stata split一列分成多列
use hea\he,clear
split ysum,parse(-)gen(new_x)
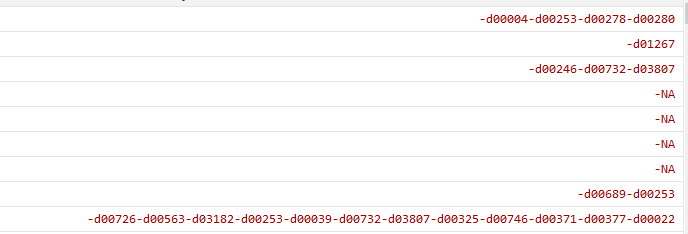
结果为:

使用 split 命令可以实现字符型变量的分列。
一、基础命令
// strvar 表示字符型变量
split strvar [if] [in] [, options]
/* Options:
Main Options:
generate(stub): 新变量名开头为stub, 默认是原来的变量名strvar, 简写作gen(stub);
parse(parse_strings): 指定分列的字符, 默认是空格;
limit(#): 最多创建的变量个数;
notrim: 不删除原始变量最前面和最后面的空格。
Destring Options:
destring 将 destring: 应用于新的字符串变量, 尽可能用数字变量替换初始字符串变量;
ignore("chars"): 删除指定的非数字字符;
force: 将非数字字符串转换为缺失值;
float: 指定新生成的数值变量为浮点型(float);
percent: 将百分比变量转换为分数形式。 */
使用 destring 这一选项,可以将生成的变量转化为数值型变量。在使用 destring 后,就可以使用剩下的 4 个 destring options。
二、示例
示例 1:1⃣️ 提取日期、时间等数据中的信息;2⃣️ 将百分数转化为分数。
/* 示范数据:
+---------------------------+
| date time x1 |
|---------------------------|
1. | 22/1/17 09:45:32 55% |
2. | 22/1/17 14:39:36 6% |
3. | 22/1/17 15:42:45 11% |
4. | 22/1/17 08:52:09 10% |
5. | 21/12/24 15:51:33 300 |
+---------------------------+ */
** 把从字符型的日期和时间中提取数据
split date, parse(/) limit(3) destring
split time, parse(:) limit(3) destring
** 将 x1 的百分号去掉,并转化为分数形式【注意:没有百分号的样本也会被当作百分数】
split x1, gen(new_x) destring percent
// 上面的命令等价于:
destring x1,gen (newvar) ignore(%) replace
gen new_x1=newvar/100
drop newvar
/* 结果展示:
+------------------------------------------------------------------------------------+
| date time x1 date1 date2 date3 time1 time2 time3 new_x1 |
|------------------------------------------------------------------------------------|
1. | 22/1/17 09:45:32 55% 22 1 17 9 45 32 .55 |
2. | 22/1/17 14:39:36 6% 22 1 17 14 39 36 .06 |
3. | 22/1/17 15:42:45 11% 22 1 17 15 42 45 .11 |
4. | 22/1/17 08:52:09 10% 22 1 17 8 52 9 .1 |
5. | 21/12/24 15:51:33 300 21 12 24 15 51 33 3 |
+------------------------------------------------------------------------------------+
数据中:
date1、date2、date3 分别为从date中提取出的年、月、日;
time1、time2、time3 分别为从time中提取的时、分、秒;
new_x1 为将百分数变量 x1 转化成的小数形式。 */
示例 2:分离地址信息
** 从地址中提取地理位置信息
split address, parse(省 自治区 市 区 县) gen(address) limit(3)
/* 结果展示:
+-------------------------------------------------------+
| address address1 ddress2 address3 |
|-------------------------------------------------------|
1. | 北京市东城区 北京 东城 |
2. | 上海市奉贤区 上海 奉贤 |
3. | 江苏省南京市鼓楼区 江苏 南京 鼓楼 |
4. | 河南省郑州市中原区 河南 郑州 中原 |
5. | 内蒙古自治区呼和浩特市回民区 内蒙古 呼和浩特 回民 |
+-------------------------------------------------------+ */
/* Note: 在识别地址时, 北京、上海、重庆、天津四个直辖市的信息会从第一个变量 address 开始保存, 因此:
如果需要的是省级行政区的信息,则不需要再做调整;
如果需要将四个直辖市的信息保存至地级市的变量 address2 以后, 则可以用 replace 的方式替换。 */
** 替换方法:
replace address3=address2 if address1=="北京" | address1=="天津" | address1=="上海" | address1=="重庆"
replace address2=address1 if address1=="北京" | address1=="天津" | address1=="上海" | address1=="重庆"
replace address1="" if address1=="北京" | address1=="天津" | address1=="上海" | address1=="重庆"
/* 结果展示:
+-------------------------------------------------------+
| address address1 address2 address3 |
|-------------------------------------------------------|
1. | 北京市东城区 北京 东城 |
2. | 上海市奉贤区 上海 奉贤 |
3. | 江苏省南京市鼓楼区 江苏 南京 鼓楼 |
4. | 河南省郑州市中原区 河南 郑州 中原 |
5. | 内蒙古自治区呼和浩特市回民区 内蒙古 呼和浩特 回民 |
+-------------------------------------------------------+ */

 浙公网安备 33010602011771号
浙公网安备 33010602011771号