Redis项目常见解决方案
## 1. 缓存预热
在项目启动,或者服务器重启后, 因为请求量较大,
此时对关系型数据库的访问量就有可能超标,导致服务卡顿,宕机,
所以在启动前应该对缓存进行预热:
前置准备工作:
- 日常例行统计数据访问记录,统计访问频度较高的热点数据
- 利用LRU数据删除策略(最少被使用策略),构建数据留存队列 ,例如:storm与kafka配合
准备工作:
- 将统计结果中的数据分类,根据级别,redis优先加载级别较高的热点数据
- 利用分布式多服务器同时进行数据读取,提速数据加载过程
- 热点数据主从同时预热
实施:
- 使用脚本程序固定触发数据预热过程
- 如果条件允许,使用了CDN(内容分发网络),效果会更好
总结:缓存预热就是系统启动前,提前将相关的缓存数据直接加载到缓存系统。避免在用户请求的时候,先查询数据库,然后再将数据缓 存的问题!用户直接查询事先被预热的缓存数据!
2. 缓存雪崩
问题所在:
在一个较短的时间内,缓存中较多的key集中过期 ,此周期内请求访问过期的数据,redis未命中,redis向数据库获取数据 ,数据库同时接收到大量的请求无法及时处理 ,
数据库流量激增,导致数据库崩溃 ,级联导致整个引用服务不可用
解决思路
- 构建多级缓存架构 例如: Nginx缓存+redis缓存+ehcache缓存
- 检测Mysql严重耗时业务进行优化 对数据库的瓶颈排查:例如超时查询、耗时较高事务等
- 灾难预警机制 监控redis服务器性能指标
- CPU占用、CPU使用率
- 内存容量
- 查询平均响应时间
- 线程数
- 限流、降级 短时间范围内牺牲一些客户体验,限制一部分请求访问,降低应用服务器压力,待业务低速运转后再逐步放开访问
具体解决方法:
- LRU(最近最久使用的数据)与LFU切换 (最近最少使用的数据)
- 数据有效期策略调整
- 根据业务数据有效期进行分类错峰,A类90分钟,B类80分钟,C类70分钟
- 过期时间使用固定时间+随机值的形式,稀释集中到期的key的数量
- 超热数据使用永久key
- 定期维护(自动+人工) :对即将过期数据做访问量分析,确认是否延时,配合访问量统计,做热点数据的延时 ,如果此时访问量非常大,则此key可以延迟过期
- 加锁 慎用!
总结:
缓存雪崩就是瞬间过期数据量太大,导致对数据库服务器造成压力。如能够有效避免过期时间集中,可以有效解决雪崩现象的出现 (约40%),配合其他策略一起使用,并监控服务器的运行数据,根据运行记录做快速调整。
3. 缓存击穿
问题所在:
Redis在某一时刻中某个key过期,并且该key访问量巨大 ,但是此时 有大量的请求从服务器直接压到Redis后,均未命中,那么此时这些大量的请求都被压到了数据库, 而数据量又是非常强大, 同样可能导致数据库的崩溃
解决方案
-
预先设定 :以电商为例,每个商家根据店铺等级,指定若干款主打商品,在购物节期间,加大此类信息key的过期时长
-
现场调整 : 监控访问量,对突然流量激增的数据延长过期时间或设置为永久性key
-
后台刷新数据: 启动定时任务,高峰期来临之前,刷新数据有效期,确保不丢失
-
二级缓存: 设置不同的失效时间,保障不会被同时淘汰就行
-
加锁: 分布式锁,防止被击穿,但是要注意也是性能瓶颈,慎重!
总结
缓存击穿就是单个高热数据过期的瞬间,数据访问量较大,未命中redis后,发起了大量对同一数据的数据库访问,导致对数据库服 务器造成压力。应对策略应该在业务数据分析与预防方面进行,配合运行监控测试与即时调整策略,毕竟单个key的过期监控难度 较高,配合雪崩处理策略即可。
4. 缓存穿透
问题所在:
由于出现大量非正常URL访问 ,例如黑客攻击等, 例如URL中通过指定id号,查询文章,对于正常访问的URL,这些ID都可以在Redis中获取,避免访问数据库, 那么如果当ID不存在时, 服务就试图从数据库中获取,对数据库进行访问,
那么如果访问量过大,同样将导致数据库服务崩溃
解决方案:
-
缓存null: 对查询结果为null的数据进行缓存(长期使用,定期清理),设定短时限,例如30-60秒,最高5分钟
-
白名单策略
- 提前对所有合法的数据id设置 对应的bitmaps,id作为bitmaps的offset,相当于设置了数据白名单。当加载正常数据时,放行,加载异常数据时直接拦截(效率偏低)
- 使用布隆过滤器(有关布隆过滤器的命中问题对当前状况可以忽略)
-
实施监控
实时监控redis命中率(业务正常范围时,通常会有一个波动值)与null数据的占比
- 非活动时段波动:通常检测3-5倍,超过5倍纳入重点排查对象
- 活动时段波动:通常检测10-50倍,超过50倍纳入重点排查对象
根据倍数不同,启动不同的排查流程。然后使用黑名单进行防控(运营)
-
key加密
问题出现后,临时启动防灾业务key,对key进行业务层传输加密服务,设定校验程序,过来的key校验 例如每天随机分配60个加密串,挑选2到3个,混淆到页面数据id中,发现访问key不满足规则,驳回数据访问
总结:
缓存击穿访问了不存在的数据,跳过了合法数据的redis数据缓存阶段,每次访问数据库,导致对数据库服务器造成压力。通常此类 数据的出现量是一个较低的值,当出现此类情况以毒攻毒,并及时报警。应对策略应该在临时预案防范方面多做文章。 无论是黑名单还是白名单,都是对整体系统的压力,警报解除后尽快移除。
5.监控性能指标
对于Redis的性能关注点,共可分成如下五个分类
- 性能指标:Performance
- 内存指标:Memory
- 基本活动指标:Basic activity
- 持久性指标:Persistence
- 错误指标:Error
性能指标:Performance
| 名 | 描述 |
|---|---|
| latency | Redis响应一个请求的时间 |
| instantaneous_ops_per_sec | 平均每秒处理请求总数 |
| hit rate(calculated) | 缓存命中率(计算得出) |
内存指标:Memory
| 名 | 描述 |
|---|---|
| used_memory | 已使用内存 |
| mem_fragmentation_ratio | 内存碎片率 |
| evicted_keys | 由于最大内存限制被移除的key的数量 |
| blocked_clients | 由于BLPOP,BRPOP,or BRPOPLPUSH而被阻塞的客户端 |
基本活动指标:Basic activity
| 名 | 描述 |
|---|---|
| connected_clients | 客户端连接数 |
| connected_slaves | Slave数量 |
| master_last_io_seconds_ago | 最近一次主从交互之后的秒数 |
| keyspace | 数据库中的key值总数 |
持久性指标:Persistence
| 名 | 描述 |
|---|---|
| rdb_last_save_time | 最后一次持久化保存到磁盘的时间戳 |
| rdb_changes_since_last_save | 自最后一次持久化以来数据库的更改数 |
错误指标:Error
| 名 | 描述 |
|---|---|
| rejected_connections | 由于达到maxclient限制而被拒绝的连接数 |
| keyspace_misses | Key 值查找失败(未命中) |
| master_link_down_since_seconds | 主从断开的持续时间 |
监控方式
工具介绍
- Cloud Insight Redis
- Prometheus
- Redis-stat
- Redis-faina
- RedisLive
- zabbix
命令
- benchmark
- redis cli
- monitor
- showlog
常用命令:
-
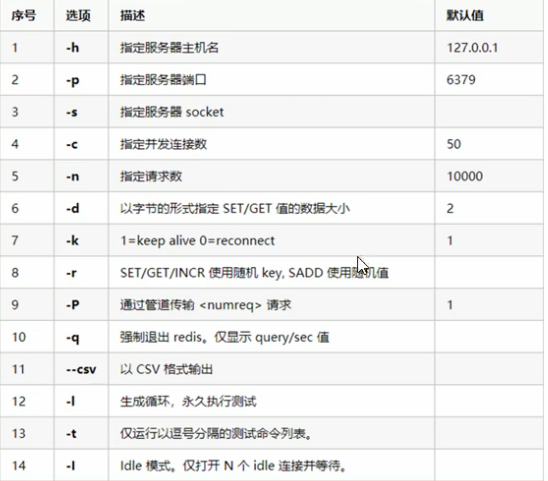
benchmark(Redis服务的一个指令,而非redis-cli操作Redis的命令)
格式:
redis-benchmark [-h ] [-p ] [-c ] [-n [-k ]范例1 :
redis-benchmark50个连接,10000次请求对应的性能范例2:
redis-benchmark -c 100 -n 500050个连接,10000次请求对应的性能具体参数如下
-
monitor
打印服务器调试信息 ,内部执行情况,例如节点之间ping命令的发送情况
-
showlong
慢查询日志查询
格式
showlong [operator]- get :获取慢查询日志
- len :获取慢查询日志条目数
- reset :重置慢查询日志
需要打开慢查询配置
slowlog-log-slower-than 1000 //设置慢查询的时间下限,单位:微妙 slowlog-max-len 100 //设置慢查询命令对应的日志显示长度,单位:命令数

