

Logstash grok的使用
常用的一些选项
logstash中grok正则过滤的功能十分强大,如果用好了grok插件的话,基本可以处理99.99%的消息。官方文档上有一些例子,以及给了一个github的地址,上面有很多grok的内置变量,合理的使用,可以让我们的正则表达式既强大又简洁。
基本大部分的插件都可以通过上面的示例去找到,下面我列举一些,我比较经常用到的
-
时间
# IOS8601格式的时间 2021-06-28T14:28:57+08:00 2021-06-28 14:28:57+08:00 TIMESTAMP_ISO8601 %{YEAR}-%{MONTHNUM}-%{MONTHDAY}[T ]%{HOUR}:?%{MINUTE}(?::?%{SECOND})?%{ISO8601_TIMEZONE}? # 28/Jun/2021:14:34:29 +0800 HTTPDATE %{MONTHDAY}/%{MONTH}/%{YEAR}:%{TIME} %{INT} # 一般上述的两种时间格式比较多 # 06/28/2021 06-28-2021 DATE_US %{MONTHNUM}[/-]%{MONTHDAY}[/-]%{YEAR} # 28/06/2021 28.06.2021 28-06-2021 DATE_EU %{MONTHDAY}[./-]%{MONTHNUM}[./-]%{YEAR} # 看了上面内置的一些之后,其实如果发现跟我们的日志格式不一样,又不想写很复杂的正则的话,我们可以自己通过这些小的变量去组装,类似 # 2021/06/28 14:45:42 # (?<timestamp>%{YEAR}/%{MONTHNUM}/%{MONTHDAY} %{TIME}) -
ip
IPV6 ((([0-9A-Fa-f]{1,4}:){7}([0-9A-Fa-f]{1,4}|:))|(([0-9A-Fa-f]{1,4}:){6}(:[0-9A-Fa-f]{1,4}|((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3})|:))|(([0-9A-Fa-f]{1,4}:){5}(((:[0-9A-Fa-f]{1,4}){1,2})|:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3})|:))|(([0-9A-Fa-f]{1,4}:){4}(((:[0-9A-Fa-f]{1,4}){1,3})|((:[0-9A-Fa-f]{1,4})?:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){3}(((:[0-9A-Fa-f]{1,4}){1,4})|((:[0-9A-Fa-f]{1,4}){0,2}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){2}(((:[0-9A-Fa-f]{1,4}){1,5})|((:[0-9A-Fa-f]{1,4}){0,3}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){1}(((:[0-9A-Fa-f]{1,4}){1,6})|((:[0-9A-Fa-f]{1,4}){0,4}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(:(((:[0-9A-Fa-f]{1,4}){1,7})|((:[0-9A-Fa-f]{1,4}){0,5}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:)))(%.+)? IPV4 (?<![0-9])(?:(?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5])[.](?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5])[.](?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5])[.](?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5]))(?![0-9]) IP (?:%{IPV6}|%{IPV4})日志等级
# [error] LOGLEVEL ([Aa]lert|ALERT|[Tt]race|TRACE|[Dd]ebug|DEBUG|[Nn]otice|NOTICE|[Ii]nfo?(?:rmation)?|INFO?(?:RMATION)?|[Ww]arn?(?:ing)?|WARN?(?:ING)?|[Ee]rr?(?:or)?|ERR?(?:OR)?|[Cc]rit?(?:ical)?|CRIT?(?:ICAL)?|[Ff]atal|FATAL|[Ss]evere|SEVERE|EMERG(?:ENCY)?|[Ee]merg(?:ency)?)数字
# 1.1 NUMBER (?:%{BASE10NUM}) # 1 INT (?:[+-]?(?:[0-9]+)) NUMBER与INT的区别在于,INT只能匹配整数,而NUMBER可以匹配小数字符串
# GET WORD \b\w+\buri
# /abc/dd URIPATH (?:/[A-Za-z0-9$.+!*'(){},~:;=@#%&_\-]*)+ # http://192.168.0.55:7821/kxqp/websocket URI %{URIPROTO}://(?:%{USER}(?::[^@]*)?@)?(?:%{URIHOST})?(?:%{URIPATH}(?:\?%{URIQUERY})?)?其他
# 有的时候已经匹配了自己想要的所有的数据了,后面的的部分想要全部赋值给一个变量,或者全部丢弃 GREEDYDATA .* DATA .*?e.g. 简单示例
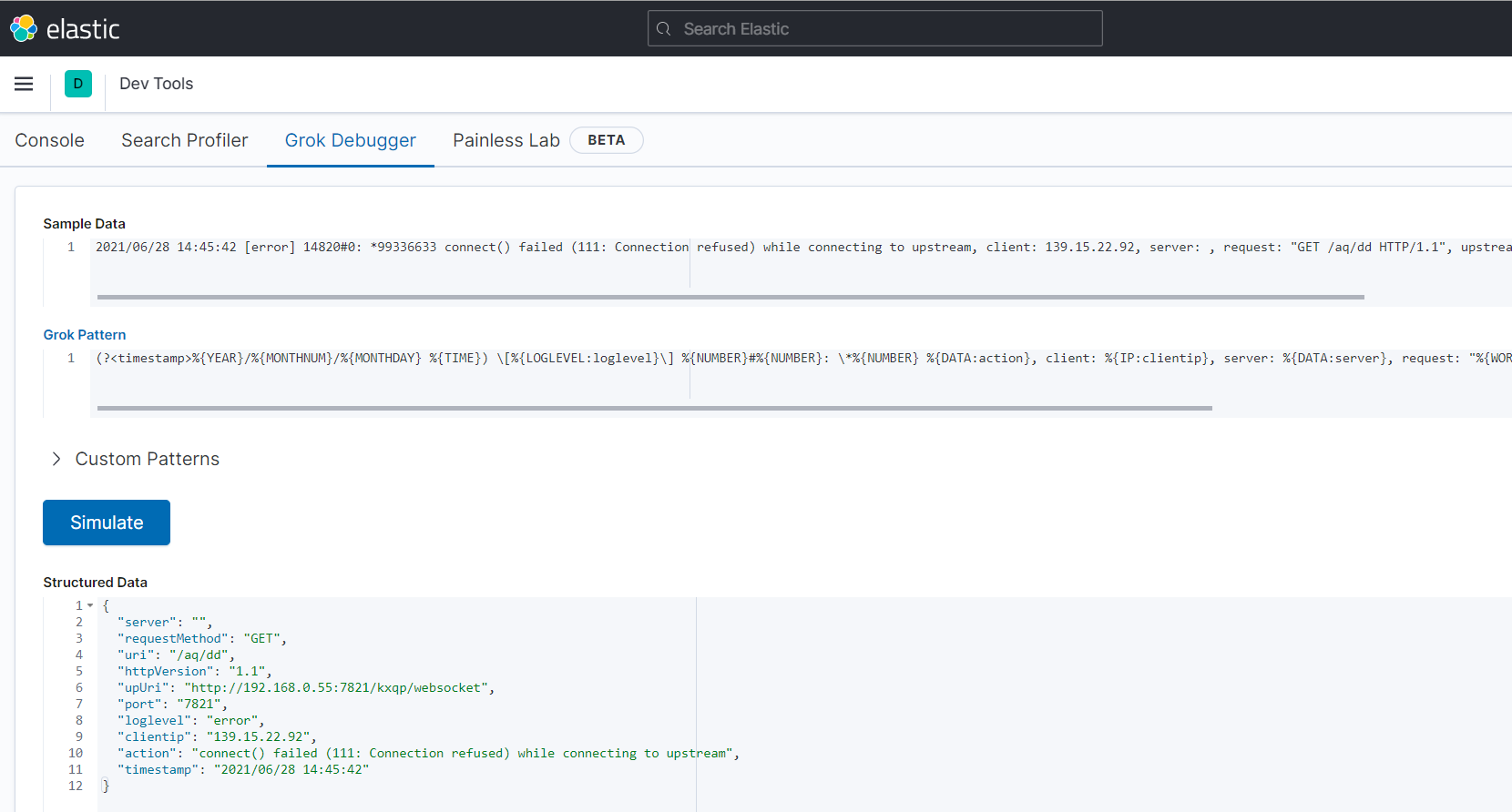
# 2021/06/28 14:45:42 [error] 14820#0: *99336633 connect() failed (111: Connection refused) while connecting to upstream, client: 139.15.22.92, server: , request: "GET /aq/dd HTTP/1.1", upstream: "http://192.168.0.55:7821/kxqp/websocket", host: "abc.dd.game.cn:8899" (?<timestamp>%{YEAR}/%{MONTHNUM}/%{MONTHDAY} %{TIME}) \[%{LOGLEVEL:loglevel}\] %{NUMBER}#%{NUMBER}: \*%{NUMBER} %{DATA:action}, client: %{IP:clientip}, server: %{DATA:server}, request: "%{WORD:requestMethod} %{URIPATH:uri} HTTP/%{NUMBER:httpVersion}", (upstream: "%{URI:upUri}", )?host: %{GREEDYDATA}*需要\转义,否则会当作正则中的*
示例我匹配的是nginx的错误日志,你可以自己试一试是否能匹配成功,upstream在你使用的时候才会出现,所以这里通过()?表示出现0或者1次
通过kibana的grok debugger工具可以验证正则的正确性

 浙公网安备 33010602011771号
浙公网安备 33010602011771号