

oracle 常用索引分析,使用原则和注意事项
本文参考:
https://www.cnblogs.com/wishyouhappy/p/3681771.html
https://blog.csdn.net/weivi001/article/details/45498405
索引简介
• 索引(index)是数据库对象的一种。索引的关键在于通过一组排序后的物理地址作为键来取代默认的全表扫描检索方式,就像为书本添加目录,通过牺牲物理内存的方式提高数据的检索效率。
• 它对用户时透明的,它的创建不会影响对表的sql操作。索引一旦建立,在表上进行DML操作时(例如在执行插入、修改或者删除相关操作时),oracle会自动管理索引。
• oracle创建主键时会自动创建索引
添加索引
1.创建默认索引
CREATE UNIQUE INDEX (索引名称) ON 表名 (列名1,列名2...) ; --unique(默认)表示唯一索引
2.修改索引
alter index (旧索引名称) rename to(新索引名称);
3.删除索引
drop index (索引名称);
4.查看索引
查看某表的所有索引:
select index_name,index-type, tablespace_name, uniqueness from all_indexes where table_name =(表名);
常用的2种索引及适用场景
1.b树索引(默认索引,保存排序过的索引列和对应的rowid值)
b树索引是oracle最常见的的索引,它的原理是利用了b-树的数据结构(b树的原理:https://blog.csdn.net/baidu_30569267/article/details/80983295)
b树索引结构图:
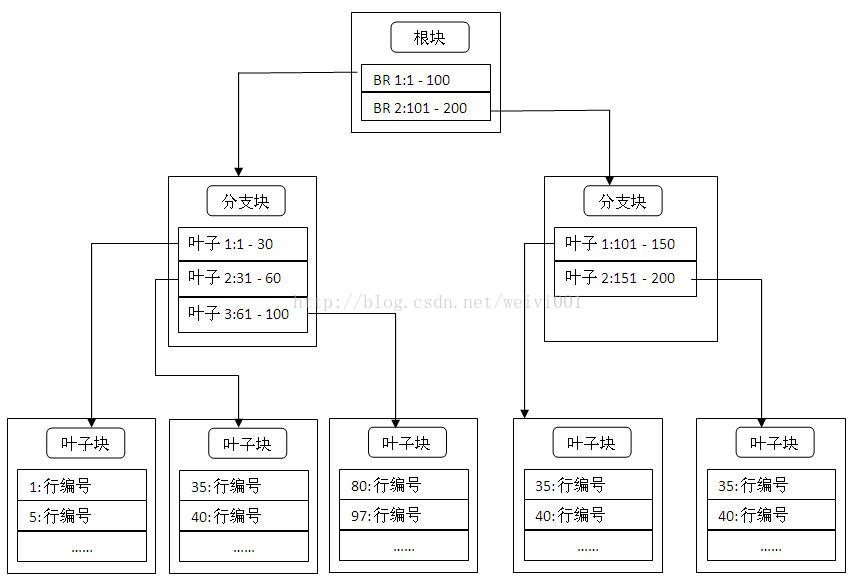
b树的所有叶子节点拥有相同的深度,oracle将索引列和对应的rowid值存入叶子节点上,因此所有的检索速度基本都是相同的。
b树索引的不适用场景:
不适合键值较少的列(重复数据较多的列)
假如索引列TYPE有5个键值,如果有1万条数据,那么 WHERE TYPE = 1将访问表中的2000个数据块。再加上访问索引块,一共要访问大于200个的数据块。
如果全表扫描,假设10条数据一个数据块,那么只需访问1000个数据块,既然全表扫描访问的数据块少一点,肯定不会利用b树索引了。
(不过,事实上,当取出的行数据占用表中大部分的数据时,即使添加了B树索引,数据库如oracle、mysql也不会使用B树索引,很有可能还是一行行全部扫描)
2.位图索引(bit-map index)
位图索引是对列的每个键值设置一个位图。
比如有这样一列a:
10 20 30 20 10 30 10 30 20 30
那么会建立三个位图,如下:
KEY=10 1 0 0 0 1 0 1 0 0 0
KEY=20 0 1 0 1 1 0 0 0 1 0
KEY=30 0 0 1 0 0 1 0 1 0 1
这适合于该列的基数非常小的情况,当建立位图索引时,会为每个独立的值建立向量,比如上面3个,就会建立3个向量:key=10: 1000101000,key=20: 0101100010...
如果再有一列b:
x y x x y y y x y
key = x : 1 0 1 1 0 0 0 1 0
key = y : 0 1 0 0 1 1 1 0 1
如果你对a列和b列使用 and 或者 or操作,这里就会体现位图索引使用bit的优势:比如 "a=10 and b =x " :它会将 key=10 :100010100向量 和 b=x :101100010向量进行与操作,更快的取出索引对应的行。
适用场景:
和B树索引相反,位图索引适合键值重复率高的表,若重复值很低,则位图索引相对的会需要大量数据。由于位图索引采用0,1记录某行是否包含该键值,因此非常适合AND, OR, NOT,count等这样的逻辑操作。
位图索引非常不适合有大量“写”的操作,因为每一个位图键值中,都可能对于多条记录,当修改一条记录更新位图键值时,会在对应的位图索引键上加锁,从而导致对其它记录的修改也会被阻塞。
什么情况下需要建立索引
1. 如果有两个或者以上的索引,其中有一个唯一性索引,而其他是非唯一,这种情况下oracle将使用唯一性索引而完全忽略非唯一性索引
2. 至少要包含组合索引的第一列(即如果索引建立在多个列上,只有它的第一个列被where子句引用时,优化器才会使用该索引),因此最常查询的列应该放在前面
3.小表不需要建立索引
4.列中有很多空值,但经常查询该列上非空记录时应该建立索引
5.经常进行连接查询的列应该创建索引
6. LONG(可变长字符串数据,最长2G)和LONG RAW(可变长二进制数据,最长2G)列不能创建索引
7.通常来说,表的索引越多,其查询的速度也就越快。但是,表的更新速度则会降低。这主要是因为,在更新记录的同时需要更新相关的索引信息。为此,需要在这个更新速度与查询速度之间取得一个均衡点。同时过多的索引会增加物理内存,数据库管理员需要定期去优化索引。
sql中无法使用索引的情况
1.通配符在搜索词首出现时不能用索引:
--下面的方式oracle不适用name索引
select * from student where name like '%wish%';
--如果通配符出现在字符串的其他位置时,优化器能够利用索引;如下:
select * from student where name like 'wish%';
2.不要在查询条件中使用not:
select * from student where not (score=100);
select * from student where score <> 100;
--替换为 select * from student where score>100 or score <100
3. b树索引上使用空值比较将停止使用索引,Oracle的索引不保存全部为空的行:
select * from student where score is not null;
select * from student where score is null;
有一个可以变通的方法,即我们在创建表的时候,为每个列都指定为非空约束(NOT NULL),并且在必要的列上使用default值
