
Python与Json、pickle模块
下面介绍Python如何使用Json、Pickle模块
这两个模块用于序列化
一、什么是序列化
#序列化:内存----》字符串 pickle.dumps 、pickle.dump
将内存中的数据转换为字符串,保存在本地的过程,叫序列化
#反序列化:字符串-----》内存 pickle.loads 、pickle.load
从将本地硬盘中的数据读到内存中的过程,叫反序列化
二、Python与Json模块
A、json,用于字符串 和 python数据类型间进行转换;
B、Json模块提供了四个功能:dumps、dump、loads、load;
C、示例代码:
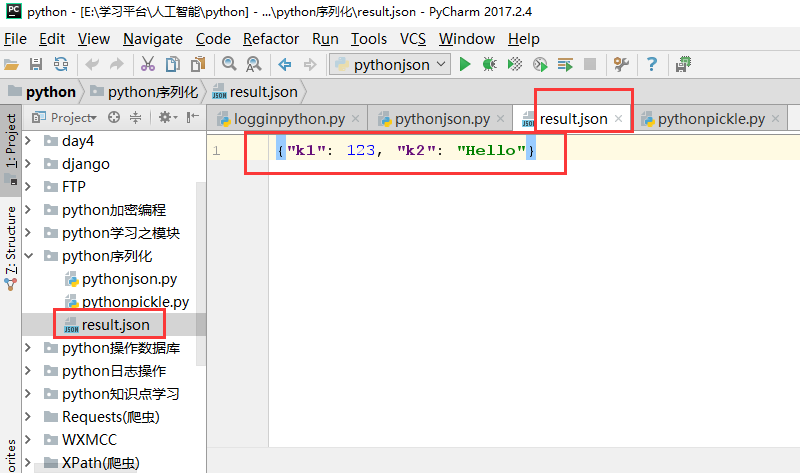
import json data={'k1':123,'k2':'Hello'} #json.dumps 将数据通过特殊的形式转换为所有程序语言都认识的字符串 j_str=json.dumps(data)
print(j_str) #json.dump 将数据通过特殊的形式转换为所有程序语言都认识的字符串,并写入文件 with open('result.json','w') as fp: json.dump(data,fp)
执行结果:
三、Python与Pickle模块
A、pickle,用于python特有的类型 和 python的数据类型间进行转换
B、pickle模块提供了四个功能:dumps、dump、loads、load;
C、示例代码:
import pickle data={'k1':123,'k2':'Hello'} #pickle.dumps 将数据通过特殊的形式转换为只有python程序语言认识的字符串 p_str=pickle.dumps(data) print(p_str) #pickle.dump将数据通过特殊的形式转换为只有python语言认识的字符串,并写入文件 with open('result.pk','w') as fp: pickle.dump(data,fp)
执行结果:

四、事例演绎:pickle模块
picklein.py:序列化过程
import pickle #往文件只写两种格式数据类型:byte与字符串 account={ "id":6225353234, "credit":15000,#credit card "balance":8000, "expire_date":"2020-5-21", "password":"sdfsf" } # f = open("account.db","w") # f.write(str(account)) # print(str(account)) # f.close() f = open("account.db","wb") # f.write(pickle.dumps(account))等同下一句语句 pickle.dump(account,f) f.close()
pickleout.py反序列化过程
#序列化:内存----》字符串 pickle.dumps #反序列化:字符串-----》内存 pickle.loads # f=open("account.db","r") # account=eval(f.read()) #eval数据转换 # print(account) # print(account['id']) import pickle f=open("account.db","rb") # account=pickle.loads(f.read())等同下一句语句 account=pickle.load(f) print(account) print(account['id']) # account['balance'] -=3400 # f = open("account.db","wb") # f.write(pickle.dumps(account)) # f.close()
五、事例演绎:json模块
jsonin.py序列化过程:
import json as pickle #往文件只写两种格式数据类型:byte与字符串 account={ "id":6225353234, "credit":15000,#credit card "balance":8000, "expire_date":"2020-5-21", "password":"sdfsf" } # f = open("account.db","w") # f.write(str(account)) # print(str(account)) # f.close() f = open("account.json","w") # f.write(pickle.dumps(account))等同下一句语句 pickle.dump(account,f) f.close()
jsonout.py反序列化过程:
#序列化:内存----》字符串 pickle.dumps #反序列化:字符串-----》内存 pickle.loads # f=open("account.db","r") # account=eval(f.read()) #eval数据转换 # print(account) # print(account['id']) import json as pickle f=open("account.json","r") # account=pickle.loads(f.read())等同下一句语句 account=pickle.load(f) print(account) print(account['id']) # account['balance'] -=3400 # f = open("account.db","wb") # f.write(pickle.dumps(account)) # f.close()
六、Json与Pickle两个模块区别
A、 Pickle模块支持Python中任何字符
示例:
import pickle import datetime #往文件只写两种格式数据类型:byte与字符串 account={ "id":6225353234, "credit":15000,#credit card "balance":8000, "expire_date":"2020-5-21", "password":"sdfsf", "register_date":datetime.datetime.now() } # f = open("account.db","w") # f.write(str(account)) # print(str(account)) # f.close() f = open("account.db","wb") # f.write(pickle.dumps(account))等同下一句语句 pickle.dump(account,f) f.close()
执行结果:成功

B、 Json只支持str,int ,float, set ,dict, list, tuple
示例:
import json as pickle import datetime #往文件只写两种格式数据类型:byte与字符串 account={ "id":6225353234, "credit":15000,#credit card "balance":8000, "expire_date":"2020-5-21", "password":"sdfsf", "register_date":datetime.datetime.now() } # f = open("account.db","w") # f.write(str(account)) # print(str(account)) # f.close() f = open("account.json","w") # f.write(pickle.dumps(account))等同下一句语句 pickle.dump(account,f) f.close()
执行结果:失败
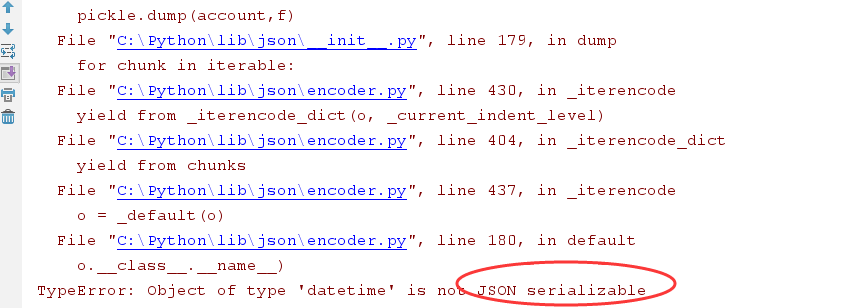
七、Json与Pickle使用时要注意的地方
1、从以上的比较来看,这两个模块使用的方式是一样的,唯一区别就是在Python中,Pickle支持全部数据类型,Json支持的数据类型相对比较少
2、Json与Pickle允许dump多次,也允许load多次,但由于读取时没有循环功能,因为建议最好只允许dump一次。
