【P5】Verilog搭建流水线MIPS-CPU
课下
Thinking_Log
1.为何不允许直接转发功能部件的输出
直接转发会使一些组合逻辑部件增加新的长短不一的操作延迟,不利于计算设置流水线是时钟频率(保证流水线吞吐量?)。
2.jal中将NPC+4/8存入$ra的操作为何需流过全级
不要因为beq指令提前得到结果完成跳转的事情乱了方寸。jal虽然D级即可出NPC地址,但若D级后立即进入W级准备写入,且不说毫无增益,原先还在W级的指令不就被覆盖了嘛!流水线将指令按级传输执行的基本概念都忘掉了!
Technique_Log
1.向量部分选择
可以选择向量的连续几位输出
A[base_expr +: width_expr] //positive offset
B[base_expr -: width_expr] //negative offset
Arr[x -: 2] //意味着取Arr中x x-1这两位
其中base_expr可以是变量,而width_expr必须是常量。
+:表示由base_expr向上增长width_expr位
-: 表示由base_expr向下递减width_expr位
Bug_Log
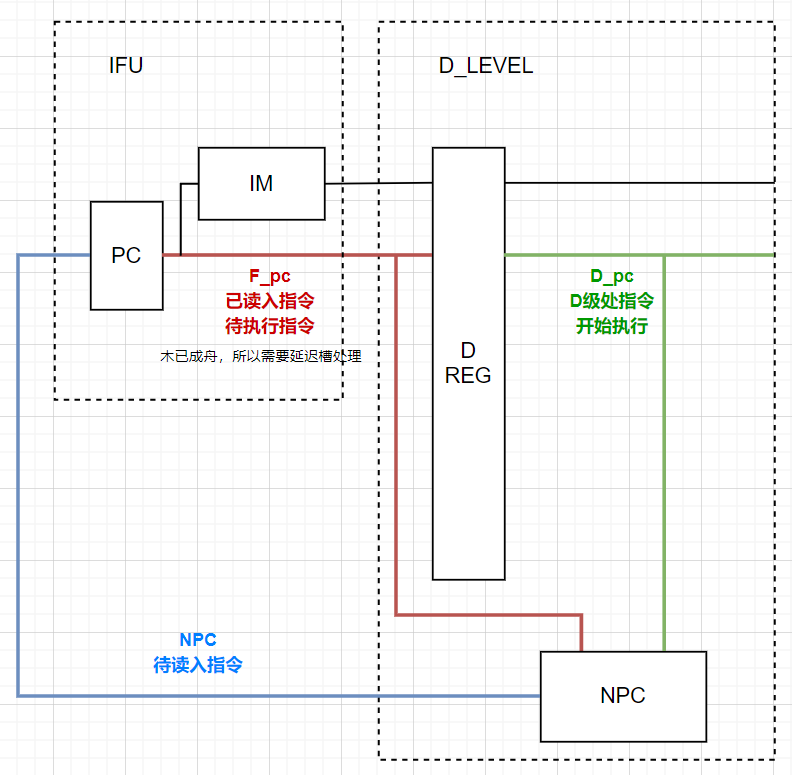
1.NPC信号脱节——F、D寄存器影响
D_pc + 8 并不可以替代 F_pc + 4,在跳转指令时暴露问题
assign NPC = (NPCOp == `NPC_order ) ? PC_F + 4 : //易错,增量是相对于F级的PC而言的;且PC + 8在跳转时无法替代。画图可理解
(NPCOp == `NPC_branch) ? PC_b :
(NPCOp == `NPC_jump ) ? PC_j :
(NPCOp == `NPC_reg ) ? RA :
PC_F + 4 ;
2.相似语句书写变量修改灯下黑
这个错误仅在关于$0的内部转发中显现,十分的隐秘,且粗粗扫一眼,还以为内部转发完全没问题。中测最后一个点WA在这,第12周第1次P5临考前靠同学de出
assign RD1 = (A3 == A1 && RFWr == 1 && A1 != 0) ? WD : grf[A1] ; //D级内部转发
assign RD2 = (A3 == A2 && RFWr == 1 && A2 != 0) ? WD : grf[A2] ; //giao,误写
//上下形式相似,书写时容易忘记修改变量名,例如GRF内部转发第二行 A2 != 0 误抄成A1
3.E级输出的V2信号错误——对T_use的误解
第1次P5课上添加swc计算指令暴露,写DM数据错误
lw $4, 0($0)
sw $4, 0x2000($0)
sw $4, 0x2004($0)
sw $4, 0x2008($0)
sw $4, 0x200c($0)
被转发的数据都是将要写入但还没写入GRF的数据。因此是对错误的GPR[rs] GPR[rt]值进行修正,这两个寄存器值的数据路径分别是
GPR[rs]:D_GRF_RD1 -> E_reg_V1GPR[rt]:D_GRF_RD2 -> E_reg_V2 -> M_reg_V2
当某指令到达某一级,必须使用指定寄存器值时,该级路径上的内容必须正确(接收转发),这也是T_use计算截止的地方。若能达成上述目标(T_use >= T_new),则T_use截止处前的内容无需关心,但这不代表此前转发的值没用。
- T_use = T_new时,代表当前转发修正堪堪在要使用时到来
- T_use > T_new时,代表转发修正在使用前已经到来,此后路径上的内容为正确寄存器值
此前我的设计其实无意间都符合了这些想法。但在E级出现了疏漏。E_reg_V2是从D级流至E的值,若要留到M级,需经过M级、W级转发数据的修正。
我将修正后的寄存器值仅作为ALU的输入,而直接将未修正的数据传到下一级,因而倘若数据在M级得不到修正,便会使用错误的寄存器值。sw指令用到了M_reg_v2(T_use(rt) = 2),使得问题得以暴露。
| time | D | E | M | W |
|---|---|---|---|---|
| 1 | lw $4, 0($0) |
nop |
nop |
nop |
| 2 | sw $4, 0x2000($0) |
lw $4, 0($0) |
nop |
nop |
| 3 | sw $4, 0x2004($0) |
sw $4, 0x2000($0) |
lw $4, 0($0) |
nop |
| 4 | sw $4, 0x2008($0) |
sw $4, 0x2004($0) |
sw $4, 0x2000($0) | lw $4, 0($0) |
| 5 | sw $4, 0x200c($0) |
sw $4, 0x2008($0) |
sw $4, 0x2004($0) | sw $4, 0x2000($0) |
time = 4时,lw指令产生了可转发的数据,便向前转发修正了D、E、M级出GPR[rt]的寄存器值(D级靠内部转发);time = 5时,lw指令完成了寄存器写入,其后D级数据便正确,E、M、W级应为此前经过修正也正确,所以行为正确。然而我将E级处对sw $4, 0x2004($0)的GPR[rt]修正丢失,且到M级时已无法得到修正,因而产生了lw $4, 0($0)生效前的值。
4.Tuse缺省值误判阻塞的错误规避——导致超周期数限制
第3次P5课上添加taddu计算指令暴露,空输出:
...got nothing when we expected @00003f7c: $29 <= 00000108。算是tle吧
对于不需要读寄存器的指令(Tuse不存在)来说,Tuse的缺省值应设为最大值(比如3),否则会和Tuse = 0的指令混合,产生不必要的阻塞从而超周期数。
本人写的时候缺省值设为0,但也并不是没考虑过这种情况。但认为仅加上“是否为合法转发”(M级rt的stall:D_instr[20:16] && (D_instr[20:16] == E_RFA3) && E_RFWr)的判断就能规避,属实疏忽了很多情况。例如
ori $t0, $t0, 0x1234
lw $t0, 0($0)
lw $t0, 0($0)
lw $t0, 0($0)
哎谁又会想道bug出在周期数上呢?当时都绝望死了,只能感谢讨论区hxd。
5.CMP模块信号的流水——适配BGEZAL组合类指令
本身不是bug,但课上再加流水确实很麻烦因而易错。对于选择性link而言,最好将控制信号流水,因为本人使用分布式译码,所以将D级的CMP比较信号流水,每一级去解码使用。
跳转可分为:
- BXXZAL : 无条件link
- BXXZALC: 条件link (conditionally)(mips中的bgezal其实是这一种)
- BXXZALR: link到指定寄存器 (register)
- BXXZALL: 清空延迟槽(likely)
算是对流水有了进一步理解。

