

SQL优化(2)
数据库优化
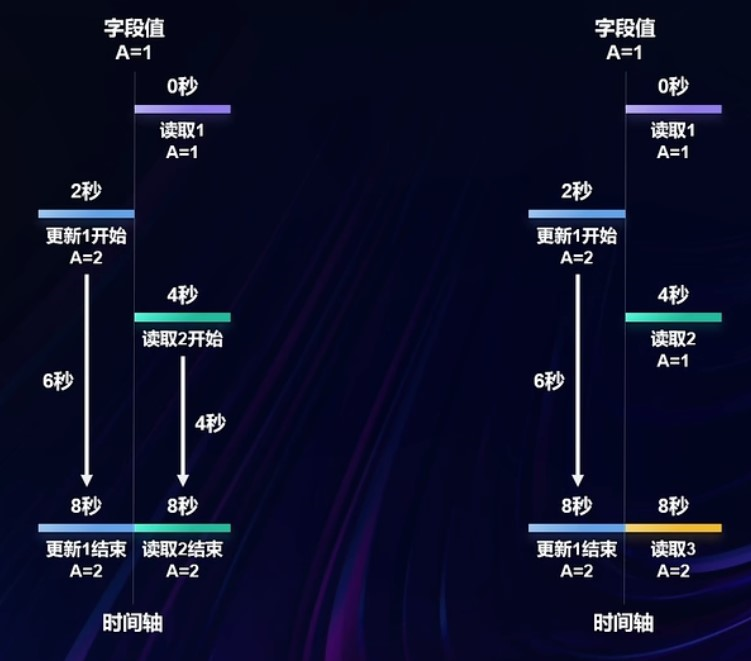
快照隔离
在保护事务不脏读未提交的数据修改的同时尽量减少锁定争用(数据修改的同时可以读取未提交修改前的)
查询状态
SELECT name,is_read_committed_snapshot_on FROM sys.database
设置快照隔离
ALTER DATABASE database_name SET READ_COMMITTED_SNAPSHOT ON
查询过程
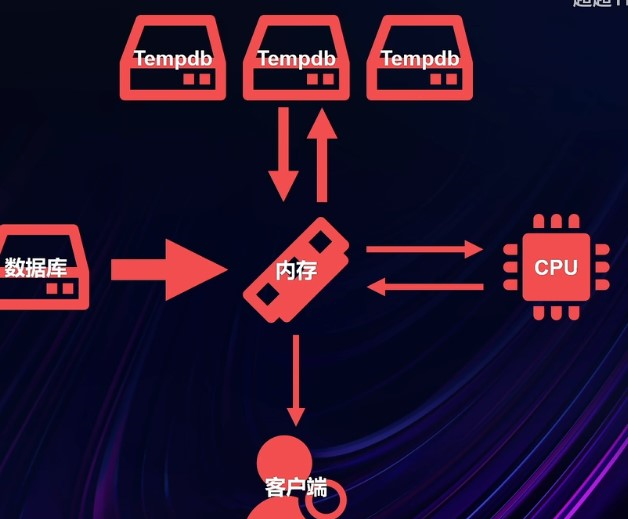
Tempdb
主要存储临时表、中间查询结果、排序操作、行版本控制的版本存储等
不同文件可以放在不同的物理磁盘上以提高IO吞吐量
与计算机上的CPU数量一致,可以避免资源争用等一些问题,某些情况下会带来一些好处
SQL优化
如何查找有问题的SQL
- 活动监控器
- 性能报表
- SQL Server Profiler
- 查询存储
如何找到SQL语句的性能问题?
- 执行计划
- 性能统计
IO是有缓存的,光看执行时间是没有办法真实统计性能差异的,有可能数据被缓存了,开启IO统计,可以查看逻辑读取了几次,查看性能差异
SET STATISTICS TIME ON --统计时间 SET STATISTICS IO ON --统计IO
性能优化
数据存储:行存储与列存储;行存储更适合数据维护场景;列存储更适合数据分析场景;
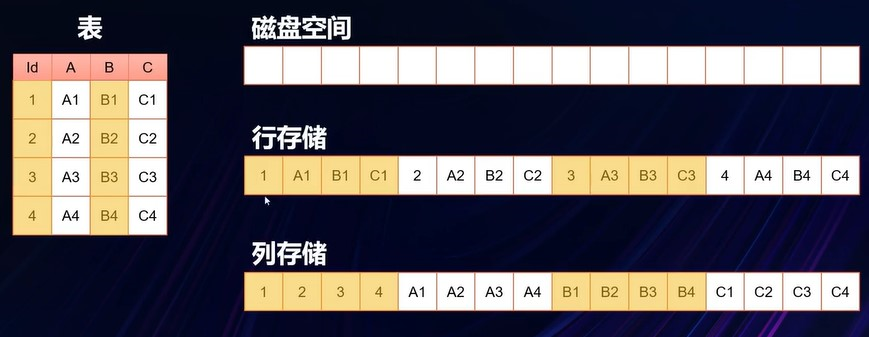
表存储类型
行存储:聚集索引,使用B+树
列存储:聚集列存储索引
索引限制
一个表中聚集索引和聚集列存储索引只能二选一
一个表中非聚集索引和非聚集列存储索引可以并存
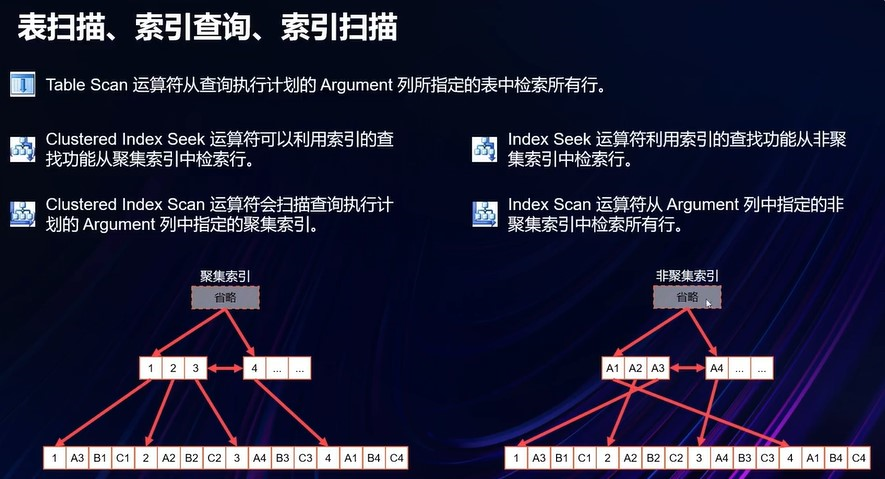
行存储索引:索引结构 B+Tree
聚集索引
- 聚集索引中,叶节点包含基础表的数据页
- 数据链内的页和行按聚集索引键值进行排序
- 主键通常是聚集索引,但可以不是聚集索引
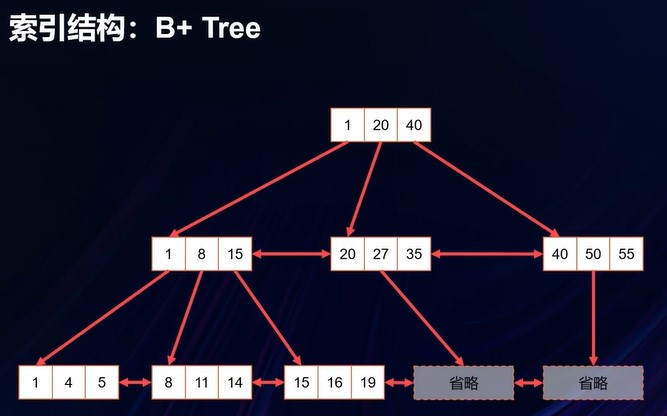
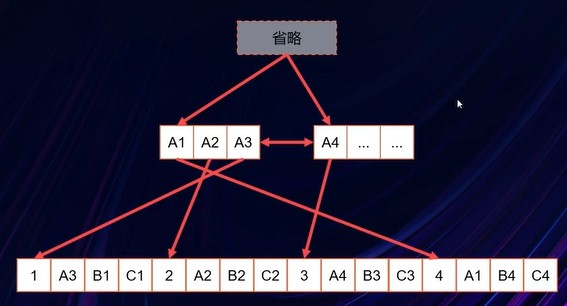
非聚集索引
- 基础表的数据行不会过根据其非聚集键值按顺序排序和存储
- 非聚集索引的叶级别是由索引页而不是由数据页组成。非聚集索引的叶级别的索引页包含键列以及包含列
索引设计
- 包含列
- 筛选器(条件索引)
索引选择
- 统计信息
- 表或索引视图的一列或多列的值分布有关的统计
- 查询优化器使用统计信息创建可提高查询性能的查询计划,估计查询结果中的技术或行数
- 对于大多数查询,会自动生成必要的统计信息
- 直方图度量数据集中每个非重复值的出现频率。密度矢量度量给定列或列组合中重复项数目的信息
- 优化建议:什么都不要做,即不要强制指定索引
存储结构:页存储
常见的索引设计建议
- 优先选择唯一性索引
- 为常作为查询条件的字段建立索引
- 经常需要排序、分组和联合操作的字段建立索引
- 尽量使用数据量少的索引,如果字段数据大,索引表体积相对较大,当发生索引扫描时影响比较严重
- 控制索引数量,索引的字段发生修改时需要更新索引,过多索引影响表性能
- 删除很少用的索引,可以通过报表查看索引使用情况
- 复合索引区分度大的字段放在前面
- 区分度小的字段不建议创建索引,比如性别
- 命名建议用索引的字段名作为名称,方便在查询计划中分辨,不建议添加“IX"之类的前缀,SQL Server 索引名称允许跨表重名
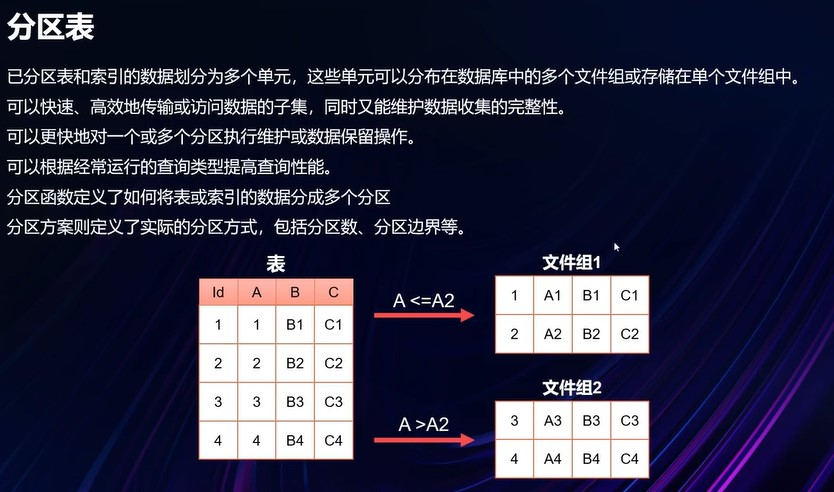
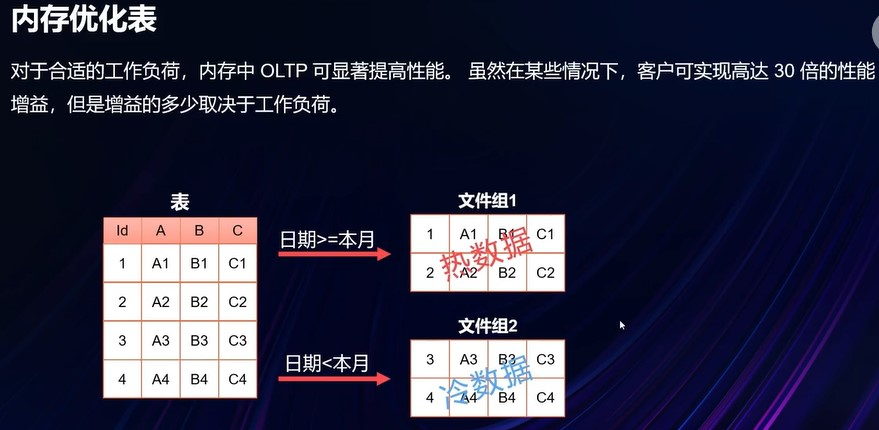
其他优化:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?