windows上安装和运行spark scala
更多IT系统运维、大数据实战、项目管理、商务英语及应用知识,扫描下方二维码关注公众号了解更多!!!

本文主要记录windows系统上安装spark,scala,和intelj IDEA,并实现本地spark运行。同时介绍了利用maven构建工具对spark工程构建的方法。本地运行需要本地安装scala,spark,hadoop。而如果利用maven构建工具则只需要再maven的pom.xml配置好需要的scala,spark,hadoop版本信息,构建时自动导入相应依赖,常用于企业级的项目开发中。
一,安装篇
这部分介绍常规spark本地运行的必要软件安装。而如果你使用的是Maven构建工具,那么下面的步骤3,4,5都可以略过(由maven根据配置文件自动构建),我们只用安装最基本的1,2以及6环境变量中与JAVA相关的部分。maven安装见本节7。
本地安装部分更详细的可以参考:https://blog.csdn.net/u011513853/article/details/52865076
1,安装jdk,需要是jdk8(也被称为jdk1.8)
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
环境变量:
创建JAVA_HOME:C:\Program Files\Java\jdk1.8.0_181
创建CLASSPATH:.;%JAVA_HOME%\lib;%JAVA_HOME%\lib\tools.jar(前面有个点号)
Path添加:%JAVA_HOME%\bin;
测试是否安装成功:打开cmd命令行,输入java -version
2,安装intelj IDEA并配置scala插件
https://www.jetbrains.com/idea/
IDEA安装完成后,安装scala插件:启动intelj -> 点击启动页configuration -> Plugins,或者file->setting->Plugins,搜索scala并安装插件。如果搜不到,可能是需要代理:Install JetBrains plugin... -> HTTP Proxy Settings设置代理。
安装完成后要重启IDEA。
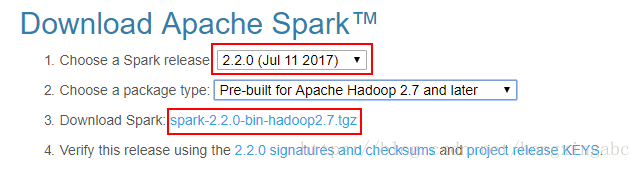
3,安装spark
下载后解压到指定目录即可,这里我们选择2.2.0版本
http://spark.apache.org/downloads.html
环境变量:
创建SPARK_HOME:D:\spark-2.2.0-bin-hadoop2.7
Path添加:%SPARK_HOME%\bin
测试是否安装成功:打开cmd命令行,输入spark-shell
spark-shell时报错:error not found:value sqlContext。参考:https://www.liyang.site/2017/04/19/20170419-spark-error-01/
4,安装Hadoop
说明:如果你只是玩Spark On Standalone的话,就不需要安装hadoop,如果你想玩Spark On Yarn或者是需要去hdfs取数据的话,就应该先装hadoop。关于spark和hadoop的关系,强烈推荐这篇博客:Spark是否会替代Hadoop?
安装上面spark对应版本的hadoop 2.7:http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
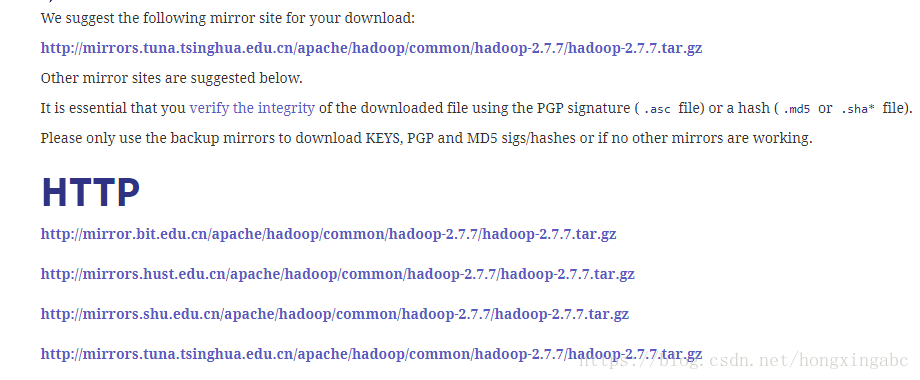
解压到指定目录即可。
环境变量:
创建HADOOP_HOME:D:\hadoop-2.7.7
Path添加:%HADOOP_HOME%\bin
测试是否安装成功:打开cmd命令行,输入hadoop
hadoop测试时报错:Error: JAVA_HOME is incorrectly set。参考:https://blog.csdn.net/qq_24125575/article/details/76186309
5,安装scala SDK
其版本应与上面spark/jars/中scala版本一致,2.2.0版本spark对应的scala版本位2.11.8,https://www.scala-lang.org/download/2.11.8.html
上面链接中提到了多种scala的安装方式,比较省事的是通过已经安装好scala插件的intelj IDEA安装scala SDK(注意区分插件和SDK):File => New => Project,选择scala,输入工程名,如果是第一次新建scala工程,会有一个scala SDK的Create按钮,然后选择需要的版本安装。
而我使用的是安装包安装方式:

环境变量:
创建SCALA_HOME: C:\Program Files (x86)\scala
Path添加:;%SCALA_HOME%\bin; %JAVA_HOME%\bin;;%HADOOP_HOME%\bin
测试是否安装成功:打开cmd命令行,输入scala
7,maven构建工具安装(如果不用maven构建工具,不用装)
http://maven.apache.org/download.cgi
也是下载后解压即可。
环境变量:
MAVEN_HOME = D:\apache-maven-3.5.4
MAVEN_OPTS = -Xms128m -Xmx512m
path添加:%MAVEN_HOME%\bin
测试是否安装成功:打开cmd,输入mvn help:system
二,开发篇
下面介绍本地spark开发的示例,虽然spark是处理大数据的,常常在大型计算机集群上运行,但本地spark方便调试,可以帮助我们学习相关的语法。maven构建工具的开发流程可以参看:https://blog.csdn.net/u012373815/article/details/53266301
打开idea, file=>new=>project=>选择scala工程,选择IDEA=>输入工程名(如test),路径,JDK选刚刚安装的1.8,scala SDK选刚刚安装的scala-sdk-2.11.8(或者点右边的create,选择你想要的版本下载)=>finish
再src上右键=>new=>scala class=>选下拉框scala object,输入类名。
输入测试代码,这是一段分组排序的代码:
import org.apache.spark.{SparkContext,SparkConf}
object Sort {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("GroupSort")
val sc = new SparkContext(conf)
val test =List(("key1","123",12,2,0.13),("key1","123",12,3,0.18),("key2","234",12,1,0.09),("key1","345",12,8,0.75),("key2","456",12,5,0.45))
val rdd = sc.parallelize(test)
val rdd1= rdd.map(l => (l._1, (l._2, l._3, l._4, l._5))).groupByKey()
.flatMap(line => {
val topItem = line._2.toArray.sortBy(_._4)(Ordering[Double].reverse)
topItem.map(f=>(line._1,f._1,f._4)).toList
})
rdd1.foreach(println)
sc.stop()
}
}
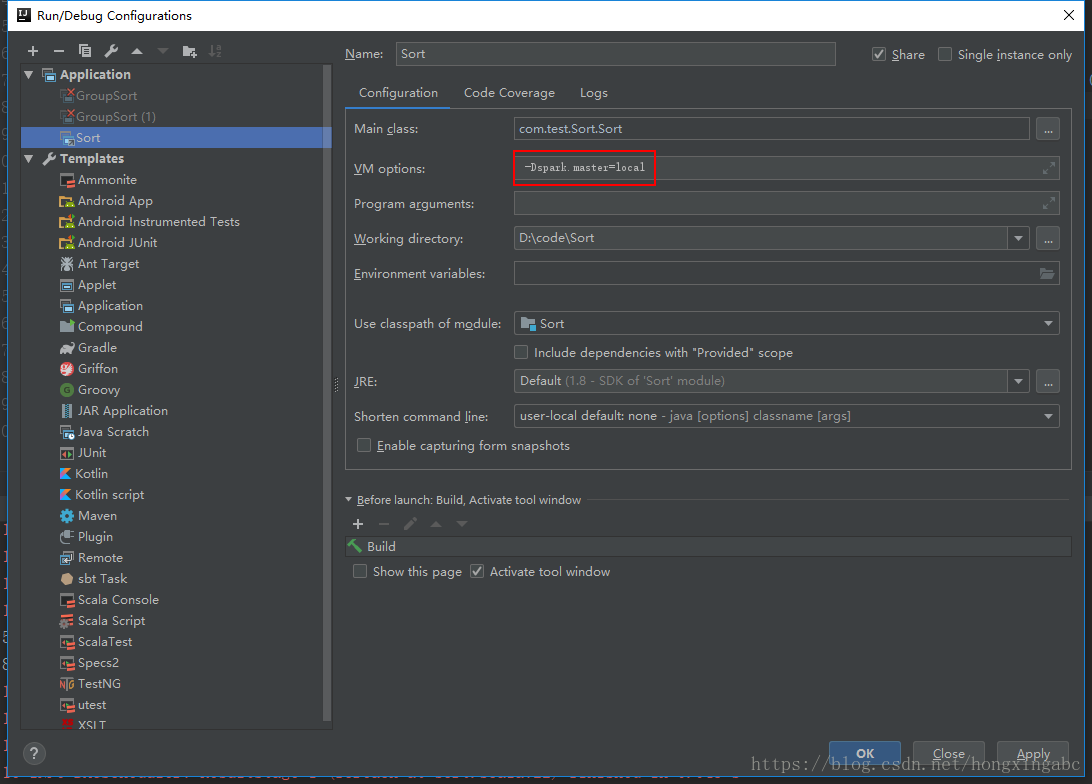
设置本地模式:run=>edit configrations=>Application=>选择我们应用,VM options上添加-Dspark.master=local -Dspark.app.name=test
包含spark和scala sdk: 工程目录右键=>open module settings=> project settings=> libraries=>"+"=>java=>选择spark安装目录下的jars文件夹=>确认。同样地,“+”=>scala sdk =>选择需要的scala sdk(与spark版本对应的sdk)=>确认。
运行代码:

三,问题集锦:
1, import org.apache.spark.SparkContext引入了包,但下面代码connot resolve symbol SparkContext.(IDEA环境下,maven工程)
问题检查:工程目录右键->open module setting->project setting->libraries,发现左侧没有包含任何依赖库。
解决方法:如果是maven工程,则工程目录右键->maven->reimport。这个时候会自动下载相关依赖。相关依赖在.m2的repository文件夹下。如果是普通scala工程,按前面“开发篇”介绍的:工程目录右键=>open module settings=> project settings=> libraries=>"+"=>java=>选择spark安装目录下的jars文件夹=>确认。同样地,“+”=>scala sdk =>选择需要的scala sdk(与spark版本对应的sdk)=>确认。
思考:maven真的很强大,比如安装了scala插件后,不许要安装scala JDK,直接利用maven pom.xml配置好scala的版本,自动下载相应的scala的包。这样做有利于大型工程协助,同一个pom.xml文件可以保证大家都在同样的依赖库环境下开发。
2, 全局变量要谨慎,尤其是Buffer类型,因为你不知道它可能被塞进多少东西,除非你真的需要。
例如:
val data_set: RDD[(String, String, Int, Int)] = raw_rdd.map(generate_instance_per_line(_, configure))
其中generate_instance_per_line函数里对一个globalListBuffer全局变量进行了append操作,那么每一个map都会执行一次append.
3, SparkException: An application name must be set in your configuration
解决方法:
进入:Run > Edit Configurations... > Application > "My project name" > Configuraton,
设置VM options项为-Dspark.master=local.
-Dspark.master=local:表示设置我的spark程序以local模式运行
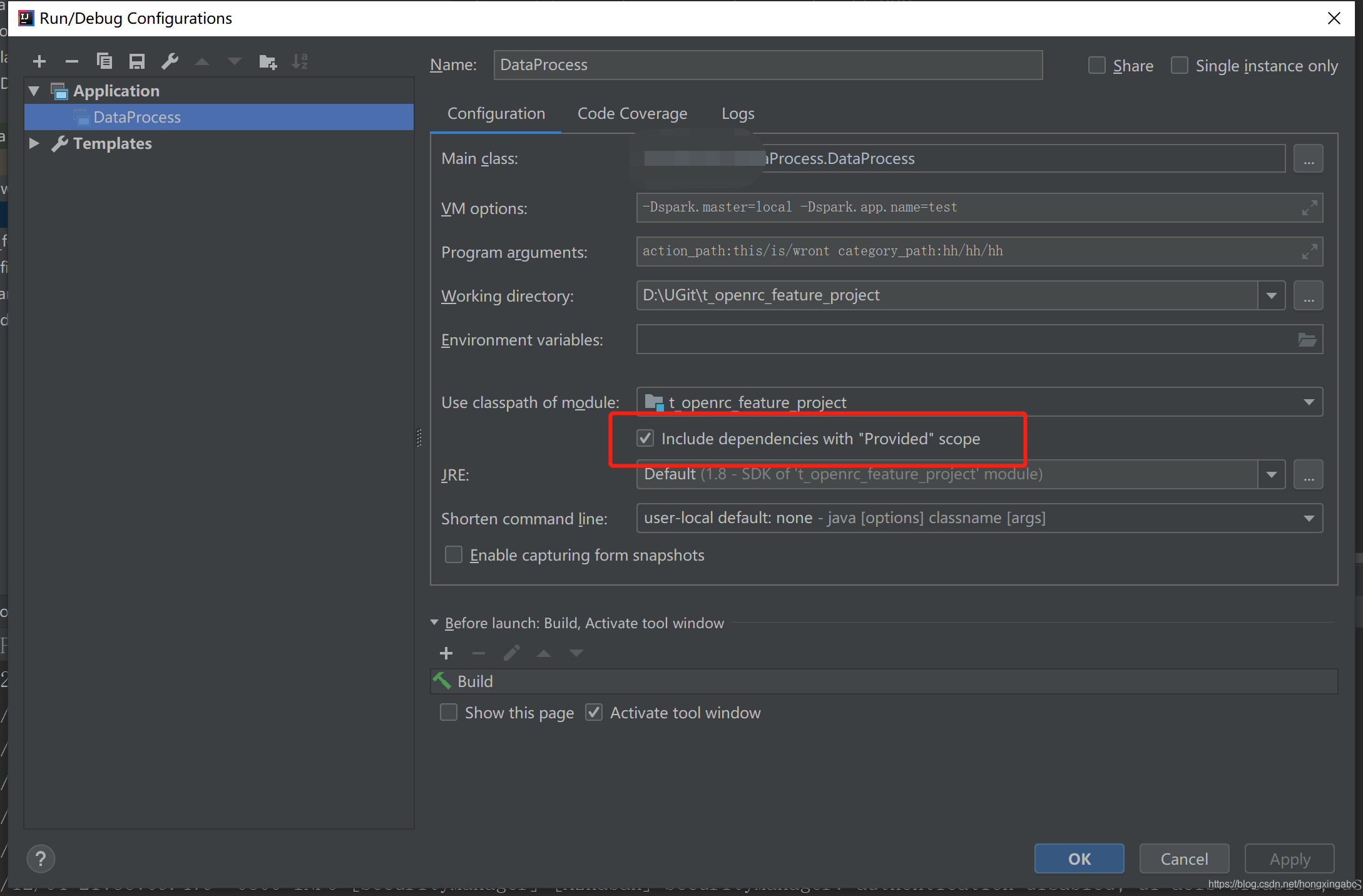
4,java.lang.NoClassDefFoundError: org/apache/spark/SparkContext
import org.apache.spark.SparkConf没有报错,但运行时报上面NoClassDefFoundError错误。
解决办法:maven工程build的包有provided和compile两种模式,provided用于:运行环境已经有了相应的包,所以没有必要在build时把相关的包打包进来,减少jar包的体积。本地运行时,需要把provide改成complie。或者IDEA提供了更方便的做法:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号