
五分钟学后端技术:如何学习Java工程师必知必会的消息队列
原创声明
本文作者:黄小斜
转载请务必在文章开头注明出处和作者。
什么是消息队列
“RabbitMQ?”“Kafka?”“RocketMQ?”...在日常学习与开发过程中,我们常常听到消息队列这个关键词,可能你是熟练使用消息队列的老手,又或者你是不懂消息队列的新手,不论你了不了解消息队列,本文都将带你搞懂消息队列的一些基本理论。如果你是老手,你可能从本文学到你之前不曾注意的一些关于消息队列的重要概念,如果你是新手,相信本文将是你打开消息队列大门的一板砖。
根据百度百科的说法,“消息队列”是在消息的传输过程中保存消息的容器。消息队列管理器在将消息从它的源中继到它的目标时充当中间人。队列的主要目的是提供路由并保证消息的传递;如果发送消息时接收者不可用,消息队列会保留消息,直到可以成功地传递它。`
为什么要使用消息队列
我觉得使用消息队列主要有两点好处:
1.通过异步处理提高系统性能(削峰、减少响应所需时间);
2.降低系统耦合性。如果在面试的时候你被面试官问到这个问题的话,一般情况是你在你的简历上涉及到消息队列这方面的内容,这个时候推荐你结合你自己的项目来回答。
《大型网站技术架构》第四章和第七章均有提到消息队列对应用性能及扩展性的提升。
在我平时的日常工作中,用到消息队列的场景可不少,比如,我有一个定时任务需要在A应用每天7点开始调度,那么定时任务系统如何告诉这个A应用呢,一种办法是直接调用A应用的RPC服务,但是,定时任务系统不可能去记录那么多应用的RPC服务,所以如果换成消息,就大大降低了复杂度。
还有一种常见使用消息队列的场景,那就是把一些不需要及时处理的RPC调用改成消息,比如最典型的电商下单,一定是实时性要求很高的,但是,有一些消息会在用户下单后进行异步的发送,比如用户对商品的评价,用户的退款请求,这些请求不需要被实时地进行处理,完全可以异步化处理,这个时候使用消息队列就是再好不过的选择了,消息队列会帮你存储这些待处理的消息,并且等应用负载较低的时候再分发给应用处理,或者是等待应用主动向消息队列获取消息。
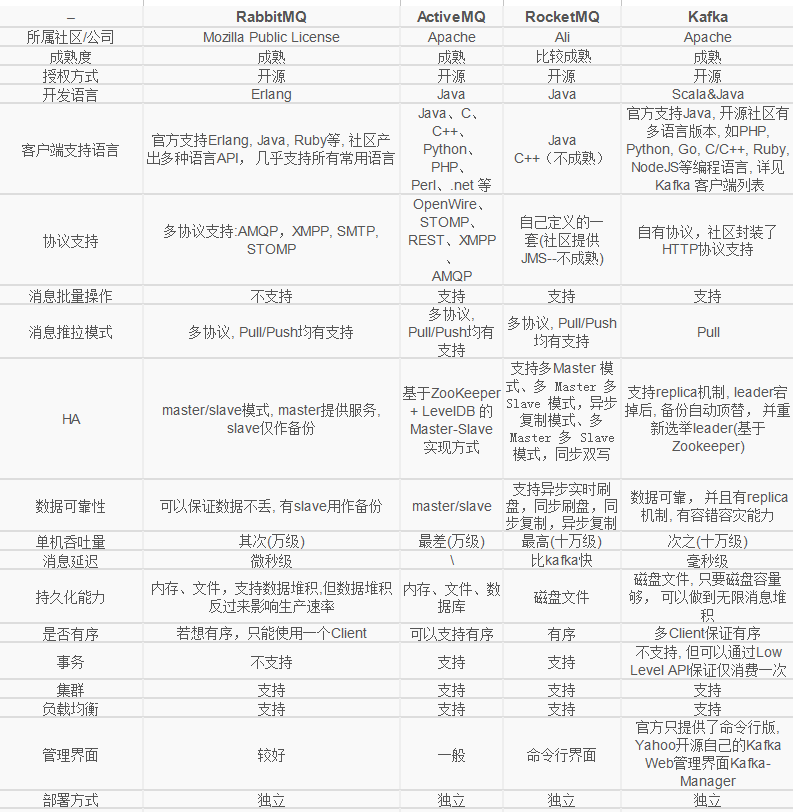
常用的消息队列
我们可以把消息队列比作是一个存放消息的容器,当我们需要使用消息的时候可以取出消息供自己使用。消息队列是分布式系统中重要的组件,使用消息队列主要是为了通过异步处理提高系统性能和削峰、降低系统耦合性。目前使用较多的消息队列有ActiveMQ,RabbitMQ,Kafka,RocketMQ。
当然,在我们公司内部用的大多都是自研的消息队列产品,一方面是因为需要适配金融级分布式场景,另一方面自研的中间件有专门的的团队维护,出了什么问题才能及时处理和修复。
下面我们就一起来看看这些开源的消息队列是怎么设计的,各有什么优缺点呢。
RabbitMQ
RabbitMQ 2007年发布,是一个在AMQP(高级消息队列协议)基础上完成的,可复用的企业消息系统,是当前最主流的消息中间件之一。
主要特性:
- 可靠性: 提供了多种技术可以让你在性能和可靠性之间进行权衡。这些技术包括持久性机制、投递确认、发布者证实和高可用性机制;
- 灵活的路由: 消息在到达队列前是通过交换机进行路由的。RabbitMQ为典型的路由逻辑提供了多种内置交换机类型。如果你有更复杂的路由需求,可以将这些交换机组合起来使用,你甚至可以实现自己的交换机类型,并且当做RabbitMQ的插件来使用;
- 消息集群:在相同局域网中的多个RabbitMQ服务器可以聚合在一起,作为一个独立的逻辑代理来使用;
- 队列高可用:队列可以在集群中的机器上进行镜像,以确保在硬件问题下还保证消息安全;
- 多种协议的支持:支持多种消息队列协议;
- 服务器端用Erlang语言编写,支持只要是你能想到的所有编程语言;
- 管理界面: RabbitMQ有一个易用的用户界面,使得用户可以监控和管理消息Broker的许多方面;
- 跟踪机制:如果消息异常,RabbitMQ提供消息跟踪机制,使用者可以找出发生了什么;
- 插件机制:提供了许多插件,来从多方面进行扩展,也可以编写自己的插件;
优点:
- 由于erlang语言的特性,mq 性能较好,高并发;
- 健壮、稳定、易用、跨平台、支持多种语言、文档齐全;
- 有消息确认机制和持久化机制,可靠性高;
- 高度可定制的路由;
- 管理界面较丰富,在互联网公司也有较大规模的应用;
- 社区活跃度高;
缺点:
- 尽管结合erlang语言本身的并发优势,性能较好,但是不利于做二次开发和维护;
- 实现了代理架构,意味着消息在发送到客户端之前可以在中央节点上排队。此特性使得RabbitMQ易于使用和部署,但是使得其运行速度较慢,因为中央节点增加了延迟,消息封装后也比较大;
- 需要学习比较复杂的接口和协议,学习和维护成本较高;
ActiveMQ
ActiveMQ是由Apache出品,ActiveMQ 是一个完全支持JMS1.1和J2EE 1.4规范的 JMS Provider实现。它非常快速,支持多种语言的客户端和协议,而且可以非常容易的嵌入到企业的应用环境中,并有许多高级功能。
主要特性:
- 服从JMS 规范:JMS 规范提供了良好的标准和保证,包括:同步或异步的消息分发,一次和仅一次的消息分发,消息接收和订阅等等。遵从 JMS 规范的好处在于,不论使用什么 JMS 实现提供者,这些基础特性都是可用的;
- 连接性:ActiveMQ 提供了广泛的连接选项,支持的协议有:HTTP/S,IP 多播,SSL,STOMP,TCP,UDP,XMPP等等。对众多协议的支持让 ActiveMQ 拥有了很好的灵活性。
- 支持的协议种类多:OpenWire、STOMP、REST、XMPP、AMQP ;
- 持久化插件和安全插件:ActiveMQ 提供了多种持久化选择。而且,ActiveMQ 的安全性也可以完全依据用户需求进行自定义鉴权和授权;
- 支持的客户端语言种类多:除了 Java 之外,还有:C/C++,.NET,Perl,PHP,Python,Ruby;
- 代理集群:多个 ActiveMQ 代理可以组成一个集群来提供服务;
- 异常简单的管理:ActiveMQ 是以开发者思维被设计的。所以,它并不需要专门的管理员,因为它提供了简单又使用的管理特性。有很多中方法可以监控 ActiveMQ 不同层面的数据,包括使用在 JConsole 或者 ActiveMQ 的Web Console 中使用 JMX,通过处理 JMX 的告警消息,通过使用命令行脚本,甚至可以通过监控各种类型的日志。
优点:
- 跨平台(JAVA编写与平台无关有,ActiveMQ几乎可以运行在任何的JVM上)
- 可以用JDBC:可以将数据持久化到数据库。虽然使用JDBC会降低ActiveMQ的性能,但是数据库一直都是开发人员最熟悉的存储介质。将消息存到数据库,看得见摸得着。而且公司有专门的DBA去对数据库进行调优,主从分离;
- 支持JMS :支持JMS的统一接口;
- 支持自动重连;
- 有安全机制:支持基于shiro,jaas等多种安全配置机制,可以对Queue/Topic进行认证和授权。
- 监控完善:拥有完善的监控,包括Web Console,JMX,Shell命令行,Jolokia的REST API;
- 界面友善:提供的Web Console可以满足大部分情况,还有很多第三方的组件可以使用,如hawtio;
缺点:
- 区活跃度不及RabbitMQ高;
- 根据其他用户反馈,会出莫名其妙的问题,会丢失消息;
- 目前重心放到activemq6.0产品-apollo,对5.x的维护较少;
- 不适合用于上千个队列的应用场景;
RocketMQ
RocketMQ出自 阿里公司的开源产品,用 Java 语言实现,在设计时参考了 Kafka,并做出了自己的一些改进,消息可靠性上比 Kafka 更好。RocketMQ在阿里集团被广泛应用在订单,交易,充值,流计算,消息推送,日志流式处理,binglog分发等场景。
主要特性:
- 是一个队列模型的消息中间件,具有高性能、高可靠、高实时、分布式特点;
- Producer、Consumer、队列都可以分布式;
- Producer向一些队列轮流发送消息,队列集合称为Topic,Consumer如果做广播消费,则一个consumer实例消费这个Topic对应的所有队列,如果做集群消费,则多个Consumer实例平均消费这个topic对应的队列集合;
- 能够保证严格的消息顺序;
- 提供丰富的消息拉取模式;
- 高效的订阅者水平扩展能力;
- 实时的消息订阅机制;
- 亿级消息堆积能力;
- 较少的依赖;
优点:
- 单机支持 1 万以上持久化队列
- RocketMQ 的所有消息都是持久化的,先写入系统 PAGECACHE,然后刷盘,可以保证内存与磁盘都有一份数据,
访问时,直接从内存读取。
- 模型简单,接口易用(JMS 的接口很多场合并不太实用);
- 性能非常好,可以大量堆积消息在broker中;
- 支持多种消费,包括集群消费、广播消费等。
- 各个环节分布式扩展设计,主从HA;
- 开发度较活跃,版本更新很快。
缺点:
支持的客户端语言不多,目前是java及c++,其中c++不成熟;
RocketMQ社区关注度及成熟度也不及前两者;
没有web管理界面,提供了一个CLI(命令行界面)管理工具带来查询、管理和诊断各种问题;
没有在 mq 核心中去实现JMS等接口;
Kafka
Apache Kafka是一个分布式消息发布订阅系统。它最初由LinkedIn公司基于独特的设计实现为一个分布式的提交日志系统( a distributed commit log),,之后成为Apache项目的一部分。Kafka系统快速、可扩展并且可持久化。它的分区特性,可复制和可容错都是其不错的特性。
主要特性:
- 快速持久化,可以在O(1)的系统开销下进行消息持久化;
- 高吞吐,在一台普通的服务器上既可以达到10W/s的吞吐速率;
- .完全的分布式系统,Broker、Producer、Consumer都原生自动支持分布式,自动实现负载均衡;
- 支持同步和异步复制两种HA;
- 支持数据批量发送和拉取;
- zero-copy:减少IO操作步骤;
- 数据迁移、扩容对用户透明;
- 无需停机即可扩展机器;
- 其他特性:严格的消息顺序、丰富的消息拉取模型、高效订阅者水平扩展、实时的消息订阅、亿级的消息堆积能力、定期删除机制;
优点:
- 客户端语言丰富,支持java、.net、php、ruby、python、go等多种语言;
- 性能卓越,单机写入TPS约在百万条/秒,消息大小10个字节;
- 提供完全分布式架构, 并有replica机制, 拥有较高的可用性和可靠性, 理论上支持消息无限堆积;
- 支持批量操作;
- 消费者采用Pull方式获取消息, 消息有序, 通过控制能够保证所有消息被消费且仅被消费一次;
- 有优秀的第三方Kafka Web管理界面Kafka-Manager;
- 在日志领域比较成熟,被多家公司和多个开源项目使用;
缺点:
- Kafka单机超过64个队列/分区,Load会发生明显的飙高现象,队列越多,load越高,发送消息响应时间变长
- 使用短轮询方式,实时性取决于轮询间隔时间;
- 消费失败不支持重试;
- 支持消息顺序,但是一台代理宕机后,就会产生消息乱序;
- 社区更新较慢;
消息队列的pull和push
这么多的消息队列,有一个区别很重要,那就是模式,到底是pull好还是push好,下面就让我们来一探究竟吧
Push
Push即服务端主动发送数据给客户端。在服务端收到消息之后立即推送给客户端。
Push模型最大的好处就是实时性。因为服务端可以做到只要有消息就立即推送,所以消息的消费没有“额外”的延迟。
但是Push模式在消息中间件的场景中会面临以下一些问题:
- 在Broker端需要维护Consumer的状态,不利于Broker去支持大量的Consumer的场景
- Consumer的消费速度是不一致的,由Broker进行推送难以处理不同的Consumer的状况
- Broker难以处理Consumer无法消费消息的情况(Broker无法确定Consumer的故障是短暂的还是永久的)
- 大量的推送消息会加重Consumer的负载或者冲垮Consumer
Pull模式可以很好的应对以上的这些场景。
Pull
Pull模式由Consumer主动从Broker获取消息。
这样带来了一些好处:
- Broker不再需要维护Consumer的状态(每一次pull都包含了其实偏移量等必要的信息)
- 状态维护在Consumer,所以Consumer可以很容易的根据自身的负载等状态来决定从Broker获取消息的频率
Pull模式还有一个好处是可以聚合消息。
因为Broker无法预测写一条消息产生的时间,所以在收到消息之后只能立即推送给Consumer,所以无法对消息聚合后再推送给Consumer。 而Pull模式由Consumer主动来获取消息,每一次Pull时都尽可能多的获取已近在Broker上的消息。
但是,和Push模式正好相反,Pull就面临了实时性的问题。
因为由Consumer主动来Pull消息,所以实时性和Pull的周期相关,这里就产生了“额外”延迟。如果为了降低延迟来提升Pull的执行频率,可能在没有消息的时候产生大量的Pull请求(消息中间件是完全解耦的,Broker和Consumer无法预测下一条消息在什么时候产生);如果频率低了,那延迟自然就大了。
另外,Pull模式状态维护在Consumer,所以多个Consumer之间需要相互协调,这里就需要引入ZK或者自己实现NameServer之类的服务来完成Consumer之间的协调。
有没有一种方式,能结合Push和Pull的优势,同时变各自的缺陷呢?答案是肯定的。
Long-Polling
使用long-polling模式,Consumer主动发起请求到Broker,正常情况下Broker响应消息给Consumer;在没有消息或者其他一些特殊场景下,可以将请求阻塞在服务端延迟返回。
long-polling不是一种Push模式,而是Pull的一个变种。
那么:
- 在Broker一直有可读消息的情况下,long-polling就等价于执行间隔为0的pull模式(每次收到Pull结果就发起下一次Pull请求)。
- 在Broker没有可读消息的情况下,请求阻塞在了Broker,在产生下一条消息或者请求“超时之前”响应请求给Consumer。
以上两点避免了多余的Pull请求,同时也解决Pull请求的执行频率导致的“额外”的延迟。
注意上面有一个概念:“超时之前”。每一个请求都有超时时间,Pull请求也是。“超时之前”的含义是在Consumer的“Pull”请求超时之前。
基于long-polling的模型,Broker需要保证在请求超时之前返回一个结果给Consumer,无论这个结果是读取到了消息或者没有可读消息。
因为Consumer和Broker之间的时间是有偏差的,且请求从Consumer发送到Broker也是需要时间的,所以如果一个请求的超时时间是5秒,而这个请求在Broker端阻塞了5秒才返回,那么Consumer在收到Broker响应之前就会判定请求超时。所以Broker需要保证在Consumer判定请求超时之前返回一个结果。
通常的做法时在Broker端可以阻塞请求的时间总是小于long-polling请求的超时时间。比如long-polling请求的超时时间为30秒,那么Broker在收到请求后最迟在25s之后一定会返回一个结果。中间5s的差值来应对Broker和Consumer的始终存在偏差和网络存在延迟的情况。 (可见Long-Polling模式的前提是Broker和Consumer之间的时间偏差没有“很大”)
Long-Polling还存在什么问题吗,还能改进吗?
Dynamic Push/Pull
“在Broker一直有可读消息的情况下,long-polling就等价于执行间隔为0的pull模式(每次收到Pull结果就发起下一次Pull请求)。”
这是上面long-polling在服务端一直有可消费消息的处理情况。在这个情况下,一条消息如果在long-polling请求返回时到达服务端,那么它被Consumer消费到的延迟是:
假设Broker和Consumer之间的一次网络开销时间为R毫秒,
那么这条消息需要经历3R才能到达Consumer
第一个R:消息已经到达Broker,但是long-polling请求已经读完数据准备返回Consumer,从Broker到Consumer消耗了R
第二个R:Consumer收到了Broker的响应,发起下一次long-polling,这个请求到达Broker需要一个R
的时间
第三个R:Broker收到请求读取了这条数据,那么返回到Consumer需要一个R的时间
所以总共需要3R(不考虑读取的开销,只考虑网络开销)
另外,在这种情况下Broker和Consumer之间一直在进行请求和响应(long-polling变成了间隔为0的pull)。
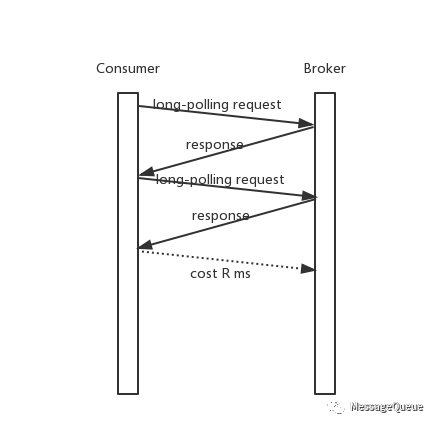
考虑这样一种方式,它有long-polling的优势,同时能减少在有消息可读的情况下由Broker主动push消息给Consumer,减少不必要的请求。
参考文章
http://www.luyixian.cn/news_show_261068.aspx
https://blog.51cto.com/caczjz/2141194?source=dra

