ElasticSearch基础介绍(1)
## 1. Elasticsearch基本介绍
Elasticsearch(简称ES)是一个基于Apache Lucene(TM)的开源搜索引擎,
无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
但是,Lucene只是一个库。想要发挥其强大的作用,你需使用Java并要将其集成到你的应用中。Lucene非常复杂,你需要深入的了解检索相关知识来理解它是如何工作的。
Elasticsearch也是使用Java编写并使用Lucene来建立索引并实现搜索功能,但是它的目的是通过简单连贯的RESTful API让全文搜索变得简单并隐藏Lucene的复杂性。
不过,Elasticsearch不仅仅是Lucene和全文搜索引擎,它还提供:
- 分布式的实时文件存储,每个字段都被索引并可被搜索
- 实时分析的分布式搜索引擎
- 可以扩展到上百台服务器,处理PB级结构化或非结构化数据
1.1 索引结构
下图是ElasticSearch的索引结构,下边黑色部分是物理结构,上边黄色部分是逻辑结构,逻辑结构也是为了更好的去描述ElasticSearch的工作原理及去使用物理结构中的索引文件。

逻辑结构部分是一个倒排索引表:
1、将要搜索的文档内容分词,所有不重复的词组成分词列表。
2、将搜索的文档最终以Document方式存储起来。
3、每个词和docment都有关联。
如下:
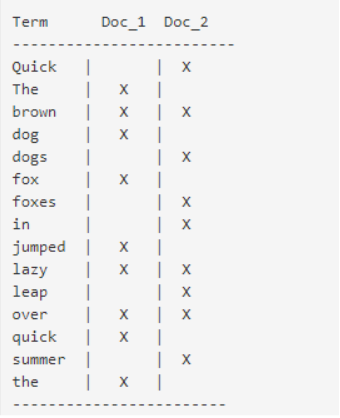
现在,如果我们想搜索quick brown,我们只需要查找包含每个词条的文档:

两个文档都匹配,但是第一个文档比第二个匹配度更高。如果我们使用仅计算匹配词条数量的简单相似性算法,那么,我们可以说,对于我们查询的相关性来讲,第一个文档比第二个文档更佳。
2. Elasticsearch安装与配置
下载地址:https://www.elastic.co/cn/downloads/elasticsearch
我这里安装在Linux下,下载了tar包,解压结构如下:
2.1 配置:
首先我们需要对配置文件进行修改,修改config/elasticsearch.yml配置如下:
# 集群名称
cluster.name: test
# 节点名,通常一台物理服务器就是一个节点,es会默认随机指定一个名字,建议指定一个有意义的名称,方便管理
node.name: test_1
# 允许访问的地址, 0.0.0.0 代表全部
network.host: 0.0.0.0
# 对外开放ip
http.port: 9200
# 集群结点之间通信端口
transport.tcp.port: 9300
# 指定该节点是否有资格被选举成为master结点,默认是true
node.master: true
# 是否是存储节点
node.data: true
# 初始的master节点
cluster.initial_master_nodes: ["test_1"]
# 设置为true可以锁住ES使用的内存,避免内存与swap分区交换数据
bootstrap.memory_lock: false
# 本机不支持SecComp,需要设置为false
bootstrap.system_call_filter: false
# 单机允许的最大存储结点数,通常单机启动一个结点建议设置为1,开发环境如果单机启动多个节点可设置大于1.
node.max_local_storage_nodes: 1
# 数据路径
path.data: /home/app/server/elasticsearch-7.15.1/data
# log路径
path.logs: /home/app/server/elasticsearch-7.15.1/logs
#开启跨域访问
http.cors.enabled: true
http.cors.allow-origin: /.*/
如果需要调节运行的JVM参数,可以修改config/jvm.options文件,例如内存大小:
-Xms1024m
-Xmx1024m
2.2 启动:
启动脚本为 bin/elasticsearch 文件,在命令行执行就可
es为了系统安全,禁止使用root用户运行,如果使用root用户运行,会报如下错误:
org.elasticsearch.bootstrap.StartupException: java.lang.RuntimeException: can not run elasticsearch as root
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:171) ~[elasticsearch-7.15.1.jar:7.15.1]
at org.elasticsearch.bootstrap.Elasticsearch.execute(Elasticsearch.java:158) ~[elasticsearch-7.15.1.jar:7.15.1]
at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:75) ~[elasticsearch-7.15.1.jar:7.15.1]
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:114) ~[elasticsearch-cli-7.15.1.jar:7.15.1]
at org.elasticsearch.cli.Command.main(Command.java:79) ~[elasticsearch-cli-7.15.1.jar:7.15.1]
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:123) ~[elasticsearch-7.15.1.jar:7.15.1]
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:81) ~[elasticsearch-7.15.1.jar:7.15.1]
Caused by: java.lang.RuntimeException: can not run elasticsearch as root
at org.elasticsearch.bootstrap.Bootstrap.initializeNatives(Bootstrap.java:103) ~[elasticsearch-7.15.1.jar:7.15.1]
at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:170) ~[elasticsearch-7.15.1.jar:7.15.1]
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:399) ~[elasticsearch-7.15.1.jar:7.15.1]
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:167) ~[elasticsearch-7.15.1.jar:7.15.1]
... 6 more
uncaught exception in thread [main]
java.lang.RuntimeException: can not run elasticsearch as root
at org.elasticsearch.bootstrap.Bootstrap.initializeNatives(Bootstrap.java:103)
at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:170)
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:399)
at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:167)
at org.elasticsearch.bootstrap.Elasticsearch.execute(Elasticsearch.java:158)
at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:75)
at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:114)
at org.elasticsearch.cli.Command.main(Command.java:79)
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:123)
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:81)
For complete error details, refer to the log at /home/app/server/elasticsearch-7.15.1/logs/test.log
可以自建一个普通用户,并授权此es目录的访问权限,并切换到此用户,再执行
正常情况此时就可以启动成功, 没有错误日志, 访问127.0.0.1:9200,即可看到如下信息:
{
"name" : "test_1",
"cluster_name" : "test",
"cluster_uuid" : "7KnzF-4MTuSCC37tMUvF0A",
"version" : {
"number" : "7.15.1",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "83c34f456ae29d60e94d886e455e6a3409bba9ed",
"build_date" : "2021-10-07T21:56:19.031608185Z",
"build_snapshot" : false,
"lucene_version" : "8.9.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
但是,也有可能会出现错误,导致运行失败,例如下:
ERROR: [2] bootstrap checks failed. You must address the points described in the following [2] lines before starting Elasticsearch.
bootstrap check failure [1] of [2]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]
bootstrap check failure [2] of [2]: max number of threads [1024] for user [xjw] is too low, increase to at least [4096]
我这里显示为,需要调整linux系统的最大文件句柄数和用户的线程数, 可以使用ulimit -a 查看:
[xjw@localhost bin]$ ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 31831
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 65535
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 10240
cpu time (seconds, -t) unlimited
max user processes (-u) 1024
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
对应调整一下参数即可,网上有很多解决方法,. 如果出现其他错误,也一样
2.3 head插件安装
head插件是ES的一个简单可视化管理插件,用来监视ES的状态,并通过head客户端和ES服务进行交互,比如创建映射、创建索引等,head的项目地址在https://github.com/mobz/elasticsearch-head , 此项目是个前端项目,安装需要下载node.js,可以自行安装,
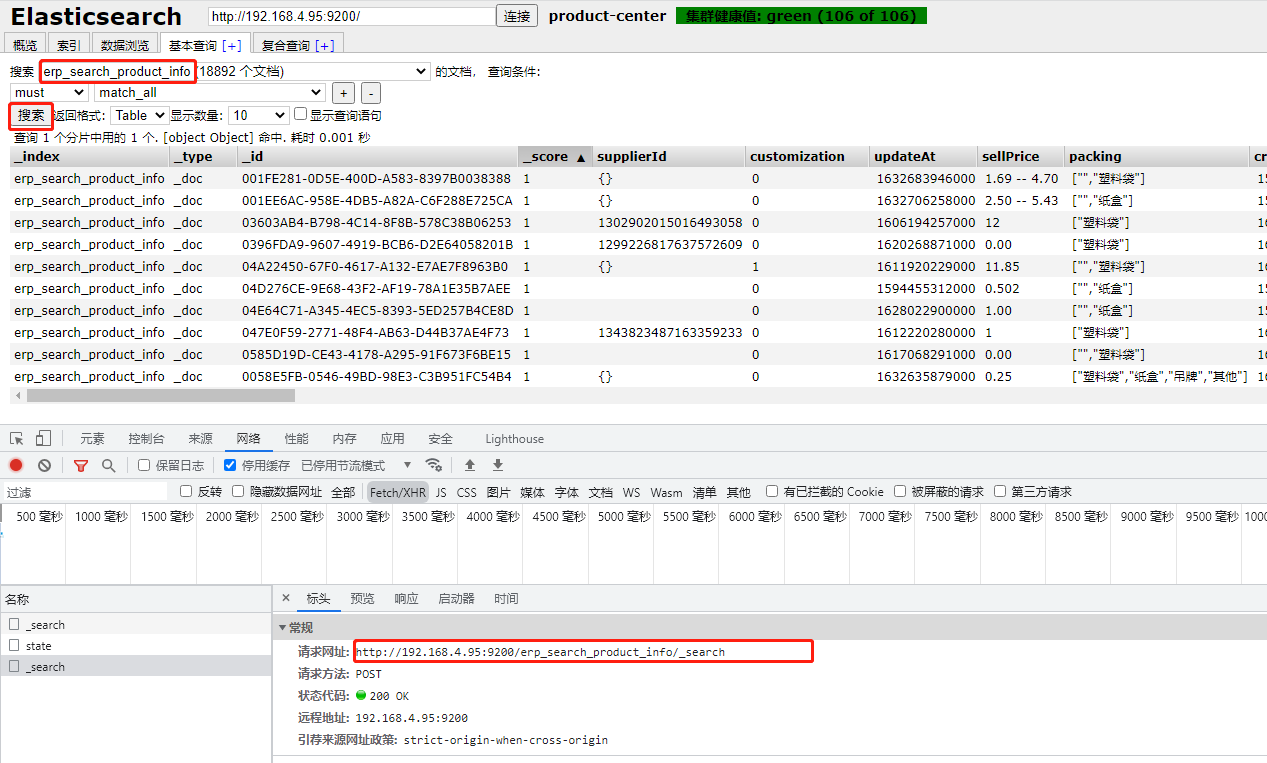
它的访问方式主要就是自动封装对Es操作的HTTP请求:
例如: 当使用此工具进行搜索匹配时, 访问的接口就是,9200 端口服务的地址,
请求参数也是普通的请求参数:
{
"query": {
"bool": {
"must": [{
"match_all": {}
}],
"must_not": [],
"should": []
}
},
"from": 0,
"size": 10,
"sort": [],
"aggs": {}
}
2.4 安装kibana
Elasticsearch 是 对Lucene 的封装,并对外提供http接口,
而kibana,则对 Elasticsearch 数据进行可视化,并让你在 Elastic Stack 中进行导航。您可以进行各种操作,从跟踪查询负载, 是Elasticsearch 的配套产品
这里我主要把kibana作为操作ES 的客户端,
安装地址:https://www.elastic.co/downloads/kibana, 下载和ES对应的版本
解压目录:
如果Kibana和ES在同一系统下,则无需任何配置, 直接启动即可,启动脚本:bin/kibana ,同样需要使用自建用户启动, 默认自动连接ES地址:127.0.0.1:9200, 启动成功,访问地址:127.0.0.1:5601
同样,我们也可以修改config/kibana.yml文件进行修改配置:
#服务的端口配置,默认5601
server.port: 5601
# ES地址,默认[ "http://localhost:9200" ],必须是同一集群下的
elasticsearch.hosts: [ "http://localhost:9200" ]
#es用户名密码
elasticsearch.username: user
elasticsearch.password: password
3. es的相关概念
Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档,用JSON作为文档序列化的格式,比如下面这条用户数据:
{
"name" : "jack",
"sex" : "Male",
"age" : 25,
"birthDate": "1990/05/01",
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
Elasticsearch可以看成是一个数据库,只是和关系型数据库比起来数据格式和功能不一样而已
1.1 索引index
文档存储的地方,类似于MySQL数据库中的数据库概念
1.2 类型 type
如果按照关系型数据库中的对应关系,还应该有表的概念。ES中没有表的概念,这是ES和数据库的一个区别,在我们建立索引之后,可以直接往 索引 中写入文档。
在6.0版本之前,ES中有Type的概念,可以理解成关系型数据库中的表,但是官方说这是一个设计上的失误,所以在6.0版本之后Type就被废弃了。
1.3 字段Field
相当于是数据表的字段,字段在ES中可以理解为JSON数据的键,下面的JSON数据中,name 就是一个字段。
{
"name":"jack"
}
1.4 映射 mapping
映射 是对文档中每个字段的类型进行定义,每一种数据类型都有对应的使用场景。
每个文档都有映射,我们可以手动指定某个索引的映射.
也可以不需要显示的创建映射,因为ES中实现了动态映射。
我们在索引中写入一个下面的JSON文档,在动态映射的作用下,name会映射成text类型,age会映射成long类型。
{
"name":"jack",
"age":18,
}
自动判断的规则如下:

1.4.1 text类型
analyzer属性
通过analyzer属性指定分词器。
下边指定name的字段类型为text,使用ik分词器的ik_max_word分词模式。
"name": {
"type": "text",
"analyzer":"ik_max_word"
}
index属性
通过index属性指定是否索引。
默认为index=true,即要进行索引,只有进行索引才可以从索引库搜索到。(只存储,不作为搜索条件)
但是也有一些内容不需要索引,比如:商品图片地址只被用来展示图片,不进行搜索图片,此时可以将index设置为false。
store属性
是否在source之外存储,每个文档索引后会在 ES中保存一份原始文档,存放在"_source"中,一般情况下不需要设置store为true,因为在_source中已经有一份原始文档了。
1.4.2 keyword类型
上边介绍的 text文本字段在映射时要设置分词器(不设置有默认的英文分词器),keyword字段为关键字字段,通常搜索keyword是按照整体搜索,所以创建keyword字段的索引时是不进行分词的,比如:邮政编码、手机号码、身份证等。keyword字段通常用于过虑、排序、聚合等。
1.4.3 date日期类型
日期类型不用设置分词器。
通常日期类型的字段用于排序。
通过format设置日期格式。
例子:
下边的设置允许date字段存储年月日时分秒、年月日及毫秒三种格式。
{
"properties": {
"timestamp": {
"type": "date",
"format": "yyyy‐MM‐ddHH:mm:ss||yyyy‐MM‐dd"
}
}
}
1.4.4 数值类型
下边是ES支持的数值类型
| 类型 | 范围 |
|---|---|
long |
一个有符号的 64 位整数,最小值为: -2^63, 最大值为: 2^63 - 1 |
integer |
一个有符号的 32 位整数,最小值为: -2^31最大值为: 2^31 - 1 |
short |
一个有符号的 16 位整数,最小值为-32,768,最大值为32,767。 |
byte |
一个有符号的 8 位整数,最小值为-128,最大值为127。 |
double |
双精度 64 位 IEEE 754 浮点数 |
float |
单精度 32 位 IEEE 754 浮点数 |
half_float |
半精度 16 位 IEEE 754 浮点数 |
scaled_float |
带有缩放因子的缩放类型浮点数 |
unsigned_long |
一个无符号的 64 位整数,最小值为 0,最大值为。 2^64 - 1 |
尽量选择范围小的类型,提高搜索效率
1.5 文档 document
文档在ES中相当于传统数据库中的行的概念,ES中的数据都以JSON的形式来表示,在MySQL中插入一行数据和ES中插入一个JSON文档是一个意思。下面的JSON数据表示,一个包含3个字段的文档。
{
"name":"jack",
"age":18,
"gender":1
}
一个文档不只有数据。它还包含了元数据(metadata)——关于文档的信息。三个必须的元数据节点是:
| 节点 | 说明 |
|---|---|
| _index | 文档存储的地方 |
| _type | 文档代表的对象的类 |
| _id | 文档的唯一标识 |
4. ElasticSearch的客户端基本操作
因为ElasticSearch 对外开发HTTP, 所以在开发中,主要有四种方式可以作为elasticsearch服务的客户端:
- 第一种,elasticsearch-head插件
- 第二种,使用elasticsearch提供的Restful接口直接访问
- 第三种,使用Kibana提供的工具进行访问
- 第四种,使用例如Java提供的API进行访问
下面我们使用第二种方式进行简单的操作演示,后续全部使用简单的Kibana访问方式
2.1. 索引操作
索引创建:
向 ES 服务器发 PUT 请求 : http://127.0.0.1:9200/course , 创建名为course的索引
响应:
{
"acknowledged": true,//响应结果
"shards_acknowledged": true,//分片结果
"index": "course"//索引名称
}
重复发送,返回错误信息,索引存在
{
"error": {
"root_cause": [
{
"type": "resource_already_exists_exception",
"reason": "index [course/J0WlEhh4R7aDrfIc3AkwWQ] already exists",
"index_uuid": "J0WlEhh4R7aDrfIc3AkwWQ",
"index": "course"
}
],
"type": "resource_already_exists_exception",
"reason": "index [course/J0WlEhh4R7aDrfIc3AkwWQ] already exists",
"index_uuid": "J0WlEhh4R7aDrfIc3AkwWQ",
"index": "course"
},
"status": 400
}
查看索引:
ES 服务器发 GET 请求 : http://127.0.0.1:9200/_cat/indices?v
这里请求路径中的_cat 表示查看的意思,indices 表示索引,所以整体含义就是查看当前 ES 服务器中的所有索引,就好像 MySQL 中的 show tables 的感觉,服务器响应结果如下
响应结果如下:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open course J0WlEhh4R7aDrfIc3AkwWQ 1 1 0 0 208b 208b
每个字段的含义:
| 表头 | 含义 |
|---|---|
| health | 当前服务器健康状态: green(集群完整) yellow(单点正常、集群不完整) red(单点不正常) |
| status | 索引打开、关闭状态 |
| index | 索引名 |
| uuid | 索引统一编号 |
| pri | 主分片数量 |
| rep | 副本数量 |
| docs.count | 可用文档数量 |
| docs.deleted | 文档删除状态(逻辑删除) |
| store.size | 主分片和副分片整体占空间大小 |
| pri.store.size | 主分片占空间大小 |
查看单个索引
在 Postman 中,向 ES 服务器发 GET 请求 : http://127.0.0.1:9200/course
响应结果如下:
{
"course": {//索引名
"aliases": {},//别名
"mappings": {},//映射
"settings": {//设置
"index": {//设置 - 索引
"creation_date": "1617861426847",//设置 - 索引 - 创建时间
"number_of_shards": "1",//设置 - 索引 - 主分片数量
"number_of_replicas": "1",//设置 - 索引 - 主分片数量
"uuid": "J0WlEhh4R7aDrfIc3AkwWQ",//设置 - 索引 - 主分片数量
"version": {//设置 - 索引 - 主分片数量
"created": "7080099"
},
"provided_name": "course"//设置 - 索引 - 主分片数量
}
}
}
}
删除索引
在 Postman 中,向 ES 服务器发 DELETE 请求 : http://127.0.0.1:9200/course
返回结果如下:
{
"acknowledged": true
}
2.2 映射操作
我们要把课程信息存储到ES中,这里我们创建课程信息的映射,先来一个简单的映射,如下:
创建映射
发送:post http://localhost:9200/索引库名称/类型名称/_mapping
post 请求:http://localhost:9200/course/_mapping
请求参数:
{
"properties": {
"name": {
"type": "text"
},
"description": {
"type": "text"
},
"studymodel": {
"type": "keyword"
}
}
}
查询所有索引的映射:
GET: http://localhost:9200/_mapping
更新映射
映射创建成功可以添加新字段,已有字段不允许更新。
删除映射
通过删除索引来删除映射。
2.3 文档操作
ES中的文档相当于MySQL数据库表中的记录。
创建文档
向 ES 服务器发 POST 请求 : http://127.0.0.1:9200/course/_doc,请求体JSON内容为
{
"name": "Bootstrap开发框架",
"description": "Bootstrap是由Twitter推出的一个前台页面开发框架,在行业之中使用较为广泛。此开发框架包含了大量的CSS、 JS程序代码, 可以帮助开发者( 尤其是不擅长页面开发的程序人员) 轻松的实现一个不受浏览器限制的精美界面效果",
"studymodel": "201001"
}
注意,此处发送请求的方式必须为 POST,不能是 PUT,否则会发生错误 。
返回结果:
{
"_index": "course",//索引
"_type": "_doc",//类型-文档
"_id": "ANQqsHgBaKNfVnMbhZYU",//唯一标识,可以类比为 MySQL 中的主键,随机生成
"_version": 1,//版本
"result": "created",//结果,这里的 create 表示创建成功
"_shards": {//
"total": 2,//分片 - 总数
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
上面的数据创建后,由于没有指定数据唯一性标识(ID),默认情况下, ES 服务器会随机生成一个。
如果想要自定义唯一性标识,需要在创建时指定: http://127.0.0.1:9200/course/_doc/1
返回结果如下:
{
"_index": "course",
"_type": "_doc",
"_id": "1",//<------------------自定义唯一性标识
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
此处需要注意:如果增加数据时明确数据主键,那么请求方式也可以为 PUT。
根据id查询
GET http://127.0.0.1:9200/course/_doc/1 1则为id号
查看索引下所有数据
向 ES 服务器发 GET 请求 : http://127.0.0.1:9200/course/_search
根据条件查询
向 ES 服务器发 GET 请求 : http://127.0.0.1:9200/course/_search
请求体:
{
'query':{
'terms':{
'name':"Bootstrap开发框架"
}
}
}
以上代表精确查询name为Bootstrap开发框架 字串的数据
分析上边查询的结果json:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.2876821,
"hits": [{
"_index": "test",
"_type": "doc",
"_id": "4028e58161bcf7f40161bcf8b77c0000",
"_score": 0.2876821,
"_source": {
"name": "Bootstrap开发框架",
"description": "Bootstrap是由Twitter推出的一个前台页面开发框架,在行业之中使用较为广泛。 此开发框架包含了大量的CSS、 JS程序代码, 可以帮助开发者( 尤其是不擅长页面开发的程序人员) 轻松的实现一个不受浏览器限制的精美界面效果 ",
"studymodel": "201001"
}
}]
}
}
took:本次操作花费的时间,单位为毫秒。
timed_out:请求是否超时
_shards:说明本次操作共搜索了哪些分片
hits:搜索命中的记录
hits.total : 符合条件的文档总数
hits.hits :匹配度较高的前N个文档
hits.max_score:文档匹配得分,这里为最高分
_score:每个文档都有一个匹配度得分,按照降序排列。
_source:显示了文档的原始内容。
修改字段
和新增文档一样,输入相同的 URL 地址请求,如果请求体变化,会将原有的数据内容覆盖
在 Postman 中,向 ES 服务器发 POST 请求 : http://127.0.0.1:9200/course/_doc/1
请求体JSON内容为:
{
"name": "Bootstrap开发框架_修改",
"description": "Bootstrap是由Twitter推出的一个前台页面开发框架,在行业之中使用较为广泛。 此开发框架包含了大量的CSS、 JS程序代码, 可以帮助开发者( 尤其是不擅长页面开发的程序人员) 轻松的实现一个不受浏览器限制的精美界面效果_修改",
"studymodel": "201001_修改"
}
修改成功后,服务器响应结果:
{
"_index": "course",
"_type": "_doc",
"_id": "1",
"_version": 2,
"result": "updated",//<-----------updated 表示数据被更新
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 2,
"_primary_term": 1
}
局部修改:
修改数据时,也可以只修改某一给条数据的局部信息
在 Postman 中,向 ES 服务器发 POST 请求 : http://127.0.0.1:9200/course/_update/1。
请求体JSON内容为:
{
"doc": {
"name": "Bootstrap开发框架_局部修改"
}
}
删除
删除一个文档不会立即从磁盘上移除,它只是被标记成已删除(逻辑删除)。
在 Postman 中,向 ES 服务器发 DELETE 请求 : http://127.0.0.1:9200/course/_doc/1
5. 安装IK分词器
前文说到,es中的搜索模式为倒排索引, 所以每个索引库都对应着其每个的词库,这些词库产生于元数据,并和原文关联,
所以在添加文档时会进行分词,索引中存放的就是一个一个的词(term),当你去搜索时就是拿关键字去匹配词,最终找到词关联的文档。
测试当前索引库使用的默认分词器:
post 发送:localhost:9200/_analyze
json请求体:
{"text":"测试分词器,后边是测试内容:spring cloud实战"}
结果如下:
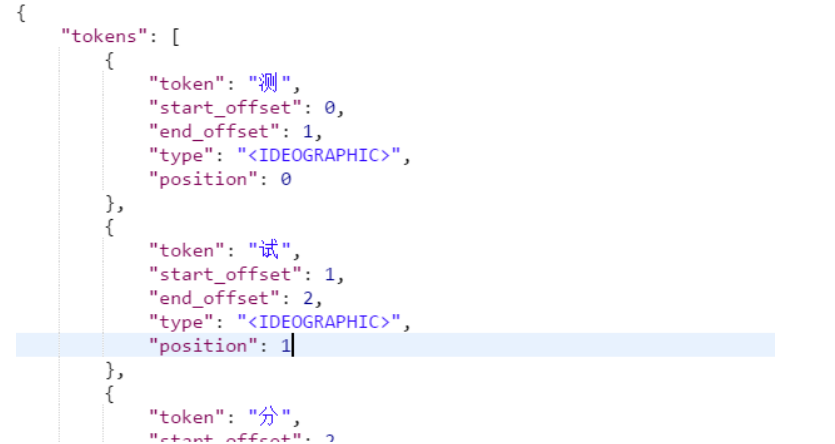
会发现分词的效果将 “测试” 这个词拆分成两个单字“测”和“试”这是因为当前索引库使用的分词器对中文就是单字分词。默认对英文可以根据空格分词,
如果不作处理,则此字段中,在索引词库中存放的就是单个字, 用户无法根据词语进行搜索关联到,只能根据 测``试 等单个字进行搜索, 若使用测试 或者内容 等这种有实际意义的词,是搜索不到的,所以我们需要下载一个插件.来支持中文的分词
安装IK分词器
使用IK分词器可以实现对中文分词的效果。
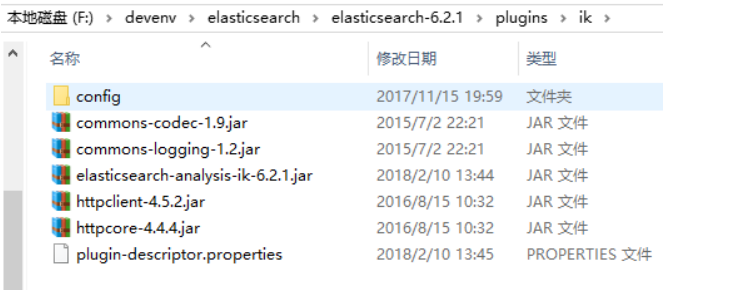
下载IK分词器:(Github地址:https://github.com/medcl/elasticsearch-analysis-ik) 下载zip:
解压,并将解压的文件拷贝到ES安装目录的plugins下的ik目录下
测试分词效果:
发送:post localhost:9200/_analyze , 并指定分词器
{"text":"测试分词器,后边是测试内容:spring cloud实战","analyzer":"ik_max_word" }
结果:

两种分词模式
ik分词器有两种分词模式:ik_max_word和ik_smart模式。
1、ik_max_word 会将文本做最细粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为“中华人民共和国、中华人民、中华、 华人、人民共和国、人民、共和国、大会堂、大会、会堂等词语。
2、ik_smart 会做最粗粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为中华人民共和国、人民大会堂。
自定义词库
如果要让分词器支持一些专有词语,可以自定义词库。
iK分词器自带一个main.dic的文件,此文件为词库文件。
在上边的目录中新建一个my.dic文件(注意文件格式为utf-8(不要选择utf-8 BOM))
可以在其中自定义词汇: 比如定义: 配置文件中配置my.dic,

重启ES,测试分词效果:
发送:post localhost:9200/_analyze
{"text":"测试分词器,后边是测试内容:spring cloud实战","analyzer":"ik_max_word" }

一个并没有任何实际意义的词,这次就被作为一个完整的词语分割出来了
