【Unit4】UML解析器(模型化设计)-作业总结 & 【BUAA-OO】课程总结
第四单元作业总结
1.题目概述
UML类图建模与查询(8) + UML顺序图/状态图建模与查询(3+3) + 模型错误检查(9),三次迭代共23条命令
2.构架设计
一开始以为和第三单元差不多,稍微用点容器,用官方包的解析函数填填接口函数就好。后来发现还是有所区别。
原因在于,本单元模型为静态模型,所有查询指令不会对模型本身进行影响;同时课程组提供的UML解析函数不足以很好的处理各种查询功能。
思来想去,应该尽情地用空间换时间。再想想,应该用课程解读出的一摞UmlElement重新搭建一个UML的图景。这不就是将UML模型解构后再按Java重构嘛,初想很是麻烦(还得自己设计类!属于是被上单元惯坏了)。但写起来就好多了。
2.1 重建模型结构
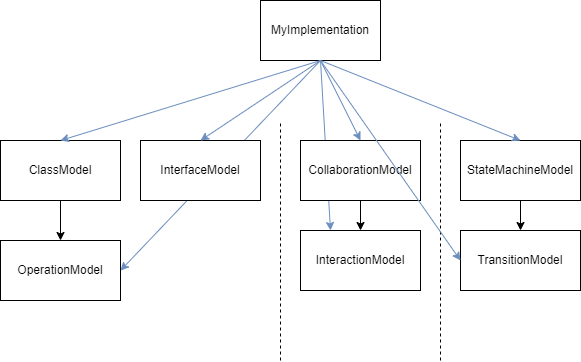
大体上只需要容器配上官方包的各类型(UmlXxx)就可以了,对于想进一步建模的类型设计了新类(见图中各XxxModel),嫌累赘没有继承官方包的类型,第三次作业用到的UmlClassOrInterface接口就直接假实现了。
类中按需设计属性,选择了应存尽存
public class MyImplementation implements UserApi {
/* ============================ ClassDiagram ============================ */
private final HashMap<String, ClassModel> name2Class = new HashMap<>();
private final HashMap<String, ClassModel> id2Class = new HashMap<>();
private final HashSet<String> dupNameClasses = new HashSet<>(); //<name>
private final HashMap<String, Integer> name2ClassAttCouplingDegree = new HashMap<>();
private final HashMap<String, InterfaceModel> id2Interface = new HashMap<>();
private final HashMap<String, ArrayList<String>> className2InterfaceList = new HashMap<>();
private final HashMap<String, OperationModel> id2Operation = new HashMap<>();
private final HashMap<String, UmlAssociationEnd> id2AsEnd = new HashMap<>();
/* ============================ StateMachine ============================ */
private final HashMap<String, StateMachineModel> name2Machine = new HashMap<>();
private final HashMap<String, StateMachineModel> id2Machine = new HashMap<>();
private final HashSet<String> dupNameMachines = new HashSet<>();
private final HashMap<String, StateMachineModel> rid2Machine = new HashMap<>();
private final HashMap<String, TransitionModel> id2Trans = new HashMap<>();
/* =========================== SequenceDiagram ========================== */
private final HashMap<String, CollaborationModel> id2Collaboration = new HashMap<>();
private final HashMap<String, InteractionModel> name2Interact = new HashMap<>();
private final HashMap<String, InteractionModel> id2Interact = new HashMap<>();
private final HashSet<String> dupNameInteracts = new HashSet<>();
/* =========================== GrammarChecker ========================== */
private boolean umlR001 = false;
private final HashSet<UmlClassOrInterface> umlR003 = new HashSet<>();
private boolean umlR005 = false;
...
}
public class StateMachineModel {
private final String name;
private final String id;
/* ======= State ======= */
private String startId = null;
private final HashSet<String> endIds = new HashSet<>();
private final HashMap<String, UmlState> name2State = new HashMap<>();
private final HashMap<String, UmlState> id2State = new HashMap<>();
private final HashSet<String> dupNameStates = new HashSet<>();
/* ======= Transition (include critical point judge) ======= */
private final HashMap<String, ArrayList<TransitionModel>> srcId2Trans = new HashMap<>();
private final HashMap<String, Boolean> name2Critical = new HashMap<>(); // <stateName, bool>
private boolean globalCritical;
private HashSet<String> hitEndMark;
...
}
2.2 数据读入
由于模型的建构有数据依赖采用了多次循环读取的方式。理论上应该统一引用,使用过不再需要的内容扔掉;或者第一轮读取时就分门别类的存放。不过看在数据条数很少(300-),就直接循环了4轮。
public MyImplementation(UmlElement... elements) {
storeArterialEntity(elements);
completeEntity(elements); // after: UMLOperation has its complete information
storeRelations(elements);
name2Machine.values().forEach(StateMachineModel::setGlobalCritical);
}
- storeArterialEntity(): 包含一轮遍历,对独立性高的主干实体进行存储(UmlClass、UmlInterface、UmlOperation、UmlAssociationEnd;UmlCollaboration、UmlInteraction;UmlStateMachine)
- completeEntity(): 包含两轮遍历(可能没有好好规划),目的在于补全实体。首轮是有些许特殊处理的类型(UmlParameter、UmlRegion),次轮是向已有顶层主干实体中加入次级实体(UmlAssociation;UmlPseudoState、UmlFinalState、UmlState、UmlTransition;UmlInteraction、UmlLifeline、UmlEndpoint)
- storeRelations(): 包含一轮遍历,主要将各实体的关系按需存入相应的实体或位置中,以便查询(UmlAttribute、UmlOperation、UmlGeneralization、UmlInterfaceGeneralization;UmlEvent;UmlMessage)
最后一行是处理为了某命令,希望在模型建完后更新一次全体状态机的某值
2.3 继承实现相关查询命令
还是少不了类似:查询所有继承的类/实现的接口、检查是否循环继承/重复实现等。看在复杂度无忧的情况下,就直接dfs好了。目前习惯写的dfs都会传一个记录容器或全局设一个更迭容器,例如:
private void dfs4Interface(String stepIn, ArrayList<String> path) {
int index = path.indexOf(stepIn);
if (index >= 0) {
for (int i = index; i < path.size(); ++i) {
umlR003.add(id2Interface.get(path.get(i)));
}
return;
}
path.add(stepIn);
for (String nextId: id2Interface.get(stepIn).getFatherInterfaceIds()) {
dfs4Interface(nextId, path);
}
path.remove(stepIn);
}
不知道有没有更好的写法。
2.4 关于名字重复
处理方式大体上形成模式了,用了三个容器:
HashMap<String, XXXModel> id2XXX: 用id标识,作为一切操作的使用容器(不管重不重名)HashMap<String, XXXModel> name2XXX: 用name标识,用于作是否重名的依据HashSet<String> dupNameXXXs: 记录所有因name2XXX而找到的重名XXX,可用于各类需求命令
2.5 关于缩行
写完第三次作业后,MyImplement达到了580行,超过了一个类<500行的规范。所以进行了一些缩行操作:
- 觉察出类图、状态图、顺序图中相关命令都有对“找不到名字/名字重复”的异常抛出处理,将它们提出合并成三个xxxNameExceptionThrower()方法,在各命令函数中调用。
- 删除了所有自动生成的@Overide编译注释
- 感觉这第一点的三个方法仍很独立,干脆独立出一个专门抛名字异常的类叫做NameExceptionThrower
public class NameExceptionThrower {
public static void detectClassNameException(String className,
HashMap<String, ClassModel> name2Class,
HashSet<String> dupNameClasses)
throws ClassNotFoundException, ClassDuplicatedException {
if (!name2Class.containsKey(className)) {
throw new ClassNotFoundException(className);
} else if (dupNameClasses.contains(className)) {
throw new ClassDuplicatedException(className);
}
}
public static void detectInteractNameException(String interactionName,
HashMap<String, InteractionModel> name2Interact,
HashSet<String> dupNameInteracts)
throws InteractionNotFoundException, InteractionDuplicatedException {
if (!name2Interact.containsKey(interactionName)) {
throw new InteractionNotFoundException(interactionName);
} else if (dupNameInteracts.contains(interactionName)) {
throw new InteractionDuplicatedException(interactionName);
}
}
public static void detectMachineNameException(String stateMachineName,
HashMap<String, StateMachineModel> name2Machine,
HashSet<String> dupNameMachines)
throws StateMachineNotFoundException, StateMachineDuplicatedException {
if (!name2Machine.containsKey(stateMachineName)) {
throw new StateMachineNotFoundException(stateMachineName);
} else if (dupNameMachines.contains(stateMachineName)) {
throw new StateMachineDuplicatedException(stateMachineName);
}
}
}
现在再想想,如果还要继续肢解,就按类图、顺序图、状态图三个不太相关的数据和命令独立出来。
构架类图:

3.测试与记录
- 第一次:进行了数据生成+猛烈的对拍,找到了很多同学的bug;
- 第二次:想用JUnit4,但发现好像构造MyImplementTest有点困难像是作茧自缚,应该到官方包某处去构造Test,但官方包稍微读了下一知半解就搁置了,最后就按自己的想法手动构造了一个整合数据,还有找出一个HashMap的NullPointException的情况
- 第三次:认为没啥好测的,就自己构造了下r002、r003、r004、r009的数据,大致都没问题;结果问题出在r001,某片段文字理解反了导致了灯下黑的错误,喜提81.81
这个单元自测时最容易出的bug是HashMap的NullPointException,就是get失败得到了null了,还继续对它使用既定的方法。
ps.一直记不清聚合、组合,还有相应的图形标记,放一张别人的图

课程总结
1.关于构架设计和OO方法
第一单元
架构设计:刚上手肯定称不上舒服,是Experiment1中的Parser和Lexer类给了我思路,开始了构架设计之旅。之后该单元的设计主旨转到了“预处理”-“解析”两者的权衡上,随着解析的比重上升,构架的清晰度和可拓展性也逐步上升。
OO方法:继承并不是这一单元的主要方法,而应是组合或者聚合关系(不同因子的类嵌套聚合);类的主体性逐渐分明
第二单元
构架设计:同样是做了本单元的Experiment后,采取了相同的生产者-消费者模式。当电梯增多/横向运输出现后,虽听得自由竞争的说法,但并未想清,情急下便沿用生产者-消费者的调度架构多套了几层。但调度算法以其没有最优解而难以抉择,没有了第一单元明确的优化方向,让权衡更加困难,再辅以各种bug和较难的测试方法,总体效果一般。第一/三次作业性能上似乎不错,但都由于存在未查出的bug而或小或大的崩盘。
OO方法:第三次作业的迭代中,终于好好体会到了继承多态的美妙之处;认识了一些面向对象的设计模式:生产者消费者模式,流水线模式,单例模式;在多线程编程方面,逐渐掌握了synchronize的使用,不过没有运用重入锁reentrantlock
第三单元
构架设计:几乎没有什么构架设计,就是按接口写函数。由于构建命令和查询命令的缘故,以部分数据结构的空间换时间,达到降低复杂度的效果。同时也体会到了规格化设计谓何。
OO方法:体验了在java中相关算法的实现
第四单元
架构设计:重新将UML图的结构在java中还原,取所需而用,设计上更加自然了些,也用包来视觉优化了代码结构。这便是UML自动解析转换的目的所在吧
2.关于测试
一贯来沿用的主要测试手段便是python生成数据+数据检验(函数/自行检验,对拍)。肉眼debug得看心情,似乎写完了就不太愿意细细回看一遍了。后来接触了JUnit4单元测试,只是玩过,但没有成品的测试
第一单元开头新鲜感强烈,亲手从数据生成到数据检验搭过简单的测评姬,接触了subprocess、xeger、random等模块;逐渐开始犯懒,觉得有些数据生成繁琐,测试也开始偷懒,用用别人的数据生成模块啊,自己随手造几个数据看看啊什么的,后两次作业都有bug未查出。
第二单元开始被当头棒喝,又开始重视测试,然而写了数据生成模块后觉得检验挺难写,加上时间精力不够,也作罢了。第一次作业和第三次作业的bug四两拨千斤,令人心疼而无奈。
第三单元时强调了单元测试,其实这时候是最适合尝试JUnit的;不过最初的python测评逻辑也很顺,况且群友提供了初版(第二单元得了超大教训想着拉个群交流交流debug事项)测评姬,便修修补补用了一整个单元,每周六猛力对拍。所以强测互测结果不错,但其实过程除了改测评姬部分,都很无聊,也没有太多能力上的提升。想想要是搞一套ci会不会很有意思,但知识也不足。
关于JUnit,其实有时编写时还是跳不开写代码的主主观思路,自己怎么理解的就是怎么测的,这样会有灯下黑的认知错误无法查出;从头的自动化测试就能规避这点
第四单元的第一次作业同上一单元,第二第三次时又变回手造数据了,其实到和单元测试没啥区别了。但发觉JUnit写不来,类中的容器太多太杂,直接写MyImplementTest吃不消也没意义,就又作罢了。
总的没有太多认知差,但态度端正了一些。
3.关于收获
码代码的能力提升是最显著的。遥想数据结构那会儿,几十行代码都能写出bug还de不出考试干着急,到最近几次作业写下来基本上就直接能跑,bug也不再是些莫名其妙的代码缺陷,可以更多的关注构架设计本身。一些算法的实现似乎挺流畅的,之前还没啥概念。(也有Idea的功劳)
其次就是面向对象本身。真要说了解了面向对象编程,未必。基本的概念知识是了解了,究竟有没有构架设计能力呢,不好说,要继续实践才行。读代码和理解能力还是偏弱了,线上实验有两次没来得及。很多设计模式没有好好实践过,更多OO知识没有接触过,应该在工程实践中进一步理解。
曾经觉得OO又难又神圣,写起来后又觉得不过如此,再往后觉察到其背后浓缩的庞大工业体系而叹服,这种看山是山和看山不是山的变换,甚是奇妙。冰山一角,具体而微。
4.关于建议
- 后两个单元的课程似乎是略显空泛,没听进去太多,作业也没用上就不管了;设计模式的讲解挺少的,希望可以专门讲讲并配上相应的练习。
- 第二个单元的中测太弱不是好事,测试方式和测评姬的搭建希望提供台阶
- “第四单元手册”可以好好调整调整,挺粗糙的;第三单元作业的重心似乎和规格化有所片偏差,希望多见识实际工程中规格化的应用。

