库,用来存储非结构化和半结构化的松散数据。
可以让hdfs拥有海量存储功能,并且在大数据量的情况下实现秒级查询,本质还是建立在hdfs上。
4.zookeeper:
其是一个监控以及通知分布式系统。里面可以存储集群都关注的信息,
5.spark:
一种计算框架,可以独立使用。spark是用scala写的,但是不必安装sacala语言,因为sacala是运行在jvm上,所以spark依赖的是java。scala(一台安装就够)的作用仅仅是编写一些计算代码的实现
6.sqoop:
数据库etl工具,将hive和hbase与msql相互转数据
7.flume:
日志收集,如100条就存到hive里面。
对比Hadoop与Spark的优缺点。
Hadoop的优点
1、按位存储和处理数据能力的高可靠性。
2、高扩展性。
3、高效性。
4、高容错性。
Hadoop的缺点
1、不适用于低延迟数据访问。
2、不能高效存储大量小文件。
3、不支持多用户写入并任意修改文件。
Spark的优点
1、速度快
2、使用方便,支持多语言
3、丰富的操作算子
4、支持的场景多
5、生态完善、社区活跃
Spark的缺点
1、流式计算不如flink
2.延迟较高,通常大于百毫秒级别;
3.功能不如flink全。
4.资源消耗较高
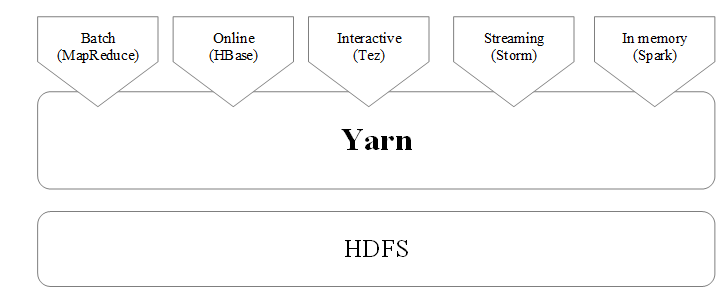
如何实现Hadoop与Spark的统一部署?
Spark可运行于YARN之上,与Hadoop进行统一部署,即“Spark on YARN”,资源管理和调度依赖YARN,分布式存储则依赖HDFS


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!