Elasticsearch介绍
Elasticsearch 是一个分布式搜索和分析引擎,通常用于处理大规模的结构化和非结构化数据。它基于开源的 Lucene 库,提供了强大、实时的搜索能力和精细的分析功能。Elasticsearch 通常与其他工具(如 Logstash、Kibana 等)一起使用,构成了著名的 ELK Stack(后来改名为 Elastic Stack)。完整的技术栈包括:
- Elasticsearch:用于数据存储、计算和搜索
- Logstash/Beats:用于数据收集
- Kibana:用于数据可视化
整套技术栈的核心就是用来存储、搜索、计算的Elasticsearc。
基础概念
文档:Elasticsearch 中最小的数据单元,类似于关系型数据库中的行。文档是以 JSON 格式存储的,包含一个或多个字段(key-value 对),每个字段可以有不同的数据类型。
索引: Elasticsearch 中存储、组织文档的地方,类似于传统关系型数据库的表。在 Elasticsearch 中,所有的数据都以 JSON 文档的形式存储在索引中。每个索引都有一个唯一的名字(类似数据库中的表名),这个名字用于引用和操作索引。
点击查看代码
#商品索引:组织文档的地方,每个{}是一个文档
{
"id": 1,
"title": "小米手机",
"price": 3499
}
{
"id": 2,
"title": "华为手机",
"price": 4999
}
{
"id": 3,
"title": "三星手机",
"price": 3999
}
Type:每个文档都必须具备字段类型,7.0之前一个索引只能有一个或者多个类型,7.0开始一个索引只能创建一个 Type :_doc,8.0 之后,Type 被完全删除,解决了多 Type 索引带来的资源浪费、字段冲突、查询效率低下等问题。
Mapping:即映射,索引中文档的字段约束信息,类似表的结构约束。
Node:相当于一个 ES 实例,多个节点构成一个集群。
Cluster:多个 ES 节点的集合,用于解决单个节点无法处理的搜索需求和数据存储需求。
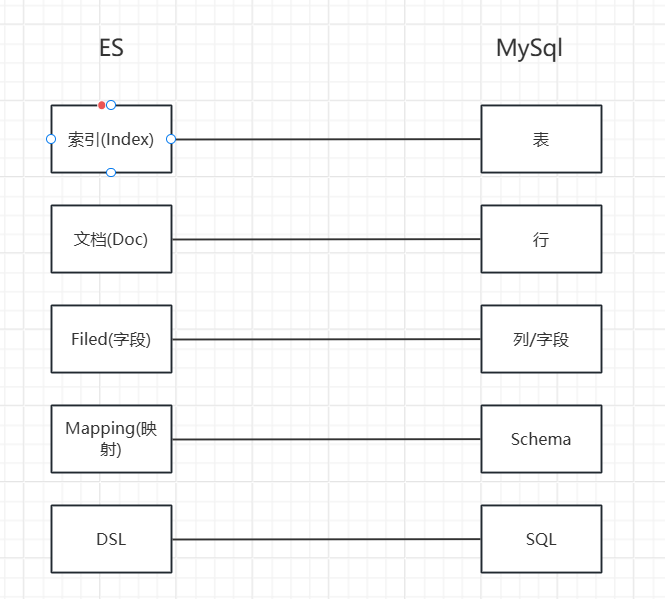
ES相关概念对比MySQL
工作原理
Elasticsearch 以其高性能的搜索和分析能力而闻名,主要得益于其底层的技术架构和索引机制。倒排索引是 Elasticsearch 的核心数据结构,它极大地提升了全文搜索的速度。它的工作原理可以类比为书的索引部分,快速定位某个词在文档中的位置。
- 首先对文档内容进行分词,ES默认英文是一个单词一个词,中文是一个汉字一个词,形成词条与文档ID对应的词条库,建立索引。
- 接着会对搜索内容进行分词,将分词后的关键词与词条库匹配,找到对应的文档ID,然后根据文档ID找到对应的文档信息。
在搜索时,用户输入某个词语,ES会直接在倒排索引中查找该词条,然后迅速定位到包含该词条的所有文档,相比与传统搜索方式需要扫描全部文档要高效的多。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号