BACKBONE-POSE
BACKBONE
前言
本篇博客记录姿态估计(关键点检测)常见backbone,具体如下:
Hourglass
hourglass module

Hourglass模块设计的初衷就是为了捕捉每个尺度下的信息,因为捕捉人脸,手这些部分的时候需要局部的特征,而最后对人体姿态进行预测的时候又需要整体的信息。为了捕获图片在多个尺度下的特征,通常的做法是使用多个pipeline分别单独处理不同尺度下的信息,然后在网络的后面部分再组合这些特征,而作者使用的方法就是用带有skip layers的单个pipeline来保存每个尺度下的空间信息。
中间监督

作者在整个网络结构中堆叠了许多hourglass模块,从而使得网络能够不断重复自底向上和自顶向下的过程,作者提到采用这种结构的关键是要使用中间监督来对每一个hourglass模块进行预测,即对中间的heatmaps计算损失。在上图中,每个hourglass模块后面跟着两个卷积核,来得到本模块的输出并作为下一个模块输入的一部分,下面分支将heatmap作为输出进行loss计算,再进行1x1卷积以匹配通道数。
HRNet
网络介绍
关于hrnet的论文、应用以及代码地址可以参考王井东博士主页,包含hrnet姿态估计、语义分割、人脸对齐、图像分类、目标检测这几项任务上实现的详细介绍。
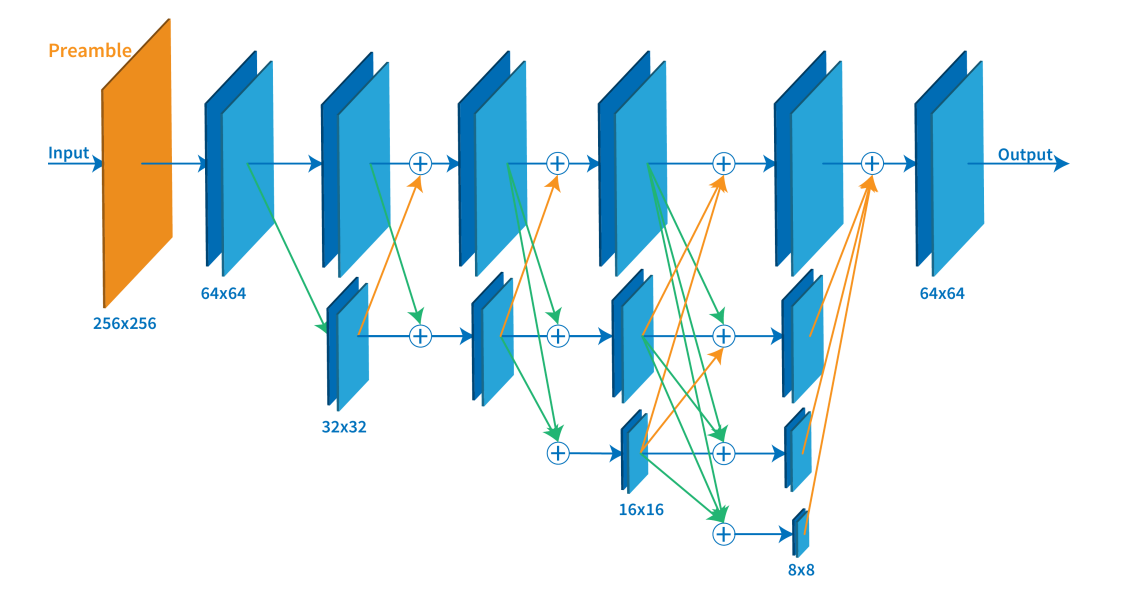
多尺度特征融合
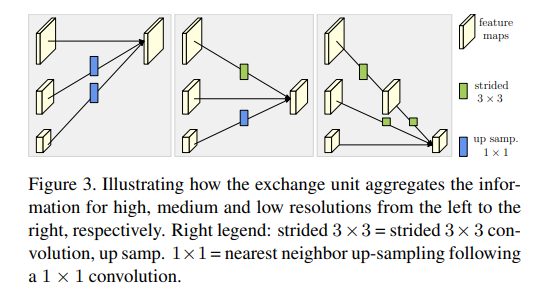
文章中的 Repeated multi-scale fusion, 也就是不同分辨率feature map的fusion。如上图所示exchange unit:
- 同分辨率之间的直接复制
- 需要升分辨率的使用bilinear upsample, 并利用1x1卷积统一通道数
- 需要降分辨率的使用stride 3x3卷积。这里降分辨率之所以不使用池化,是想利用stride3x3 可学习的方式降低信息的损耗
热图估计
对最后一个exchange unit的高分辨率输出进行简单的热图回归。损失函数采用均方误差,比较预测的热图和groundtruth热图, 这里groundtruth热图采用以关键点为中心,1个像素标准差的2d高斯生成。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号