STATA命令
cd d:\statashu
//导入指定文件,原表第一行作为变量名,所有变量都是字符串型
import excel "D:\statashu\期中考试学生名单.xlsx", sheet("Sheet1") firstrow all string
//修改变量名
rename 姓名 name
rename 考号 kaohao
rename 班级 banji
//判断指定变量是否唯一:如果有提示则不唯一 ,如果没有提示则说明相应的变量观测值都不重复
isid name
//variable name does not uniquely identify the observations
//r(459);
isid kaohao
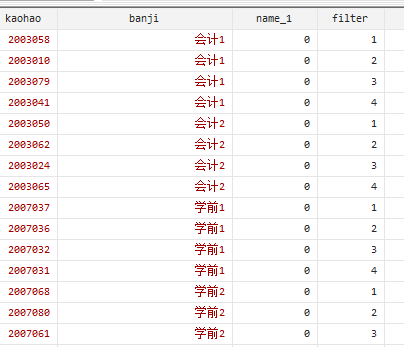
//增加新变量名name_1,如果name有重复的则值为1,否则为0,给重复的加标记
duplicates tag name, generate(name_1)
//Duplicates in terms of name
//如果变量banji有重复的,则新产生变量filter,对于相同的banji值的数据从1到最后一条编号
bys banji:gen filter=_n
keep if filter<5
//截取name最右边的一个汉字作为新变量的值
gen name_3=substr(name,-3,.)
sort 证券代码 date
by 证券代码 date:gen daycount = _N //对证券代码和date相同的观测:则产生计数变量:_N
by date 证券代码: gen set=_n //对证券代码和date相同的观测:产生编号变量_n:从1到 最后
*每一个id只保留一个记录
sort 证券代码
by 证券代码: gen filter=_n //对相同id的数据从1到最后一条编号
keep if filter == 1 //只保留第一条
save one_record //保存数据到本地
*这一段代码可以删除重复的观测
sort date 证券代码
by date 证券代码: gen set=_n //证券代码和date相同则编号:从1到 最后
keep if set==1 //date 和 证券代码相同的观测,只保留了一条记录
drop set
save mystockdata_dropreplicate,replace

 浙公网安备 33010602011771号
浙公网安备 33010602011771号